(opens in new tab)Memory is an important part of human intelligence and the human experience. It grounds us in the current moment, helping us understand where we are and, consequently, what we should do next. Consider the simple example of reading a book. The ultimate goal is to understand the story, and memory is the reason we’re able to do so. Memory allows us to efficiently store the information we encounter and later recall the details we’ve previously read, whether that be moments earlier or weeks, to piece together the full narrative. Memory is equally important in deep learning, especially when the goal is to create models with advanced capabilities. In the fields of natural language understanding and processing, for example, memory is crucial for modeling long-term dependencies and building representations of partially observable states.
(opens in new tab)Memory is an important part of human intelligence and the human experience. It grounds us in the current moment, helping us understand where we are and, consequently, what we should do next. Consider the simple example of reading a book. The ultimate goal is to understand the story, and memory is the reason we’re able to do so. Memory allows us to efficiently store the information we encounter and later recall the details we’ve previously read, whether that be moments earlier or weeks, to piece together the full narrative. Memory is equally important in deep learning, especially when the goal is to create models with advanced capabilities. In the fields of natural language understanding and processing, for example, memory is crucial for modeling long-term dependencies and building representations of partially observable states.
In a paper (opens in new tab) published at the 33rd Conference on Neural Information Processing Systems (NeurIPS) (opens in new tab), we demonstrate how to use a deep neural network itself as a memory mechanism. We propose a new model, Metalearned Neural Memory (MNM), in which we store data in the parameters of a deep network and use the function defined by that network to recall the data.
Deep networks—powerful and flexible function approximators capable of generalizing from training data or memorizing it—have seen limited use as memory modules, as writing information into network parameters is slow. Deep networks require abundant data and many steps of gradient descent to learn. Fortunately, recent progress in few-shot learning and metalearning has shown how we might overcome this challenge. Methods from these fields can discover update procedures that optimize neural parameters from many fewer examples than standard stochastic gradient descent. It’s through metalearning techniques that MNM learns to remember: It learns how to read from and write to memory, as opposed to using hard-coded read/write operations like most existing computational memory mechanisms.

