

In recent months, we’ve heard a lot about deep neural networks and deep learning—take Project Adam, for example—and the sometimes eye-popping results they can have in addressing longstanding computing problems.
The field of image recognition also is benefiting rapidly from the use of such networks, along with the availability of prodigious data sets. In this case, such networks are called “deep convolutional neural networks” (CNNs), which are inspired by biological processes of the human brain.
Existing CNNs have a problem, though: The algorithms are too slow for object detection in practice. The networks previously were applied thousands of times on a single image, just for detecting a few objects.
Microsoft researchers have discovered a solution to this vexing computer-vision issue, though, one that will receive prominent mention in Beijing on Oct. 29 during the 16th annual Computing in the 21st Century Conference, an academic event founded and organized by Microsoft Research Asia (opens in new tab).

Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Kaiming He
The new solution speeds the deep-learning object-detection system by as many as 100 times, yet has outstanding accuracy. The advance is outlined in Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition (opens in new tab), a research paper written by Kaiming He (opens in new tab) and Jian Sun (opens in new tab), along with a couple of academics serving internships at the Asia lab: Xiangyu Zhang of Xi’an Jiaotong University and Shaoqing Ren of the University of Science and Technology of China.
“Image recognition involves two core tasks: image classification and object detection,” He explains. “In image classification, the computer is taught to recognize object categories, such as “person,” “cat,” “dog,” or “bike,” while in object detection, the computer needs to provide the precise positions of the objects in the image.”
The second task, Sun adds, is the more difficult of the two.
“We need,” he says, “to answer ‘what and where’ for one or more objects in an image.”
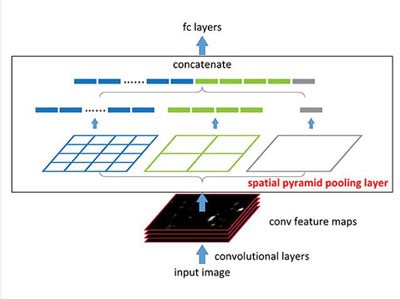
A diagram of where the spatial pyramid pooling layer fits into the network stack.
The aforementioned paper introduces a powerful new network structure that uses “spatial pyramid pooling” (SPP)—a technique that can generate a descriptor from a region of any size.
As the paper makes clear, information aggregation is achieved deeper in the network. With the new technique, the network is only computed once on the image but still can produce descriptors for thousands of regions. These descriptors are used to detect objects quickly.
CNNs, like other deep neural networks, are designed to mimic the structure of the human brain. The researchers’ approach of aggregating the visual information at a deeper stage, they contend, conforms more with the hierarchical information processing that occurs in the brain.
The paper that outlines their approach states:
“When an object comes into our field of view, it is more reasonable that our brains consider it as a whole instead of cropping it into several ‘views’ at the beginning. Similarly, it is unlikely that our brains distort all object candidates into fixed-size regions for detecting/locating them. It is more likely that our brains handle arbitrarily shaped objects at some deeper layers by aggregating the already deeply processed information from the previous layers.”
The SPP paper aims to give networks a more principled pooling strategy. As it turns out, SPPs have properties that can transform CNNs. For one thing, spatial pyramid pooling uses a new pooling method to generate a fixed-size output regardless of the size of the input image, something that previous deep-learning research efforts couldn’t do.
“Think of an image as a canvas,” He says in explaining the pooling concept. “We may want to use small pieces of square paper to cover the entire canvas. When we are given another canvas of a different size, we may need a different number of pieces of square paper.
“The ‘spatial pyramid pooling’ always uses the same number of pieces of paper to cover the canvas. To do so, we need to adjust the paper size according to the canvas size.”

Jian Sun
Because of this flexibility of sizes, SPP can pool features extracted from any regions without repeatedly computing the convolutional networks. This property leads to a significantly faster object-detection system.
How much? The new technique is 20 to 100 times faster than the previous leading solutions for object detection. The Microsoft researchers’ solution is the only real-time CNN detection system among the 38 teams participating in the ImageNet Large Scale Visual Recognition Challenge 2014 (opens in new tab), which evaluates algorithms for object detection and image classification. The system also has top-notch accuracy, ranking second in detection and third in classification in the competition.
Clearly, the SPP research has demonstrated the sort of progress that warrants further exploration.
“Though the current deep-learning models are breakthroughs over traditional methods, they are far from human performance, typically for the challenging detection task,” He says. “We will continuously improve the quality of our methods.”
The ability to access ever-larger data sets will help advance the research.
“One of the important next steps,” Sun says, “is to obtain much larger and richer training data. That will significantly impact the research in this direction.”
That said, it’s hard for He to disguise his pride in what he and his colleagues have achieved.
“Our work is the fastest deep-learning system for accurate object detection,” he says. “The speed is getting very close to the requirement for consumer usage.”


