How we act, including how we speak, is more often than not determined by the situation we find ourselves in. We wouldn’t necessarily use the same tone and language with friends during a night out bowling as we would with colleagues during an office meeting. We tailor dialogue to appropriately fit the scenario. If trained conversational agents are to continue evolving into dependable resources people can turn to for assistance, they’ll need to be trained to do the same.
Today, we’re excited to make available the Intelligent Conversation Engine: Code and Pre-trained Systems, or Microsoft Icecaps (opens in new tab), a new open-source toolkit that not only allows researchers and developers to imbue their chatbots with different personas, but also to incorporate other natural language processing features that emphasize conversation modeling.
Icecaps provides an array of capabilities from recent conversation modeling literature. Several of these tools were driven by recent work done here at Microsoft Research, including personalization embeddings, maximum mutual information–based decoding, knowledge grounding, and an approach for enforcing more structure on shared feature representations to encourage more diverse and relevant responses. Our library leverages TensorFlow in a modular framework designed to make it easy for users to construct sophisticated training configurations using multi-task learning. In the coming months, we’ll equip Icecaps with pre-trained conversational models that researchers and developers can either use directly out of the box or quickly adapt to new scenarios by bootstrapping their own systems.
Multi-task learning and SpaceFusion
Microsoft research podcast

What’s Your Story: Lex Story
Model maker and fabricator Lex Story helps bring research to life through prototyping. He discusses his take on failure; the encouragement and advice that has supported his pursuit of art and science; and the sabbatical that might inspire his next career move.
At Icecaps’ core is a flexible multi-task learning paradigm. In multi-task learning, a subset of parameters is shared among multiple tasks so those tasks can make use of shared feature representations. For example, this technique has been used in conversational modeling to combine general conversational data with unpaired utterances (opens in new tab); by pairing a conversational model with an autoencoder that shares its decoder, one can use the unpaired data to personalize the conversational model. Icecaps enables multi-task learning by representing most models as chains of components and allowing researchers and developers to build arbitrarily complex configurations of models with shared components. Flexible multi-task training schedules are also supported, allowing users to alter how tasks are weighted over the course of training.
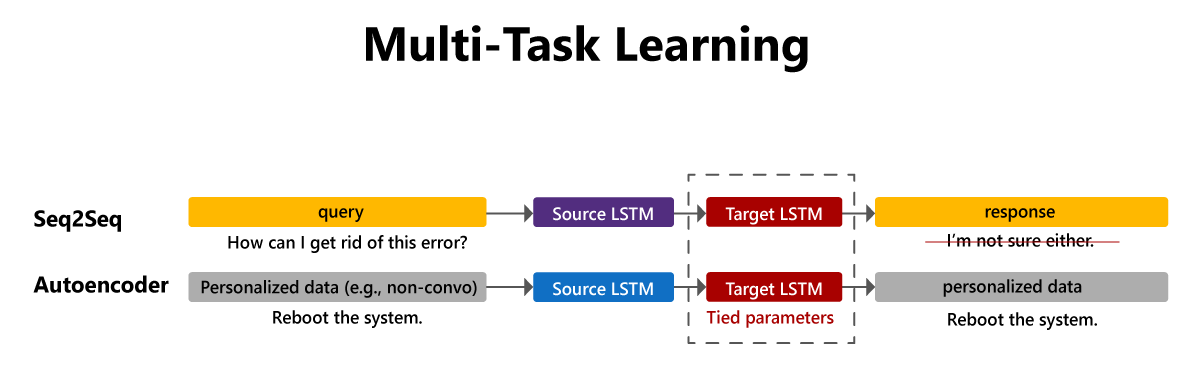
(opens in new tab) In a multi-task learning environment, paired and unpaired data can be combined during training.
Icecaps additionally implements SpaceFusion (opens in new tab), a specialized multi-task learning paradigm originally designed to jointly optimize for diversity and relevance of generated responses. SpaceFusion adds regularization terms to shape the latent space shared among tasks. These terms better align the distributions learned by each task over this latent space.
