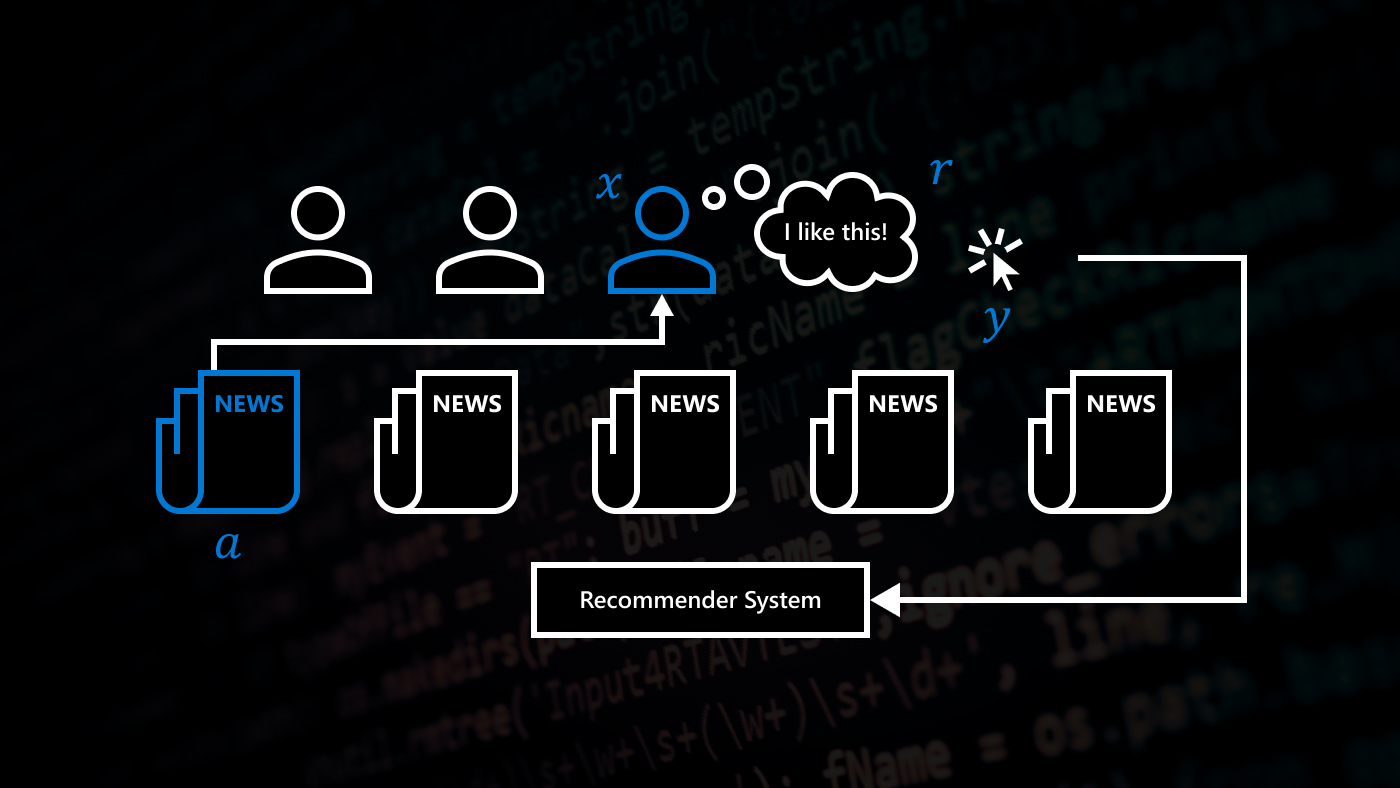
As human beings, we encounter unfamiliar situations all the time—learning to drive, living on our own for the first time, starting a new job. And while we can anticipate what to expect based on what others have told us or what we’ve picked up from books and depictions in movies and TV, it isn’t until we’re behind the wheel of a car, maintaining an apartment, or doing a job in a workplace that we’re able to take advantage of one of the most important means of learning: by trying. We make deliberate decisions, see how they pan out, then make more choices and take note of those results, becoming—we hope—better drivers, renters and workers in the process. We learn by interacting with our environments.
