
This research paper was presented at the 12th International Conference on Learning Representations (opens in new tab) (ICLR 2024), the premier conference dedicated to the advancement of deep learning.

Large language models (LLMs) use extensive datasets and advanced algorithms to generate nuanced, context-sensitive content. However, their development requires substantial computational resources. To address this, we developed LoftQ, an innovative technique that streamlines the fine-tuning process—which is used to adapt pre-trained language models to perform well in specialized applications, such as analyzing medical documents. During fine-tuning, the model undergoes additional training on a smaller, task-specific dataset. This results in improved performance, such as more accurate predictions, better understanding of domain-specific language, and more relevant responses in the context of the specialized area.
LoftQ’s strength lies in its ability to combine quantization and adaptive initialization during fine-tuning. Quantization reduces the precision of model parameters, lowering memory and computation needs. This not only accelerates processing but also reduces power consumption. Adaptive initialization closely aligns the model’s parameters to its optimal pre-trained state, preserving its capabilities while minimizing resource use. Our paper, “LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models,” presented at ICLR 2024, details how this method can help make AI technologies more efficient and sustainable.
How LoftQ works
LoftQ builds on the principles of LoRA (opens in new tab) and QLoRA (opens in new tab). LoRA is a method that greatly reduces the number of parameters needed for training, decreasing the memory requirements for fine-tuning. QLoRA is a fine-tuning approach that uses 4-bit quantized, frozen weights and low rank adapters, significantly reducing memory requirements while maintaining high performance. This is illustrated in Table 1, which shows the amount of memory needed for fine-tuning an LLM with 7 billion parameters as well as the memory requirements for LoRA and QLoRA. LoRA achieves a fourfold reduction in memory usage, and QLoRA further reduces it by twofold.

