
These research papers were presented at the ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (opens in new tab) (ESEC/FSE 2023), a premier conference in the field of software engineering.

The practice of software development inevitably involves the challenge of handling bugs and various coding irregularities. These issues can become pronounced when developers engage in the common practice of copying and pasting code snippets from the web or other peer projects. While this approach might offer a quick solution, it can introduce a host of potential complications, including compilation issues, bugs, and even security vulnerabilities into the developer’s codebase.
To address this, researchers at Microsoft have been working to advance different aspects of the software development lifecycle, from code adaptation to automated bug detection and repair. At ESEC/FSE 2023 (opens in new tab), we introduced two techniques aimed at enhancing coding efficiency. AdaptivePaste utilizes a learning-based approach to adapt and refine pasted code snippets in an integrated development environment (IDE). InferFix is an end-to-end program repair framework designed to automate bug detection and resolution. This blog outlines these technologies.
Microsoft research podcast

What’s Your Story: Lex Story
Model maker and fabricator Lex Story helps bring research to life through prototyping. He discusses his take on failure; the encouragement and advice that has supported his pursuit of art and science; and the sabbatical that might inspire his next career move.
AdaptivePaste: Intelligent copy-paste in IDE
A widespread practice among developers involves adapting pasted code snippets to specific use cases. However, current code analysis and completion techniques, such as masked language modeling and CodeT5, do not achieve an acceptable level of accuracy in identifying and adapting variable identifiers within these snippets to align them with the surrounding code. In the paper, “AdaptivePaste: Intelligent Copy-Paste in IDE,” we propose a learning-based approach to source code adaptation, aiming to capture meaningful representations of variable usage patterns. First, we introduce a specialized dataflow-aware de-obfuscation pretraining objective for pasted code snippet adaptation. Next, we introduce a transformer-based model of two variants: a traditional unidecoder and parallel-decoder model with tied weights.
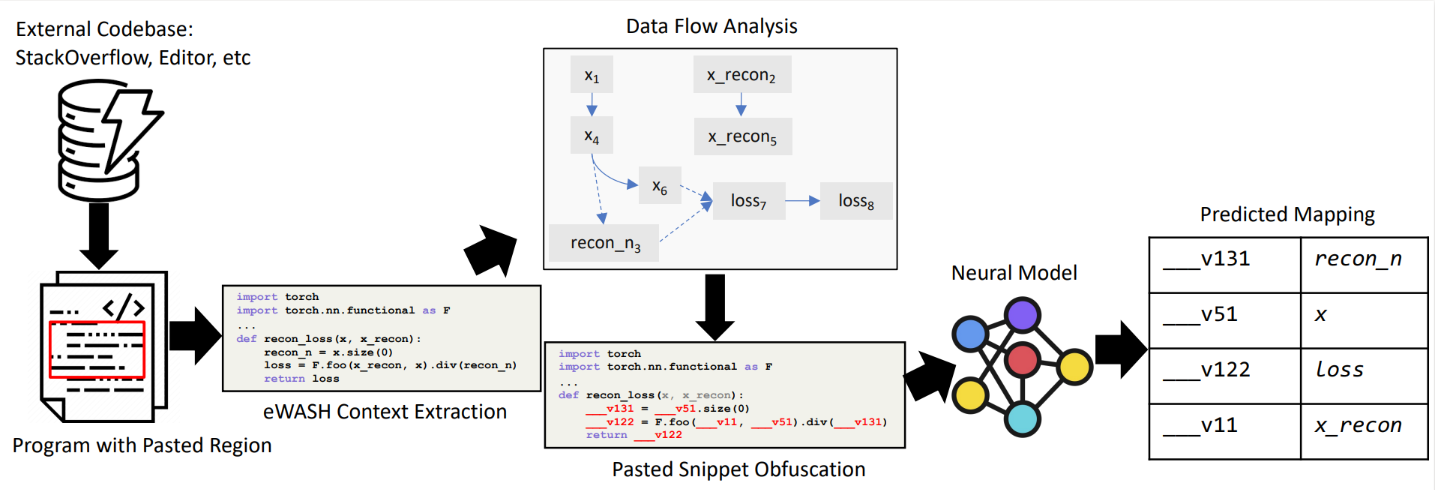
The unidecoder follows a standard autoregressive decoder formulation, mapping each variable in the pasted snippet to a unique symbol in the context or declaring a new variable. The parallel decoder duplicates the decoder for each anonymized symbol in the anonymized pasted snippet, predicting names independently and factorizing the output distribution per symbol. This enables selective code snippet adaptation by surfacing model predictions above a specified threshold and outputting “holes” where uncertainty exists.
To establish a dataflow-aware de-obfuscation pretraining objective for pasted code snippet adaptation, we assigned mask symbols to variable identifiers at the granularity of whole code tokens. The pre-existing code context was unanonymized, allowing the model to attend to existing identifier names defined in scope.
Our evaluation of AdaptivePaste showed promising results. It successfully adapted Python source code snippets with 67.8 percent exact match accuracy. When we analyzed the impact of confidence thresholds on model predictions, we observed that the parallel decoder transformer model improves precision to 85.9 percent in a selective code adaptation setting.