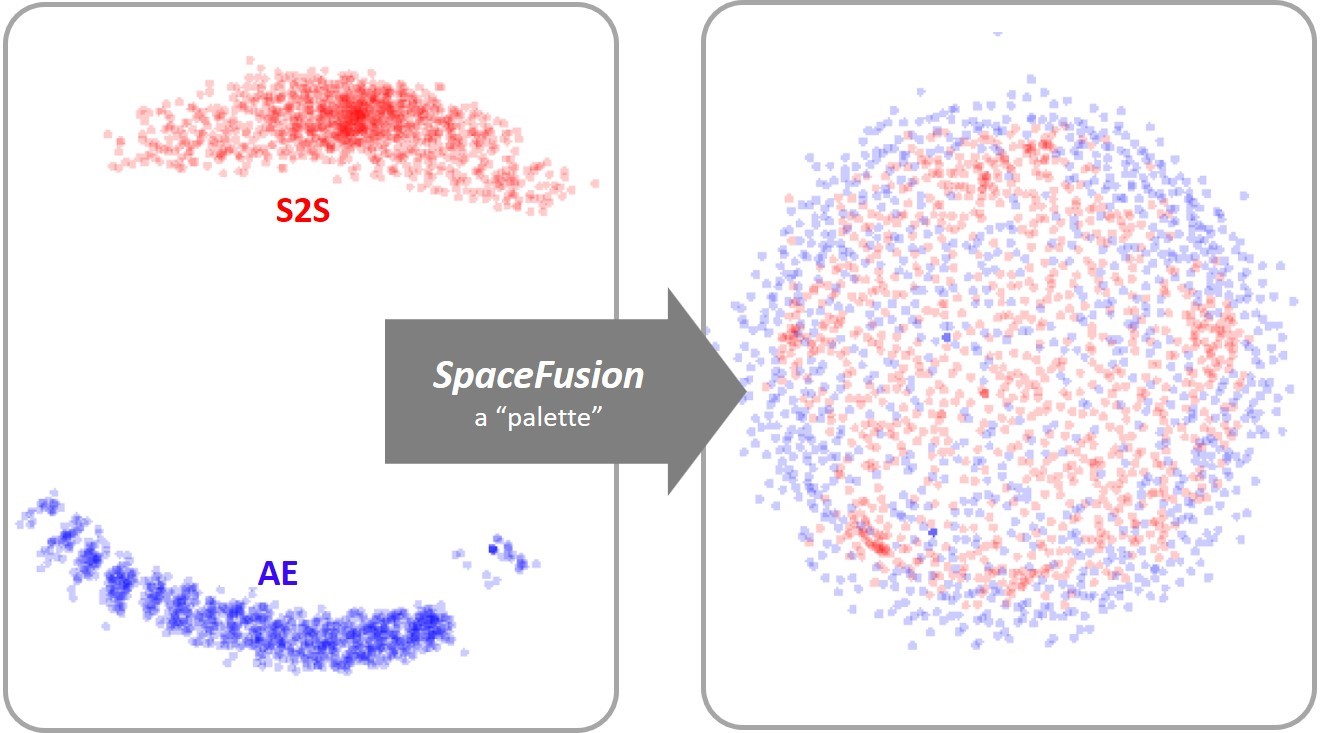
(opens in new tab) SpaceFusion adds regularization terms to a multi-task learning environment, imposing structure upon the shared latent space to improve efficiency.
Personalization
To achieve personalization in conversational scenarios where an AI may be required to adopt some persona with its own particular style and attributes, Icecaps allows researchers and developers to train multi-persona conversation systems on multi-speaker data using personality embeddings (opens in new tab). Personality embeddings work similarly to word embeddings; just as we learn an embedding for each word to describe how words relate to each other within a latent word space, we can learn an embedding per speaker from a multi-speaker dataset to describe a latent personality space. Multi-persona encoder-decoder models provide the decoder a personality embedding alongside word embeddings to condition the decoded response on the selected personality.
