

Microsoft Research and Microsoft Azure are committed to developing technologies that make our data centers the most reliable and high-performance data centers on the planet. We also are committed to extending the state of the art in cloud computing by sharing our ideas openly and freely. This is evident in the technical program of the 15th USENIX Symposium on Networked Systems Design and Implementation – NSDI ‘18 (opens in new tab)) – to be held in Seattle, Washington on April 9, 2018 – April 11, 2018. Microsoft researchers and engineers are heavily engaged with the organizers of this event and have contributed six scientific papers and four posters to its technical program. These papers and posters cover the latest technologies we have developed in networked systems. We are immensely proud of our accomplishments and our contributions follow in the footsteps of a rich tradition at Microsoft of sharing our knowledge and experience with the academic and research communities and with the industry at large.
I was wondering which of our six papers I should write about and it was difficult; I love them all! Should I write about Azure’s SmartNIC technology (opens in new tab) that offers the fastest published bandwidth of any public cloud provider? Or about MP-RDMA, that is, our work on multi-path transport for RDMA that can improve network utilization by up to 47%. The common thread across all these papers is that they constitute significant advances in our field while improving the reliability and efficiency of Microsoft data centers.

GigaPath: Whole-Slide Foundation Model for Digital Pathology
Digital pathology helps decode tumor microenvironments for precision immunotherapy. In joint work with Providence and UW, we’re sharing Prov-GigaPath, the first whole-slide pathology foundation model, for advancing clinical research.
Diagnosing Packet Loss in Cloud-Scale Networks
I like to solve problems, especially complex ones that don’t have obvious solutions. Take for example the problem discussed in our paper, “Democratically Finding the Cause of Packet Drops (opens in new tab).” As the title suggests, this paper describes a system that quickly and accurately discovers the causes of packet drops. Generally, this is a difficult problem to solve. Why? Because data centers can easily have hundreds of thousands of devices and billions of packets in flight per second. The task of determining the cause of packet drops is as difficult as finding the proverbial needle in the haystack. What complicates matters further is short-term buffer overflows on individual switch ports. If you think about it, such packet drops are kind of expected and network protocols are designed to deal with this phenomenon. Cloud operators want a system that distinguishes such drops from those that cause real customer impact. Our system solves this challenging problem.
Here’s another thing – not all failures are equal. For example, a link that drops 0.3% of the packets going through it may impact customers whose application is sensitive to packet drops a lot more than another link that may be dropping 1% of packets but is servicing customers whose applications are resilient to small packet drops. As you can imagine, fixing these faulty links takes time. Wouldn’t it be great if engineers could prioritize these fixes? Here’s what one of our network engineers told us: “In a network of over a million links, it’s a reasonable assumption that there is a non-zero chance that 10 or more these links are bad. This may be due to a variety of reasons – device, port, or cable etc. – and we cannot fix them simultaneously. Therefore, fixes need to be prioritized based on customer impact. We need a direct way to correlate customer impact with bad links.» By finding the cause of individual TCP packet drops, our system enables us to identify the impact of each link on individual TCP connections and by extension attributes those failures to individual customers.
Our system has several attractive properties that I would like to point out. Here’s one: it does not require any changes to the existing networking infrastructure or the clients. I know that those of you who work in this area will appreciate this point. In addition, our system detects in-band failures and it continues to perform beautifully even in the presence of noise, such as lone packet drops. All of this is good, but you might be thinking, what about the overhead? It is negligible. At its core, our system uses a simple voting-based mechanism that is analytically proven to have high accuracy.
I encourage you to read the paper. This is not just a systems research project; its monitoring agent has been running in Microsoft Azure data centers for over two years! The results shown in our paper were derived for a complete system that was deployed in one of our data centers for two months.
Performance and Reachability
Let’s turn our attention to something different but equally important – performance and reachability. High quality end-user experience is particularly important for running a successful cloud business. But the Internet is diverse and dynamic and factors that influence its performance are outside the control of any single organization. Microsoft has developed a system that lets it evaluate fine-grained Internet performance on a global scale.This accomplishment is detailed in our paper, “Odin: Microsoft’s Scalable Fault-Tolerant CDN Measurement System (opens in new tab)”.