“Humans have an intuitive understanding of physics, and it’s because when we’re kids, we push things off of tables and stuff like that,” says Principal Researcher Akshay Krishnamurthy. “But if you only watch videos of things falling off tables, you will not actually know about this intuitive gravity business. So our ability to do experimentation in the world is very, very important for us to generalize.”
For our AI to improve in the world in which we operate, it would stand to reason that our technology be able to do the same. To learn not just from the data it’s been given, as has largely been the approach in machine learning, but to also learn to figure out what additional data it needs to get better.
“We want AIs to make decisions, and reinforcement learning is the study of how to make decisions,” says Krishnamurthy.
-
 EVENT
Microsoft at NeurIPS 2020
EVENT
Microsoft at NeurIPS 2020
Check out Microsoft at NeurIPS 2020, including all of our NeurIPS publications, the Microsoft session schedule, and open career opportunities
Krishnamurthy is a member of the reinforcement learning group at the Microsoft Research lab in New York City, one of several teams helping to steer the course of reinforcement learning at Microsoft. There are also dedicated groups in Redmond, Washington; Montreal; Cambridge, United Kingdom; and Asia; and they’re working toward a collective goal: RL for the real world (opens in new tab). They’ve seen their efforts pay off. The teams have translated foundational research into the award-winning Azure Personalizer (opens in new tab), a reinforcement learning system that helps customers build applications that become increasingly customized to the user, which has been successfully deployed in many Microsoft products, such as Xbox.
While reinforcement learning has been around almost as long as machine learning, there’s still much to explore and understand to support long-term progress with real-world implications and wide applicability, as underscored by the 17 RL-related papers being presented by Microsoft researchers at the 34th Conference on Neural Information Processing Systems (NeurIPS 2020). Here, we explore a selection of the work through the lens of three areas:
- Batch RL, a framework in which agents leverage past experiences, which is a vital capability for real-world applications, particularly in safety-critical scenarios
- Strategic exploration, mechanisms by which algorithms identify and collect relevant information, which is crucial for successfully optimizing performance
- Representation learning, through which agents summarize and compress inputs to enable more effective exploration, generalization, and optimization
Batch RL: Using a static dataset to learn a policy
In traditional RL problems, agents learn on the job. They’re introduced into an environment, act in that environment, and note the outcomes, learning which behaviors get them closer to completing their task. Batch RL takes a different approach: an agent tries to learn a good policy from a static dataset of past experiences, collected—for example—in the regular operation of an existing system in which it will be deployed. While it’s less intuitive than the direct trial-and-error nature of interactive RL, says Principal Research Manager Alekh Agarwal, this framework has some crucial upsides.
“You can take advantage of any and every available ounce of data that relates to your problem before your agent ever sees the light of day, and that means they can already start at a much higher performance point; they make fewer errors and generally learn much better,” says Agarwal. This is especially important in safety-critical scenarios such as healthcare and autonomous systems.
The papers “Provably Good Batch Reinforcement Learning Without Great Exploration” and “MOReL: Model-Based Offline Reinforcement Learning” tackle the same batch RL challenge. Static datasets can’t possibly cover every situation an agent will encounter in deployment, potentially leading to an agent that performs well on observed data and poorly on unobserved data. This can make an agent susceptible to “cascading failures,” in which one wrong move leads to a series of other decisions that completely derails the agent. Oftentimes, researchers won’t know until after deployment how effective a dataset was, explains Agarwal.