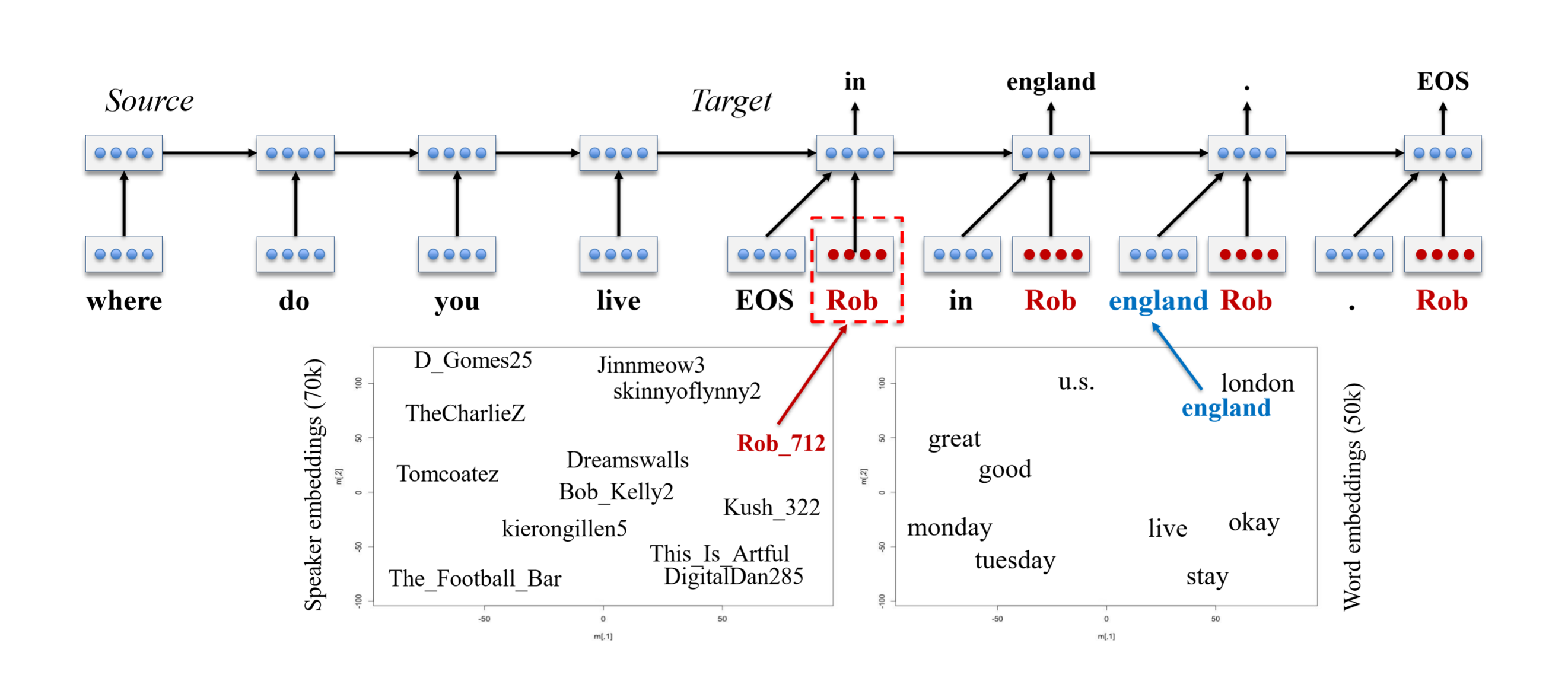
(opens in new tab) By combining a word embedding space with a persona embedding space, personalized sequence-to-sequence models enable personalized response generation.
MMI-based decoding
Conversational systems trained on noisy real-world data tend to produce nonspecific, bland responses such as “I don’t know what you’re talking about.” These systems learn this behavior as a safe way to consistently produce context-appropriate responses. The cost is response diversity and content. One method to tackle this issue is hypothesis reranking based on maximum mutual information (MMI) (opens in new tab). This approach trains a second model to predict the context given a potential response. This model assigns an additional score to each hypothesis generated by the base decoder, and this additional score is used to rerank the set of hypotheses. MMI takes the potential responses most targeted toward the given context and pushes them to the top of the list. Icecaps incorporates MMI-based reranking, among several other decoding features, as part of its custom beam search decoder.
Knowledge grounding
One of the major bottlenecks in training conversational systems is a lack of conversational data that captures the richness of information present in the abundance of non-conversational data that exists in the world. We therefore need good tools that can take advantage of the latter. To train an intelligent agent endowed with all the knowledge contained within Wikipedia or other encyclopedic sources, for instance, Icecaps implements an approach to knowledge-grounded conversation that combines machine reading comprehension and response generation modules (opens in new tab). The model uses attention to isolate content from the knowledge source relevant to the context, allowing the model to produce more informed responses.