Odin is Microsoft’s scalable, fault-tolerant Internet measurement and experimentation platform designed to continuously measure and evaluate Internet performance between Microsoft customers and our services such as Bing or Office 365. Odin lets Microsoft respond quickly to changes in the Internet that might adversely impact our customers’ performance. Also, Odin helps us understand how the overall experience of any customer will be impacted when we make changes to Microsoft’s internal network. This way we do not make changes until we have a solid solution to mitigate any negative impact to our customers.
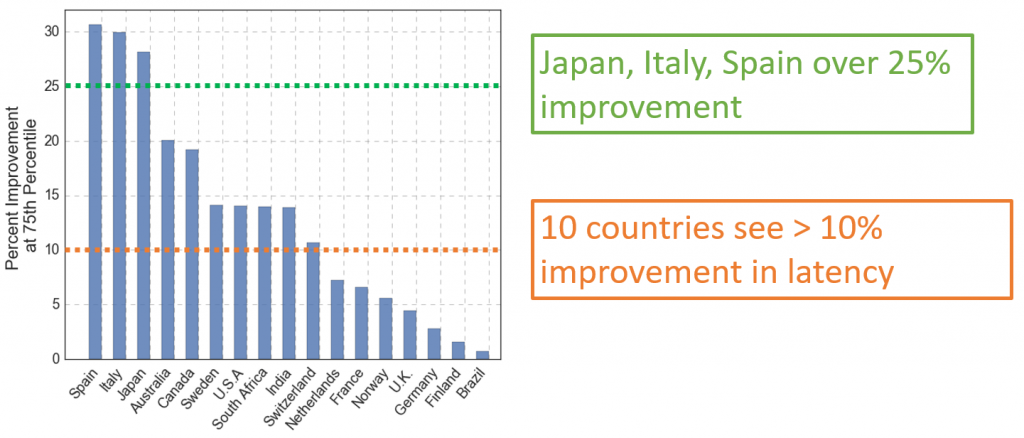
Figure 1: Performance improvement made possible by Odin’s knowledge of Internet latencies to Microsoft’s regional datacenters.
Here’s how we do this: Odin issues active measurements from popular Microsoft applications to get high coverage of the Internet paths from Microsoft’s users to endpoints that can be either inside Microsoft or elsewhere. Measurements are tailored on a per-use-case basis (for example, application requirements). By targeting measurements to external third-party destinations, we can infer unreachability events to Microsoft endpoints due to network failures.
I chose to highlight the Odin paper because this is an “experience paper” that I think will interest many of you. I encourage you to read it because it describes a production system that Microsoft uses. It is a remarkably detailed study of a large, complex Internet measurement platform that is integrated into a few important Microsoft applications, gathering billions of measurements per day. It has been running for over two years, improving operations and detecting and diagnosing reachability issues. It serves as the foundation for several Azure and CDN applications including traffic management, availability alerting, network diagnostics and A/B testing.
Microsoft’s Data Center Tour
Recently I was talking to a seasoned networking researcher who works on cloud computing and builds technology for data centers. He also teaches courses on data center infrastructure and operations. To my great surprise he told me that he had never seen a mega-scale data center.
I believe that for those of us who work in this space it’s important to visit one of the larger data centers to understand and internalize how equipment and networks at these massive scales are put together. I have been to our data centers many times. So, in the spirit of sharing knowledge, in collaboration with Dave Maltz, Microsoft’s distinguished engineer and Azure Physical Networking team lead, we have arranged a tour of one of Microsoft’s mega data centers for students and faculty attending NSDI 2018. The details of this tour are available on the symposium’s website (opens in new tab).
I’ll wrap up by emphasizing how excited we at Microsoft are about meeting our colleagues at the upcoming NSDI Symposium. We’re looking forward to sharing our insights and in turn learning from the insights others have acquired. By the way, the Azure SmartNIC hardware that I mentioned at the beginning of this post is in production and widely available to Azure customers. You can read about it in the engaging Azure Blog post, “Maximize your VM’s Performance with Accelerated Networking – now generally available for both Windows and Linux (opens in new tab)”.
See you at NSDI ’18!