The papers seek to optimize with the available dataset by preparing for the worst. While showing optimism in the face of uncertainty—that is, treating even wrong moves as learning opportunities—may work well when an agent can interact with its environment, batch RL doesn’t afford an agent a chance to test its beliefs; it only has access to the dataset. So instead, researchers take a pessimistic approach, learning a policy based on the worst-case scenarios in the hypothetical world that could have produced the dataset they’re working with. Performing well under the worst conditions helps ensure even better performance in deployment. So there are two questions at play, Agarwal says: how do you reason about a set of all the worlds that are consistent with a particular dataset and take worst case over them, and how do you find the best policy in this worst-case sense? “Provably Good Batch Reinforcement Learning Without Great Exploration,” which was coauthored by Agarwal, explores these questions in model-free settings, while “MOReL: Model-Based Offline Reinforcement Learning” explores them in a model-based framework.
“Provably Good Batch Reinforcement Learning Without Great Exploration” provides strong theoretical guarantees for such pessimistic techniques, even when the agent perceives its environment through complex sensory observations, a first in the field. A key upshot of the algorithms and results is that when the dataset is sufficiently diverse, the agent provably learns the best possible behavior policy, with guarantees degrading gracefully with the quality of the dataset. MOReL provides convincing empirical demonstrations in physical systems such as robotics, where the underlying dynamics, based on the laws of physics, can often be learned well using a reasonable amount of data. In such settings, the researchers demonstrate that model-based approaches to pessimistic reasoning achieve state-of-the-art empirical performance.
- Publication Empirical Likelihood for Contextual Bandits
A third paper, “Empirical Likelihood for Contextual Bandits,” explores another important and practical question in the batch RL space: how much reward is expected when the policy created using a given dataset is run in the real world? Because the answer can’t be truly known, researchers rely on confidence intervals, which provide bounds on future performance when the future is like the past. As applied in this paper, these bounds can be used to decide training details—the types of learning, representation, or features employed.
Confidence intervals are particularly challenging in RL because unbiased estimators of performance decompose into observations with wildly different scales, says Partner Researcher Manager John Langford, a coauthor on the paper. In the work, researchers compare two crude ways to address this: by randomly rounding things to apply binomial confidence intervals, which are too loose, and by using the asymptotically Gaussian structure of any random variable, which is invalid for small numbers of samples. The researchers’ approach, based on empirical likelihood techniques, manages to be tight like the asymptotic Gaussian approach while still being a valid confidence interval. These tighter and sharper confidence intervals are currently being deployed in Personalizer to help customers better design and assess the performance of applications.
Additional reading: For more on batch RL, check out the NeurIPS paper “Multi-task Batch Reinforcement Learning with Metric Learning.”
Strategic exploration: Gathering data more selectively
In a learning framework in which knowledge comes by way of trial and error, interactions are a hot commodity, and the information they yield can vary significantly. So how an agent chooses to interact with an environment matters. Exploring without a sense of what will result in valuable information can, for example, negatively impact system performance and erode user faith, and even if an agent’s actions aren’t damaging, choices that provide less-than-useful information can slow the learning process. Meanwhile, avoiding parts of an environment in which it knows there is no good reward in favor of areas where it’s likely to gain new insight will make for a smarter agent.
“Once you’re deployed in the real world, if you want to learn from your experience in a very sample-efficient manner, then strategic exploration basically tells you how to collect the smallest amount of data, how to collect the smallest amount of experience, that is sufficient for doing good learning,” says Agarwal.
In “PC-PG: Policy Cover Directed Exploration for Provable Policy Gradient Learning,” Agarwal and his coauthors explore gradient decent–based approaches for RL, called policy gradient methods, which are popular because they’re flexibly usable across a variety of observation and action spaces, relying primarily on the ability to compute gradients with respect to policy parameters as is readily found in most modern deep learning frameworks. However, the theoretical RL literature provides few insights into adding exploration to this class of methods, and there’s a plethora of heuristics that aren’t provably robust. Building on their earlier theoretical work on better understanding of policy gradient approaches, the researchers introduce the Policy Cover-Policy Gradient (PC-PG) algorithm, a model-free method by which an agent constructs an ensemble of policies, each one optimized to do something different. This ensemble provides a device for exploration; the agent continually seeks out further diverse behaviors not well represented in the current ensemble to augment it. The researchers theoretically prove PC-PG is more robust than many other strategic exploration approaches and demonstrate empirically that it works on a variety of tasks, from challenging exploration tasks in discrete spaces to those with richer observations.