Unlike LoRA, QLoRA comes with a tradeoff, where some quality of the pretrained model is sacrificed due to the quantization of weights. LoftQ recognizes this and optimizes the initialization of quantization and low-rank adaptation matrices. That is, LoftQ seeks to identify a combination of a quantized matrix and a low rank matrix such that their sum closely approximates the original pretrained weight. This is done for every matrix that would be adapted in the model.
The LoftQ algorithm alternates between two primary steps. First it quantizes (simplifies) the weights, and then it finds the best low-rank factors that approximate the quantization between the pretrained weight and the low-rank weight. The process repeats for a few steps. This method enables the fine-tuning process to start from a more effective initial state, which preserves accuracy while using less computational power and much more simplified weights.
LoftQ requires a one-time setup to simplify and prepare these weights, allowing a fixed portion of the model’s parameters (e.g., 5 percent) to be adjusted. Once established, this configuration can be repeatedly applied as the model transitions between various tasks and settings.
Evaluating LoftQ
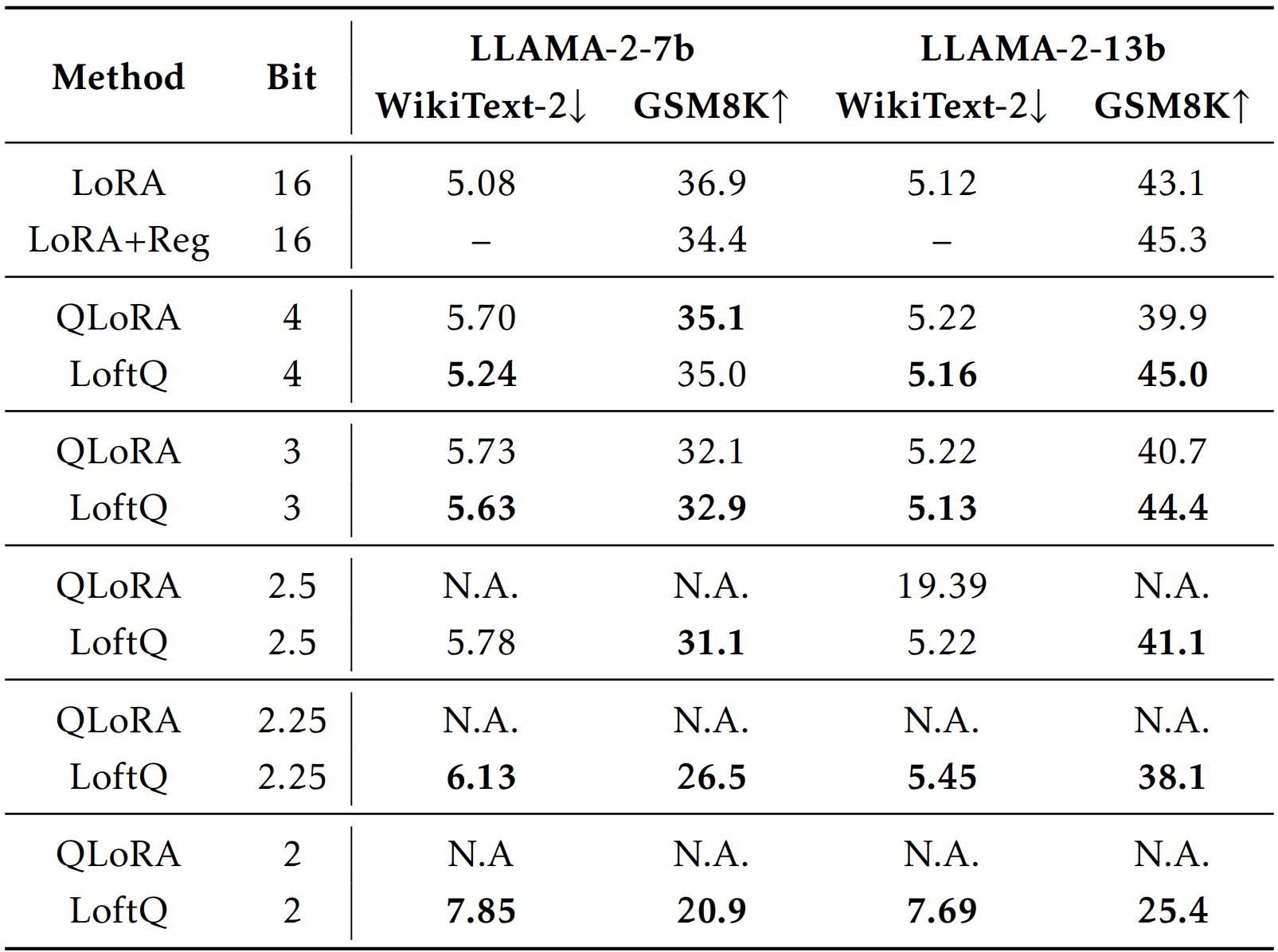
Tests using various types of LLMs, including those with different combinations of encoding and decoding capabilities like the Llama-2, show that models initialized with LoftQ consistently achieve strong performance, often matching or surpassing those configured with QLoRA.
In practical terms, comparing the performance of LoftQ and QLoRA on different tasks using the Llama-2 model family yields distinct results, which are highlighted in Table 2. For the WikiText-2 dataset, which measures the model’s perplexity (lower is better), and the GSM8K dataset, which tests the model’s ability to solve basic math problems (higher is better), we demonstrate the effectiveness of varying degrees of weight simplification—averaging 3, 2.5, and 2.25 bits per weight. Our paper discusses the results in more detail.
Microsoft research podcast

Collaborators: Silica in space with Richard Black and Dexter Greene
College freshman Dexter Greene and Microsoft research manager Richard Black discuss how technology that stores data in glass is supporting students as they expand earlier efforts to communicate what it means to be human to extraterrestrials.
Implications and looking forward
LoftQ promises to advance the field of AI by accelerating research and facilitating the creation of cutting-edge tools while supporting sustainable development. While initially focused on LLMs, LoftQ’s flexible design also supports fine-tuning in other types of models, such those for vision and speech technologies. As our research progresses, we expect to make further enhancements that will boost performance on downstream tasks. We hope these improvements will lead to broader adoption across various AI applications. We’re excited about the breadth of this technology’s applicability and encourage the AI community to explore its benefits. LoftQ is available as open source through the Hugging Face PEFT library (opens in new tab).