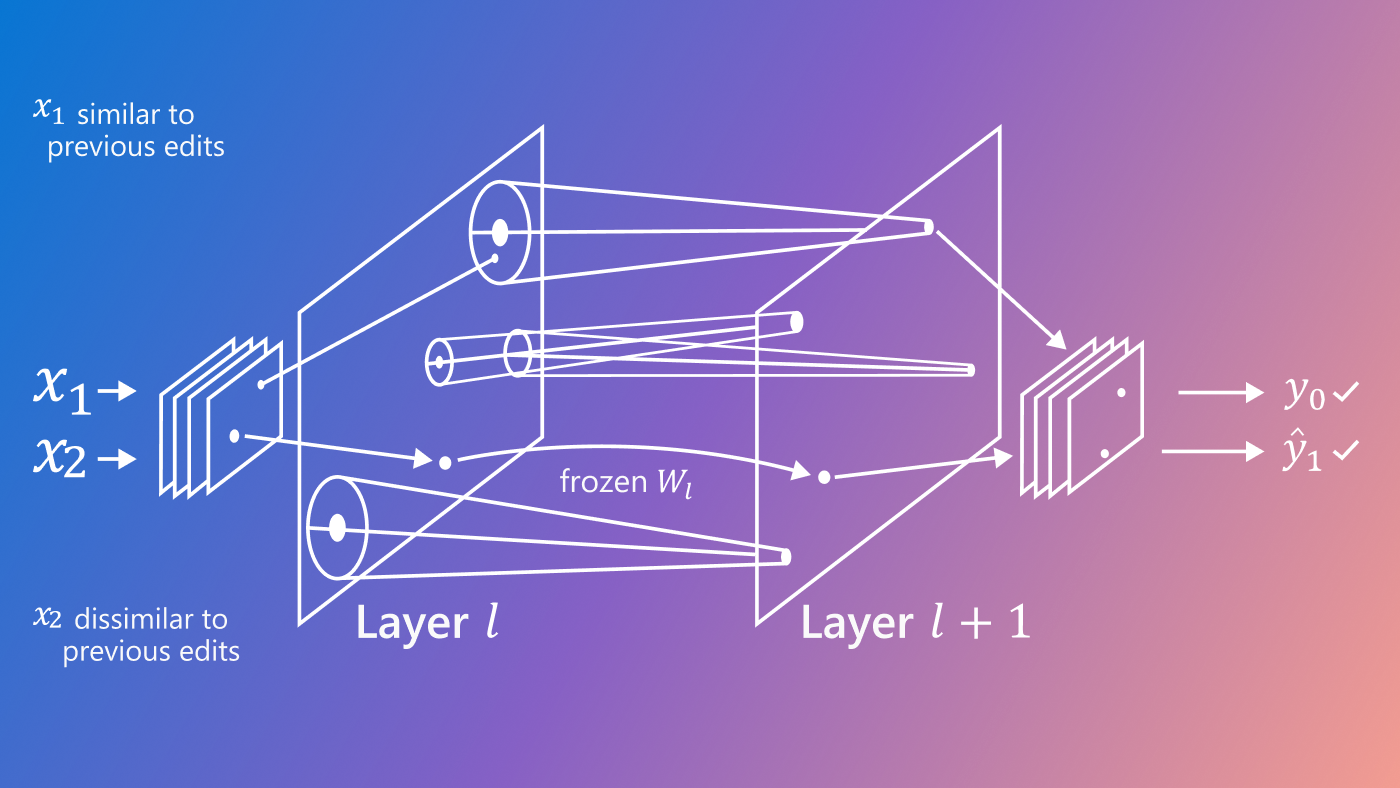
(opens in new tab) Figure 1: Metalearned Neural Memory (MNM) employs a feedforward network for memory and a recurrent neural network controller for writing to and reading from the memory. In the above illustration of the model, green and blue arrows indicate data flows for writing and reading operations, respectively.
Learning how to remember: Reading, writing, and metalearning
With MNM, we combine a fully connected feedforward network for memory with a recurrent neural network (RNN) controller. The controller writes to and reads from the neural memory.
During reading, the feedforward network acts as a function that maps keys to values. We pass a read-out key from the controller as input to the neural memory, then take the memory’s corresponding output vector as the read-out value. These values are what the neural memory “retrieves”; they’re passed back into the controller for use in downstream tasks. In the process of writing, we update the memory function’s parameters—minimizing the error between an output vector resulting from a specific write-in key and a target value—such that the memory function will retrieve the desired values accurately. Both the target value and the write-in key come from the controller. The controller thereby decides what it wants to store in memory and how it wants to trigger it.
The parameter updates for writing to memory happen continually, at both training and test time. The controller parameters—which are distinct from the memory parameters—are trained end-to-end using a task objective reflective of the particular model and a meta objective for learning good update strategies. Importantly, gradients of the meta and task objectives include the memory write computations; through them, the controller learns to change the memory parameters to accommodate new data.
A novel gradient-free learned local update rule
We trained MNM using two alternative memory update procedures: a gradient-based method and a novel gradient-free learned local update rule. We refer to MNM trained with the former as MNM-g and MNM trained with the latter as MNM-p.
Utilizing standard gradient descent to update parameters for memory writing is an obvious choice, but the approach, as we discovered, has its weaknesses. It may require multiple sequential gradient steps to store information reliably, and it requires computing multiple orders of gradients—those for updating the neural memory and the gradients of those gradients to optimize the meta objective. These higher-order gradients are computationally expensive, and their values tend to vanish to zero, yielding no training signal. Our learned local update rule can be optimized for fast writing while avoiding these challenges.