Microsoft research podcast

Abstracts: August 15, 2024
Advanced AI may make it easier for bad actors to deceive others online. A multidisciplinary research team is exploring one solution: a credential that allows people to show they’re not bots without sharing identifying information. Shrey Jain and Zoë Hitzig explain.
In the paper “Information Theoretic Regret Bounds for Online Nonlinear Control,” researchers bring strategic exploration techniques to bear on continuous control problems. While reinforcement learning and continuous control both involve sequential decision-making, continuous control is more focused on physical systems, such as those in aerospace engineering, robotics, and other industrial applications, where the goal is more about achieving stability than optimizing reward, explains Krishnamurthy, a coauthor on the paper.
The paper departs from classical control theory, which is grounded in linear relationships where random exploration is sufficient, by considering a nonlinear model that can more accurately capture real-world physical systems. However, nonlinear systems require more sophisticated exploration strategies for information acquisition. Addressing this challenge via the principle of optimism in the face of uncertainty, the paper proposes the Lower Confidence-based Continuous Control (LC3) algorithm, a model-based approach that maintains uncertainty estimates on the system dynamics and assumes the most favorable dynamics when planning. The paper includes theoretical results showing that LC3 efficiently controls nonlinear systems, while experiments show that LC3 outperforms existing control methods, particularly in tasks with discontinuities and contact points, which demonstrates the importance of strategic exploration in such settings.
Additional reading: For more on strategic exploration, check out the NeurIPS paper “Provably adaptive reinforcement learning in metric spaces.”
Representation learning: Simplifying complicated environments
Gains in deep learning are due in part to representation learning, which can be described as the process of boiling complex information down into the details relevant for completing a specific task. Principal Researcher Devon Hjelm, who works on representation learning in computer vision, sees representation learning in RL as shifting some emphasis from rewards to the internal workings of the agents—how they acquire and analyze facts to better model the dynamics of their environment.
“Being able to look at your agent, look inside, and say, ‘OK, what have you learned?’ is an important step toward deployment because it’ll give us some insight on how then they’ll behave,” says Hjelm. “And if we don’t do that, the risk is that we might find out just by their actions, and that’s not necessarily as desirable.”
Representation learning also provides an elegant conceptual framework for obtaining provably efficient algorithms for complex environments and advancing the theoretical foundations of RL.
“We know RL is not statistically tractable in general; if you want to provably solve an RL problem, you need to assume some structure in the environment, and a nice conceptual thing to do is to assume the structure exists, but that you don’t know it and then you have to discover it,” says Krishnamurthy. But the challenge in doing so is tightly coupled with exploration in a chicken-and-egg situation: you need this structure, or compact representation, to explore because the problem is too complicated without it, but you need to explore to collect informative data to learn the representation.
In two separate papers, Krishnamurthy and Hjelm, along with their coauthors, apply representation learning to two common RL challenges: exploration and generalization, respectively.
- Publication Deep Reinforcement and InfoMax Learning
With “Deep Reinforcement and InfoMax Learning,” Hjelm and his coauthors bring what they’ve learned about representation learning in other research areas to RL. In his computer vision work, Hjelm has been doing self-supervised learning, in which tasks based on label-free data are used to promote strong representations for downstream applications. He gives the example of showing a vision model augmented versions of the same images—so an image of a cat resized and then in a different color, then the same augmentations applied to an image of a dog—so it can learn not only that the augmented cat images came from the same cat image, but that the dog images, though processed similarly, came from a different image. Through this process, the model learns the information content that is similar across instances of similar things. For example, it might learn that all cats tend to have certain key characteristics, such as pointy ears and whiskers. Hjelm likens these augmented images to different perspectives of the same object an RL agent might encounter moving around an environment.
