Lots of important information, including job openings and other kinds of advertising, are often transmitted by word-of-mouth in online settings. For example, social networks like LinkedIn are increasingly used as a way of spreading information about job opportunities, which can greatly affect people’s career development. The goal of social influence maximization, a well-studied problem, is to maximize the number of people in a social network that receive specific information, given a limited budget with which to spread it. An advertiser will choose a limited number of people (the seeds) to directly give the information to, and from there let that information spread throughout the network via word-of-mouth.
On the one hand, this approach can really help more people learn about desirable information than could otherwise get it directly from the advertiser. On the other hand, by relying on word-of-mouth, insiders who are well-connected in the network have easier access to relevant information about opportunities for advancement that can in turn lead to even better connections. Outsiders who lack access to such information will find it much harder to improve their network status. This access gap may lead to a form of inequality that is different from the traditional forms of inequality based on class, race, gender, or other attributes, but nonetheless provides a significant challenge.
Spotlight: Microsoft research newsletter

Microsoft Research Newsletter
Stay connected to the research community at Microsoft.
How can we spread information to a large number of people on a budget while minimizing the gap in access between the highly connected people in the network and the poorly connected people? This is the question that I tackle in new work to appear at The Web Conference 2019 in San Francisco May 13-17, along with coauthors Ashkan Bashardoust and Suresh Venkatasubramanian of the University of Utah, danah boyd of the Data & Society Research Institute, Sorelle A. Friedler of Haverford College, and Carlos Scheidegger of the University of Arizona.
Access gaps and how to close them
We introduced a new measure we call the access gap and study both how to choose the way we optimize for minimizing this access gap and, once we’ve made this choice, how to perform the optimization, that is, choose the seeds. We give theoretical results showing that this optimization is a difficult problem and we provide an empirical study of heuristics for choosing the seeds.
To answer the question of how to best close access gaps, we assumed that information spreads in the network according to the independent cascade model, that describes which people will ever receive the information given the initial set of seeds directly provided the information. Figure 1 provides an example of information spreading in a network according to this model. This model is probabilistic; for any set of initial seeds for each person, we can assign a probability that that person ever receives the information. This results in a set of probabilities, one for each person.
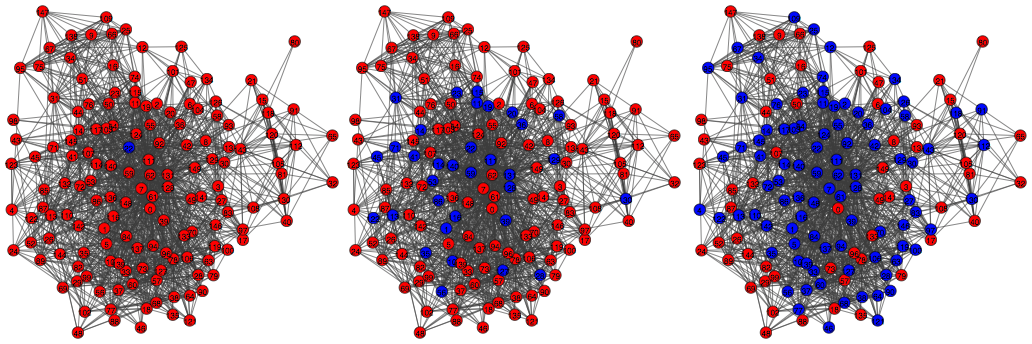
Figure 1: The independent cascade process in action on a network. Blue represents people with the information, red without. The network here starts with one seed (left). Information is spread to the seed’s neighbors, and then neighbors’ neighbors, and so on, (middle) until the spread stops (right). Highly connected people are more likely to receive the information.
Our first question was what exactly should we be optimizing for? Previous work in social influence maximization attempts to maximize the average of those probabilities, which is equivalent to maximizing the expected number of people receiving the information. But this can result in poorly connected people getting small probabilities of receiving the information. This is because it often makes sense to give the information to the people who know the most people. Now suppose you have some function of the set of probabilities (for example, the average of the probabilities) that you are claiming we should maximize. For any such function, which we refer to as a welfare function, we define the access gap between two groups of people to be the difference in their welfare, that is, the difference in the two groups’ average probabilities of receiving the information. What we’d like to prevent is this access gap increasing between any two groups of people after the information is given to the seeds. (There may be an access gap even before giving the information to the seeds because some people might have the information from some other source.)
Unfortunately, we showed that this is not possible; for a wide class of welfare functions, there is a network and a partition of that network into two groups for which the access gap increases after adding the seeds that maximized that welfare function. If we can’t prevent this, what can we prevent? Suppose, according to your favorite welfare function, that one group is doing much better than the other group (for example, one group has much higher average probability than the other), even before we choose seeds. What we can prevent is that, after choosing the seeds, the welfare of the worse-off group doesn’t increase at all. We proved that if the welfare function is the minimum probability – the maximin welfare function – instead of the average probability, this situation where the worse-off group doesn’t see any improvements never occurs. Moreover, we demonstrated that this does occur if you instead use virtually any other welfare function you can think of.
The maximin optimization problem
The maximin objective is much better in helping to avoid access gaps. This brings us to the second question we tackled in this work – how to choose a small set of people to be the seeds in order to maximize the minimum probability any person in the network has of receiving the information. Unfortunately, we discovered that this problem is very hard. (Indeed, we prove that this problem is NP-hard to approximate to within a constant factor, and moreover a variety of simple heuristics have worst-case approximation ratio. Essentially, this is a consequence of the fact that this is not a submodular problem.)
As a result, we tried out a variety of heuristic algorithms to solve this problem on real data. We tried a variety of greedy strategies. The basic greedy strategy is to choose the seeds one at a time in rounds, and in each round we choose the person that maximizes the current minimum probability in the network. An alternate strategy, that we call myopic, is to each time instead choose the person that has the minimum probability in the network in that round.
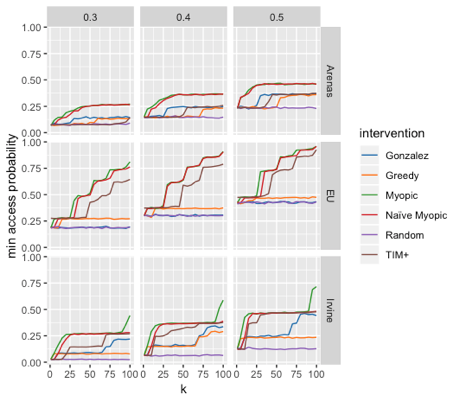
Figure 2: Performance of heuristics on three data sets (Arenas, EU, and Irvine). The three columns are three different settings of a hyperparameter for how well information propagates, and k is the number of seeds chosen. Naïve Myopic is a simple variation on the myopic strategy, Gonzalez refers to the strategy of picking seeds far apart from each other, and TIM+ is a popular algorithm for maximizing the average probability.
Both strategies require estimating the probabilities repeatedly, which is computationally expensive. So, we also investigate a heuristic that avoids that estimation by choosing the people to be seeds that are furthest away from each other in the network, with the intuition that the minimum probability will be large if the seeds are spread all around the network. Perhaps surprisingly, as seen in Figure 2, the myopic heuristic performed quite well, as simple as it is. In other words, even though in the worst case the maximin problem is very difficult, in practice we have evidence that a simple heuristic like myopic performs relatively well.
Our work is just a starting point for talking about the disparities that can exist between users of social networks, and we look forward to continuing conversations about this, including at WWW2019 in San Francisco.