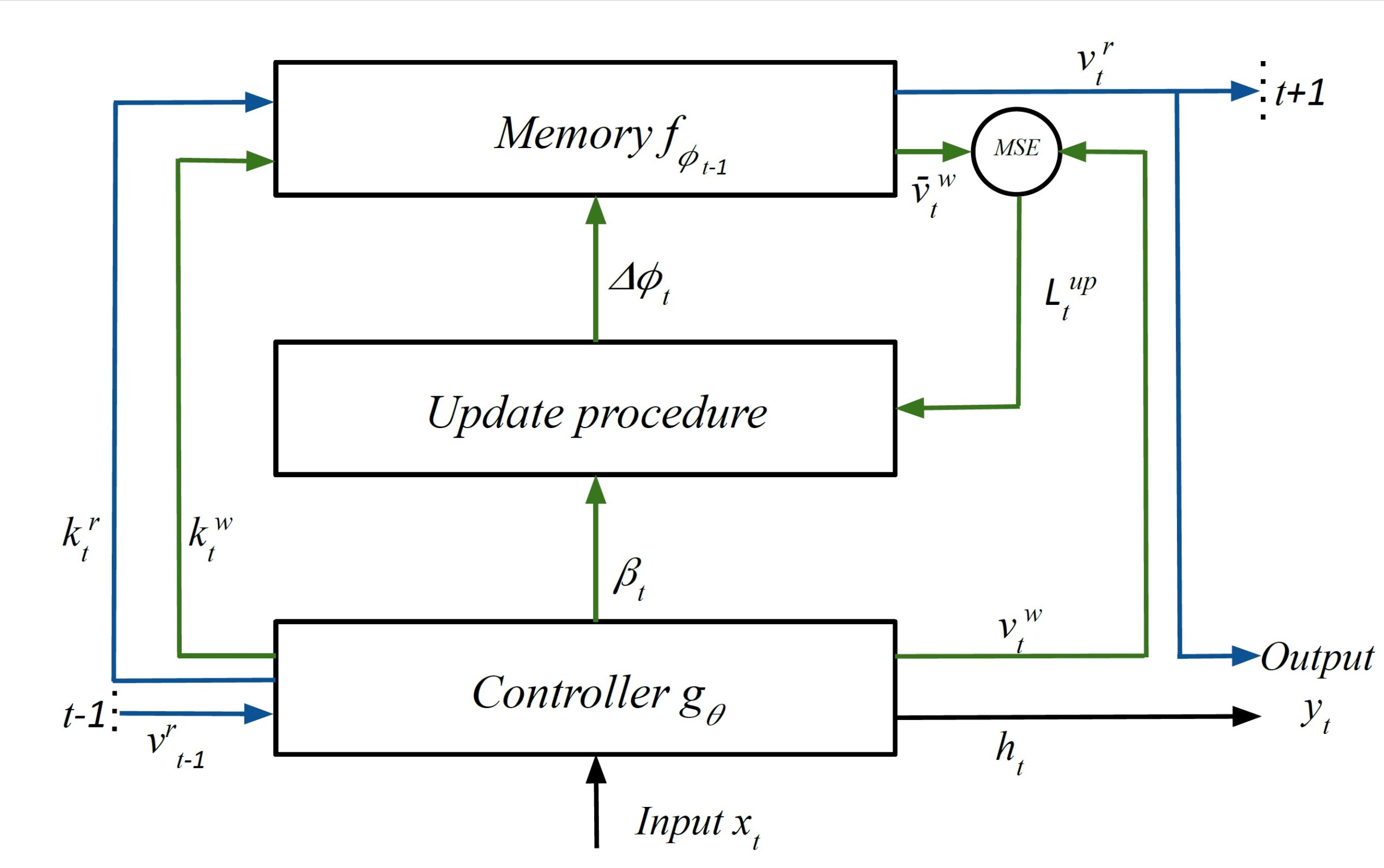
(opens in new tab) Figure 2: Metalearned Neural Memory uses two alternative update procedures—a gradient-based method and a novel gradient-free learned local update rule—to update parameters for memory writing in neural memory. Pictured above is the overall data flow in neural memory with the learned local update procedure. The main neural memory is in blue and the backward feedback prediction functions (BFPF) modules, used for predictions, are in orange.
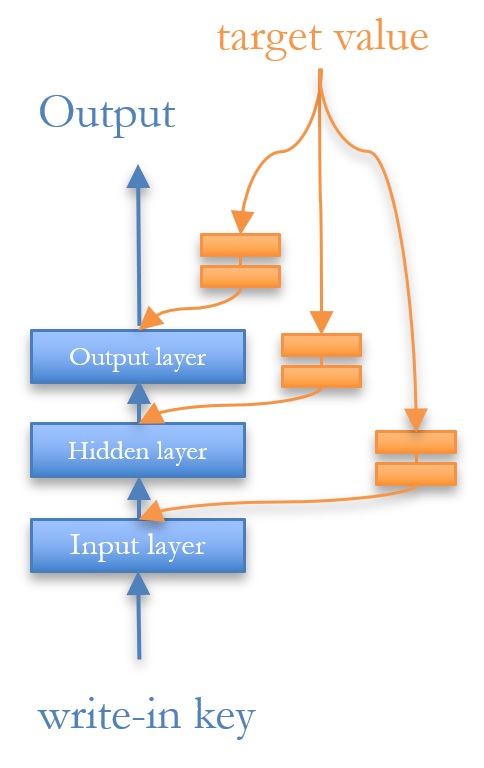
In executing the learned local update rule, we decouple the computation of each layer of the neural memory into separate forward propagation, shown in blue in Figure 2, and backward feedback prediction functions (BFPF), shown in orange. For a neural memory layer l, the BFPF makes a prediction for an expected activation z‘l based on the target value. Using the perceptron learning rule, we update the weights of the layer as follows, where zl and zl-1 are activations of the current and previous layers: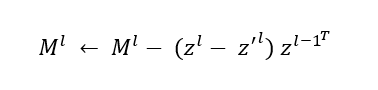 (opens in new tab)For clarity, we’ve omitted time index and the update rate here (see our paper (opens in new tab) for the full equation).