The paper explores how to encourage an agent to execute the actions that will enable it to decide that different states constitute the same thing. The researchers introduce Deep Reinforcement and InfoMax Learning (DRIML), an auxiliary objective based on Deep InfoMax. From different time steps of trajectories over the same reward-based policy, an agent needs to determine if what it’s “seeing” is from the same episode, conditioned on the action it took. Positive examples are drawn from the same trajectory in the same episode; negative examples are created by swapping one of the states out for a future state or state from another trajectory. Incorporating the objective into the RL algorithm C51, the researchers show improved performance in the series of gym environments known as Procgen. In performing well across increasingly difficult versions of the same environment, the agent proved it was learning information that wound up being applicable to new situations, demonstrating generalization.
In “FLAMBE: Structural Complexity and Representation Learning of Low Rank MDPs,” Krishnamurthy and his coauthors present the algorithm FLAMBE. FLAMBE seeks to exploit the trove of information available in an environment by setting up a prediction problem to learn that much-needed representation, a step that is conceptually similar to the self-supervised problem in DRIML. The prediction problem used in FLAMBE is maximum likelihood estimation: given its current observation, what does an agent expect to see next. In making such a prediction, FLAMBE learns a representation that exposes information relevant for determining the next state in a way that’s easy for the algorithm to access, facilitating efficient planning and learning. An important additional benefit is that redundant information is filtered away.
FLAMBE uses this representation to explore by synthesizing reward functions that encourage the agent to visit all the directions in the representation space. The exploration process drives the agent to new parts of the state space, where it sets up another maximum likelihood problem to refine the representation, and the process repeats. The result of this iterative process is a universal representation of the environment that can be used after the fact to find a near-optimal policy for any reward function in that environment without further exploration. In the paper, the researchers show FLAMBE provably learns such a universal representation and the dimensionality of the representation, as well as the sample complexity of the algorithm, scales with the rank of the transition operator describing the environment.
Additional reading: For more work at the intersection of reinforcement learning and representation learning, check out the NeurIPS papers “Learning the Linear Quadratic Regulator from Nonlinear Observations” and “Sample-Efficient Reinforcement Learning of Undercomplete POMDPs.”
The exploration continues: Additional RL NeurIPS papers
The above papers represent a portion of Microsoft research in the RL space included at this year’s NeurIPS. To continue the journey, check out these other RL-related Microsoft NeurIPS papers, and for a deeper dive, check out milestones and past research contributing to today’s RL landscape (opens in new tab) and RL’s move from the lab into Microsoft products and services (opens in new tab).
To learn about other work being presented by Microsoft researchers at the conference, visit the Microsoft at NeurIPS 2020 page.
- «Policy Improvement via Imitation of Multiple Oracles,» Ching-An Cheng, Andrey Kolobov, Alekh Agarwal
- “Safe Reinforcement Learning via Curriculum Induction,» Matteo Turchetta, Andrey Kolobov, Shital Shah, Andreas Krause, Alekh Agarwal
- “The LoCA Regret: A Consistent Metric to Evaluate Model-Based Behavior in Reinforcement Learning,” Harm van Seijen, Hadi Nekoei, Evan Racah, Sarath Chandar
- “Constrained episodic reinforcement learning in concave-convex and knapsack settings,” Kianté Brantley, Miroslav Dudik, Thodoris Lykouris, Sobhan Miryoosefi, Max Simchowitz, Aleksandrs Slivkins, Wen Sun
- “Efficient Contextual Bandits with Continuous Actions,” Maryam Majzoubi, Chicheng Zhang, Rajan Chari, Akshay Krishnamurthy, John Langford, Aleksandrs Slivkins
- “AvE: Assistance via Empowerment,” Yuqing Du, Stas Tiomkin, Emre Kiciman, Daniel Polani, Pieter Abbeel, Anca Dragan