
Pretrained language models have been a hot research topic in natural language processing. These models, such as BERT, are usually pretrained on large-scale language corpora with carefully designed pretraining objectives and then fine-tuned on downstream tasks to boost the accuracy. Among these, masked language modeling (MLM), adopted in BERT, and permuted language modeling (PLM), adopted in XLNet, are two representative pretraining objectives. However, both of them enjoy their own advantages but suffer from limitations.
Therefore, researchers from Microsoft Research Asia, after proposing MASS for language generation last year, are proposing a brand new pretrained model called MPNet, which inherits the advantages of MLM and PLM and avoids their limitations. MPNet also achieves better performance in a variety of language understanding tasks, such as GLUE and SQuAD. Our technology is further detailed in our paper, titled “MPNet: Masked and Permuted Pre-training for Language Understanding,” which has been accepted at the 34th Conference on Neural Information Processing Systems (NeurIPS 2020).’
-
 EVENT
Microsoft at NeurIPS 2020
EVENT
Microsoft at NeurIPS 2020
Check out Microsoft at NeurIPS 2020, including all of our NeurIPS publications, the Microsoft session schedule, and open career opportunities
Advantages and disadvantages of MLM and PLM modeling
Microsoft research podcast

Abstracts: August 15, 2024
Advanced AI may make it easier for bad actors to deceive others online. A multidisciplinary research team is exploring one solution: a credential that allows people to show they’re not bots without sharing identifying information. Shrey Jain and Zoë Hitzig explain.
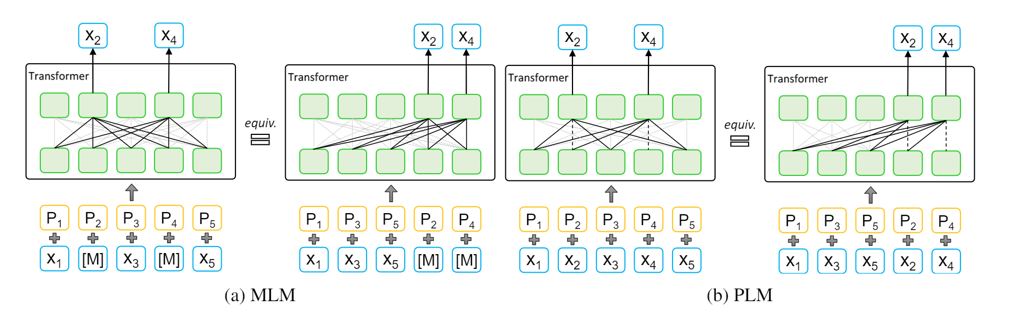
Masked language modeling (MLM) is proposed in BERT, which randomly masks some tokens with a masked symbol [M] and predicts the masked tokens given remaining tokens. For example, given a sequence x=(x1, x2, x3, x4, x5), if masking token x2 and x4, the masked sequence becomes (x1, [M], x3, [M], x5). MLM encourages the model to extract better representations to predict x2 and x4, as shown in the left of Figure 1(a).
Permuted language modeling (PLM) is proposed in XLNet, which randomly permutes a sequence and predicts the tokens in the right part (predicted part) in an autoregressive way. For example, given a sequence x=(x1, x2, x3, x4, x5), if permuting it into (x1, x3, x5, x2, x4), PLM predicts x2 and x4 autoregressively conditioned on (x1, x3, x5), as shown in the right of Figure 1(b).
Comparing MLM and PLM, we can find their advantages and disadvantages: 1) MLM can see the position information of the full sentence, but cannot model the dependency among the predicted tokens, which cannot learn the complicated semantic relationships well; 2) PLM can model the dependency among the predicted tokens with autoregressive prediction, but it cannot see the position information of the full sentence, which will cause mismatches between the pretraining and fine-tuning since the position information of the full sentence can be seen in the downstream tasks. In this work, we inherit the advantages of MLM and PLM but avoid their limitations and design a stronger pretrained model, MPNet.