(opens in new tab)For clarity, we’ve omitted time index and the update rate here (see our paper (opens in new tab) for the full equation).
The perceptron update rule uses the predicted activation as a true target and approximates the gradient via the outer product: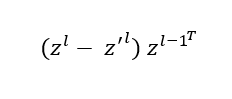 (opens in new tab)Since this update is fully differentiable, we can easily adjust the parameters of the BFPF functions, as well.
(opens in new tab)Since this update is fully differentiable, we can easily adjust the parameters of the BFPF functions, as well.
With the proposed learned local update rule, MNM writes to its weights simultaneously and locally, and its full computation graph for the forward pass need not be tracked for writing. This makes the proposed update method very efficient and easier to apply to more complex neural architectures for memory like RNNs.
Interpreting learned memory function
When put to the test against the bAbI question-answering benchmark, an industry standard for gauging long-term memory and reasoning that has generally proven difficult for neural models with soft lookup tables to solve (opens in new tab), MNM-g and MNM-p both outperform several state-of-the-art models.
The tasks in the benchmark—20 in total—require MNM to read a story with multiple characters word-by-word before answering a question about it. Since the story is read before the question is known, the model has to track all of the characters in memory. By comparing the different combination of memory input keys and output values occurring during the tasks, we can visualize what is being read from and written to the memory; we observe very similar memory reading/writing styles in MNM-g and MNM-p.
Take MNM-g on the following bAbI story and question, for example:
Mary travelled to the garden. Mary moved to the bedroom. Sandra went to the bathroom. Daniel travelled to the bathroom. Mary travelled to the office. Daniel moved to the hallway. John moved to the kitchen. Daniel went to the garden.
Where is Daniel?
In Figure 3, each cell represents the similarity between the write-in keys or target values already generated for the words in the previously read sentences (x-axis) and the write-in keys or target values being generated as the model reads each word in the last sentence (y-axis), respectively. The higher the similarity, the brighter the color. A comparison of the current and past write-in keys can show where the memory is writing to; a comparison of the current and past target values can reveal what’s being written. Together, they can tell us what key-value association is being made in the memory with the write operation.
In looking at the write-in keys, there is a clear word-by-word alignment, for example, between the words in the sentences “Daniel went to the garden” and “Daniel moved to the hallway,” indicated by the brightly colored diagonal. The write-in keys are similar for the concepts related to the same character. When examining the target values, we spot a similar alignment except for the word pair “garden” and “hallway.” For this pair, the target values are different while their keys are the same. This means that the model is creating a new association of “Daniel”-“garden” by replacing the old one of “Daniel”-“hallway” to maintain a coherent memory structure as it continues to read the story.