InferFix: End-to-end program repair with LLMs
Addressing software defects accounts for a significant portion of development costs. To tackle this, the paper, “InferFix: End-to-End Program Repair with LLMs over Retrieval-Augmented Prompts,” introduces a program repair framework that combines the capabilities of a state-of-the-art static analyzer called Infer, a semantic retriever model called Retriever, and a transformer-based model called Generator to address crucial security and performance bugs in Java and C#.
The Infer static analyzer is used to reliably detect, classify, and locate critical bugs within complex systems through formal verification. The Retriever uses a transformer encoder model to search for semantically equivalent bugs and corresponding fixes in large datasets of known bugs. It’s trained using a contrastive learning objective to excel at finding relevant examples of the same bug type.
The Generator employs a 12 billion-parameter codex model, fine-tuned on supervised bug-fix data. To enhance its performance, the prompts provided to the Generator are augmented with bug type annotations, bug contextual information, and semantically similar fixes retrieved from an external nonparametric memory by the Retriever. The Generator generates the candidate to fix the bug.
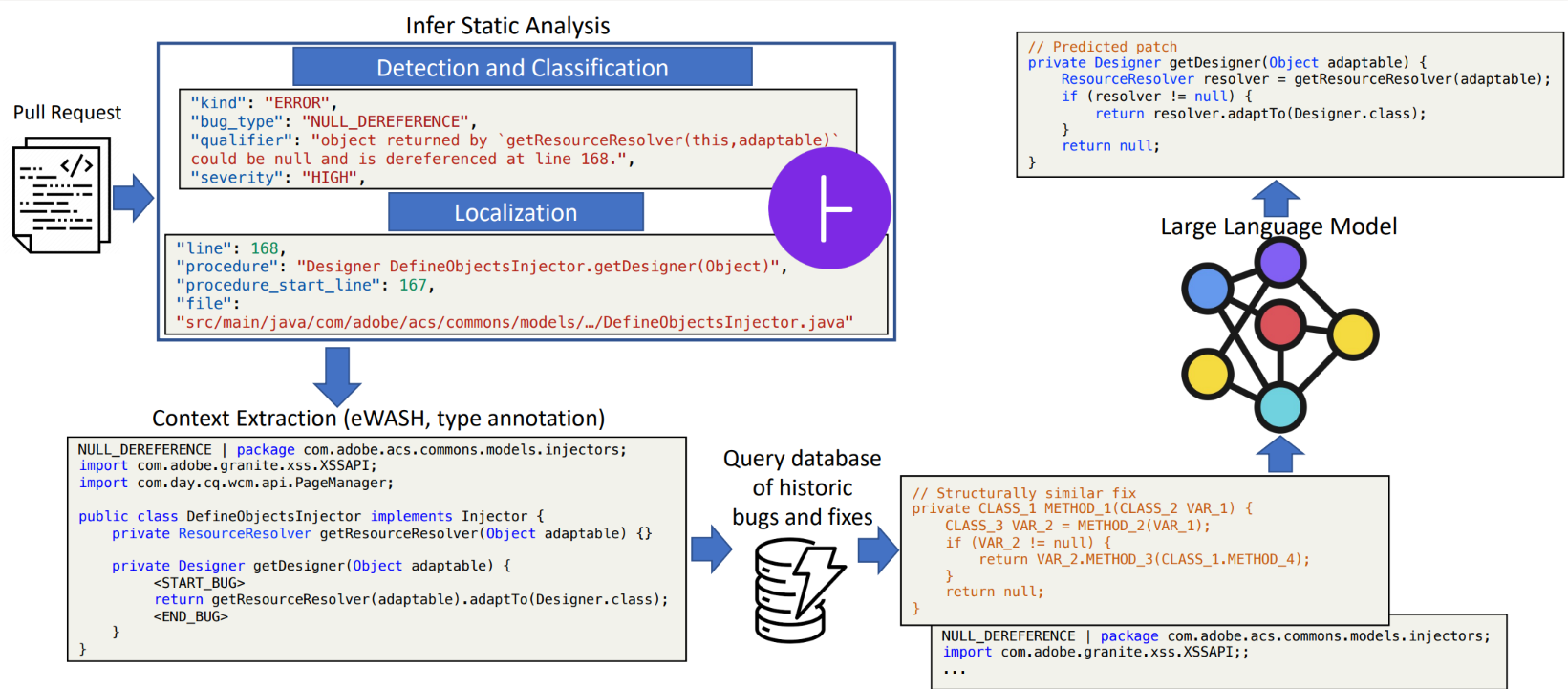
To test InferFix, we curated a dataset called InferredBugs (opens in new tab), which is rich in metadata and comprises bugs identified through executing the Infer static analyzer on thousands of Java and C# repositories. The results are noteworthy. InferFix outperforms strong LLM baselines, achieving a top-1 accuracy of 65.6 percent in C# and an impressive 76.8 percent in Java on the InferredBugs dataset.
Looking ahead
With AdaptivePaste and InferFix, we hope to significantly streamline the coding process, minimizing errors and enhancing efficiency. This includes reducing the introduction of bugs when code snippets are added and providing automated bug detection, classification, and patch validation. We believe that these tools hold promise for an enhanced software development workflow, leading to reduced costs and an overall boost in project efficiency.
Looking ahead, the rapid advancement of LLMs like GPT-3.5 and GPT-4 has sparked our interest in exploring ways to harness their potential in bug management through prompt engineering and other methods. Our goal is to empower developers by streamlining the bug detection and repair process, facilitating a more robust and efficient development environment.