A unified view of MLM and PLM
To better inherit the advantages of MLM and PLM, we analyze them under a unified view. Pretrained models usually adopt Transformer as the basic model structure, which is not sensitive to the order of the tokens as long as a token is added with the correct position information. In this way, the two subfigures in Figure 1(a) are equivalent, and the two in Figure 1(b) are also equivalent. We can regard the two right subfigures in Figure 1(a) and Figure 1(b) as the unified view of MLM and PLM. Therefore, we can divide the input sequence in MLM and PLM into a non-predicted part and a predicted part.
Combining the best of both worlds
Based on the unified view, we can see that the non-predicted parts in MLM and PLM are the same, while the predicted parts are different. The advantage of MLM is that it can see the position information of the full sentence by introducing mask symbol [M] and its position information in the non-predicted part, while the advantage of PLM is that it can model the dependency among the predicted tokens with autoregressive generation in the predicted part. How can a model inherit their advantages while avoiding their limitations? Our work, the novel pretrained language model MPNet, uses masked and permuted language modeling to model the dependency among predicted tokens and see the position information of the full sentence.
We first fuse the non-predicted part of MLM and PLM together. For example, given the sequence x=(x1, x2, x3, x4, x5), if permuting it into (x1, x3, x5, x2, x4), we select the tokens in the right part (x4, x6, x2) as the predicted tokens, and we set the non-predicted part as (x1, x3, x5, [M], [M], [M]) and the corresponding position information as (p1, p3, p5, p4, p6, p2). As shown in Figure 2, we introduce the output dependency and input consistency to inherit the advantages of MLM and PLM.

Output dependency
To model the dependency among the predicted tokens, we adopt the two-stream self-attention found in PLM for autoregressive generation. We design different masking mechanisms in the query and content stream of the two-stream self-attention to allow the token in the predicted part to see the previously predicted tokens. For example, when predicting token x6, the model can see (x1+p1, x3+p3, x5+p5) in the non-predicted part and the previous predicted (x4+p4) in the predicted part, which can avoid the missing dependency information in MLM.
Input consistency
To make the input information in pretraining consistent with that in downstream tasks, we add the mask symbol and position information of the predicted token ([M]+p4, [M]+p6, [M]+p2) in the non-predicted part to ensure each token can see the position information of the full sentence. For example, when predicting token x6, it can not only see the original (x1+p1, x3+p3, x5+p5) in the non-predicted part and the previous predicted information (x4+p4), but it can also see ([M]+p6, [M]+p2) in the non-predicted part. Through position compensation, the model can see the position information of the full sentence when predicting each token, which avoids the missing position information in PLM.
Method analysis
To analyze the advantages of MPNet, we compare the information usage of different pretraining objectives, as shown in Table 1 (assuming all objectives predict 15% tokens). We find MPNet can leverage 92.5% of token information and 100% of position information, which combines the best of both worlds in MLM and PLM.
| Objective | # Tokens | # Positions |
|---|---|---|
| MLM (BERT) | 85% | 100% |
| PLM (XLNet) | 92.5% | 92.5% |
| MPNet | 92.5% | 100% |
Next, we analyze how MPNet can avoid the disadvantages of MLM and PLM through case analysis. Assume the sequence is [The, task, is, sentence, classification], and we need to predict the tokens [sentence, classification]. The factorizations of MLM, PLM, and MPNet are shown in Table 2.
MLM predicts the tokens [sentence, classification] independently, which may incorrectly predict the second token as “answering,” as if to predict “question answering.” PLM cannot see the position information of the full sentence when predicting tokens [sentence, classification], which may incorrectly predict three tokens as [sentence, pair, classification]. MPNet can see full position information and know there are two tokens to predict, and thus it can model the dependency among predicted tokens and predict the tokens better.
| Objective | Factorization |
|---|---|
| MLM (BERT) | log P (sentence | the task is [M] [M]) + log P (classification | the task is [M] [M]) |
| PLM (XLNet) | log P (sentence | the task is) + log P (classification | the task is sentence) |
| MPNet | log P (sentence | the task is [M] [M] + log P (classification | the task is sentence [M]) |
Experiments
We conduct experiments to verify the effectiveness of MPNet. We choose the configuration of BERT-base, with 12-layer Transformer, hidden size of 768, and a total of 110 million parameters. We pretrain MPNet on a 160 GB corpus, using the same hyperparameters as in RoBERTa. The results on GLUE (Table 3), SQuAD (Table 3), RACE, and IMDB demonstrate that MPNet achieves better accuracy than BERT, XLNet, and RoBERTa.