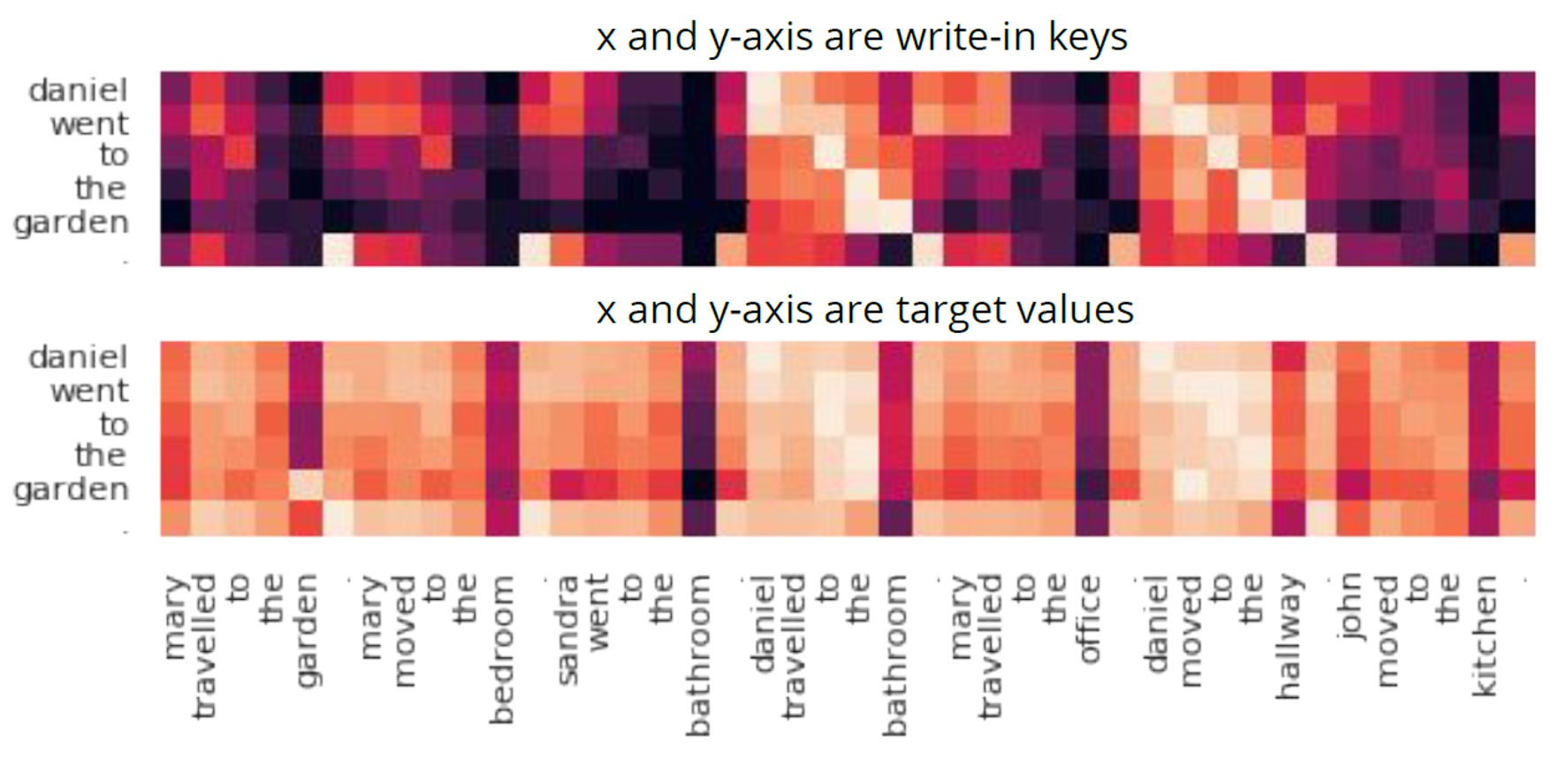
(opens in new tab) Figure 3: Analysis of the input keys and output values occurring during bAbI question-answering tasks provides insight into the inner workings of the Metalearned Neural Memory model. Above is a visualization of the memory writing.
We also investigated the behavior of a reinforcement learning agent with neural memory in a Grid World setup. Below we have shown the agent (orange), augmented with MNM-g, exploring the Grid World for the goal (red) on the left and its top five memory recalls on the right. Such analysis can show the agent’s memory recall patterns while it’s exploring the Grid World environment.
 (opens in new tab)
(opens in new tab) (opens in new tab)
(opens in new tab) (opens in new tab)
(opens in new tab) (opens in new tab)
(opens in new tab) (opens in new tab)Many a memory
(opens in new tab)Many a memory
The idea of using a neural network as a memory store is not entirely novel. It goes back at least as far as John J. Hopfield’s 1988 work in associative memory (opens in new tab). To our knowledge, though, we’re the first to adopt metalearning techniques to store information rapidly in deep networks. A similar idea, more closely related to Hopfield’s, has emerged in recent related work (opens in new tab).
Deep learning research is just scratching the surface when it comes to memory. We believe that just as the human brain possesses different types of memory, such as working and procedural, there is a variety of memory types to uncover in pushing the state of the art in deep learning. We consider MNM a part of that push, and while we used just a feedforward network, we envision applying neural memory to more complex architectures like RNNs and graph neural networks, building in different inductive biases to help model what we see in the data.
To experiment with the MNM code and tasks, check out our PyTorch implementation (opens in new tab).