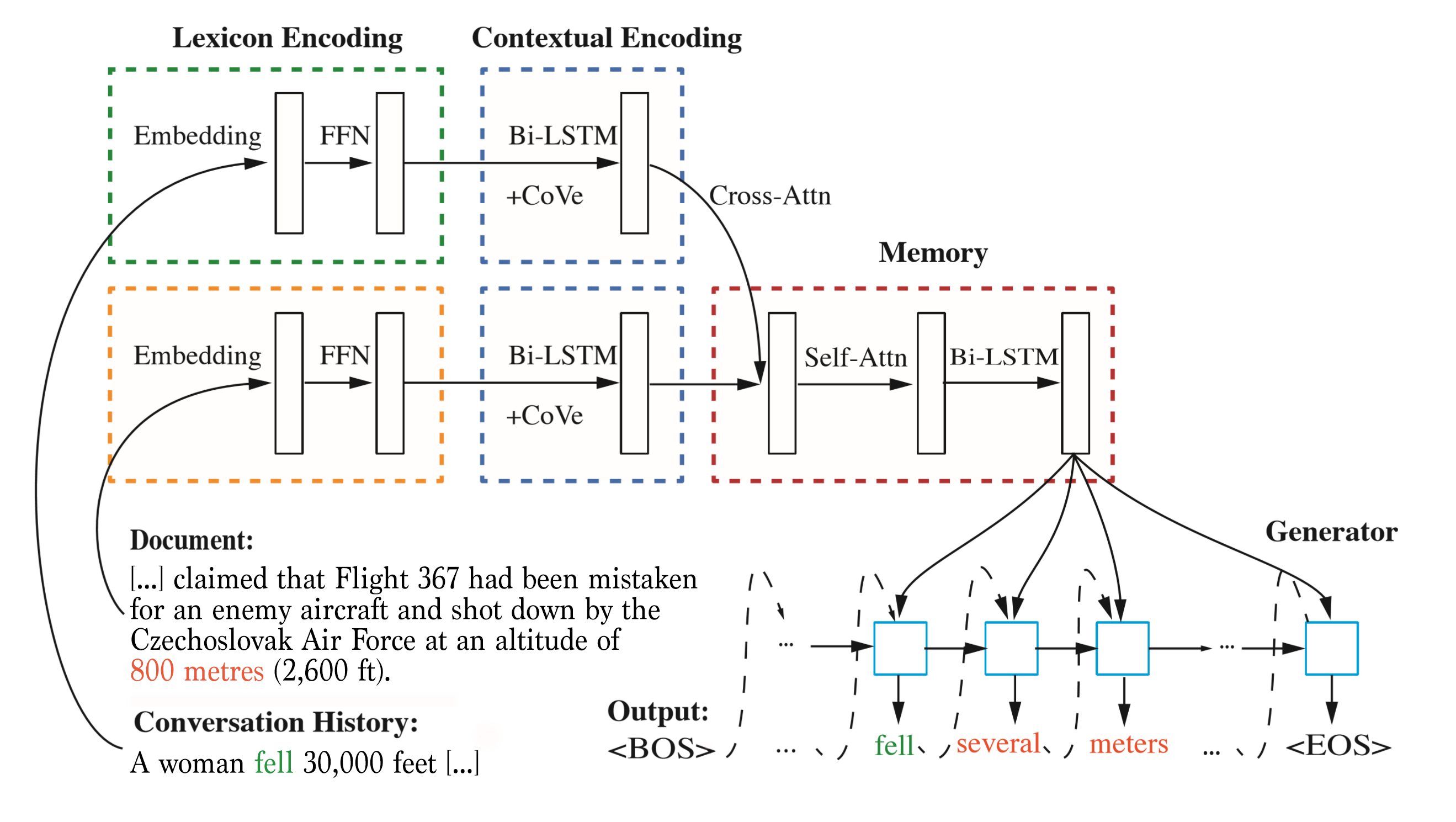
(opens in new tab) Cross-attention can be used to extract pertinent information from an external knowledge base for shaping generated responses.
Follow us!
Follow our GitHub page (opens in new tab)! You will receive updates as we add pre-trained systems, new natural language processing features, and tutorials. Informed personalized chatbots are only the beginning for conversational modeling; promising new areas of research include content filtering, multi-lingual modeling, and hybridizing conversational and task-oriented capabilities. We care about advancing the field of conversational modeling, and with Icecaps, our goal is to empower researchers and developers to push the cutting edge.