| MNLI | QNLI | QQP | RTE | SST | MRPC | CoLA | STS | Avg | |
|---|---|---|---|---|---|---|---|---|---|
| Single model on dev set | |||||||||
| BERT (Devlin et al., 2019) | 84.5 | 91.7 | 91.3 | 68.6 | 93.2 | 87.3 | 58.9 | 89.5 | 83.1 |
| XLNet (Yang et al., 2019) | 86.8 | 91.7 | 91.4 | 74.0 | 94.7 | 88.2 | 60.2 | 89.5 | 84.5 |
| RoBERTa (Liu et al., 2019a) | 87.6 | 92.8 | 91.9 | 78.7 | 94.8 | 90.2 | 63.6 | 91.2 | 86.4 |
| MPNet | 88.5 | 93.3 | 91.9 | 85.2 | 95.4 | 91.5 | 65.0 | 90.9 | 87.7 |
| Single model on test set | |||||||||
| BERT (Devlin et al., 2019) | 84.6 | 90.5 | 89.2 | 66.4 | 93.5 | 84.8 | 52.1 | 87.1 | 79.9 |
| ELECTRA (Clark et al., 2020) | 88.5 | 93.1 | 89.5 | 75.2 | 96.0 | 88.1 | 64.6 | 91.0 | 85.8 |
| MPNet | 88.5 | 93.0 | 89.6 | 80.5 | 95.6 | 88.2 | 64.0 | 90.7 | 86.3 |
| SQuAD v1.1 | EM | F1 |
|---|---|---|
| BERT (Devlin et al., 2019) | 80.8 | 88.5 |
| RoBERTa (Liu et al., 2019a) | 84.6 | 91.5 |
| MPNet | 86.8 | 92.5 |
| SQuAD v2.0 | EM | F1 |
| BERT (Devlin et al., 2019) | 73.7 | 76.3 |
| XLNet (Yang et al., 2019) | 80.2 | – |
| RoBERTa (Liu et al., 2019a) | 80.5 | 83.7 |
| MPNet | 82.8 | 85.6 |
To further verify the effectiveness of each design in MPNet, we conduct a series of ablation studies as shown in Table 5. It can be seen that removing position compensation, permutation, and output dependency all result in accuracy drop in GLUE and SQuAD, which demonstrates the effectiveness of MPNet on leveraging the position information of the full sentence and modeling the output dependency among predicted tokens.
| SQuAD V1.1 | SQuAD v2.0 | GLUE | |
|---|---|---|---|
| Model Setting | EM F1 | EM F1 | MNLI SST-2 |
| MPNet | 85.0 91.4 | 80.5 83.3 | 86.2 94.0 |
| — position compensation (=PLM) | 83.0 89.9 | 78.5 81.0 | 86.6 93.4 |
| — permutation (=MLM + output dependency) | 84.1 90.6 | 79.2 81.8 | 85.7 93.5 |
| — permutation & output dependency (=MLM) | 82.0 89.5 | 76.8 79.8 | 85.6 93.3 |
We can observe some other points from Table 5: 1) PLM is sightly better than MLM; 2) although PLM is proposed to solve the output dependency in MLM, it does not solve it well since it can be seen that MLM plus output dependency is better than PLM; 3) when PLM solves the output dependency problem in MLM, it discards the full position information of the sentence. Therefore, MPNet inherits the advantages of MLM and PLM while avoiding their limitations and achieves better results.
For future work, we will pretrain larger MPNet models and apply MPNet to more challenging language understanding tasks. The paper, codes and pretrained models are public. Find the code and pretrained models at our GitHub page. MPNet has been supported in Huggingface, code available on Github. You can read the paper here: https://www.microsoft.com/en-us/research/publication/mpnet-masked-and-permuted-pre-training-for-language-understanding/.
We are focusing on the research of pretraining, including the design of pretraining objectives, model compression, inference speedup for practical deployment, pretraining for multi-modality, and more. You’re welcome to follow our other works on pretraining:



