Teaching is super important. From an individual perspective, a student learning on his or her own is never ideal; a student needs a teacher’s guidance and perspective to be more effectively educated. Taking the societal perspective, teaching enables civilization to be passed on to the next generation. Human teachers have three concrete responsibilities: providing students with qualified teaching material (for example, textbooks); defining the appropriate skill set to be mastered by the students (for example, algebra skills or advanced calculus); and setting suitable learning objectives (for example, course projects and exams) in order to evaluate how well the students are learning, and based on which feedback can be provided to students.
The human teacher and student learning process happens to make a good analogy for understanding artificial intelligence and machine learning problems. Figure 1 illustrates the basic components of a typical machine learning process. It is an optimization process including the training data D, a specific model space Ω and the loss function L.
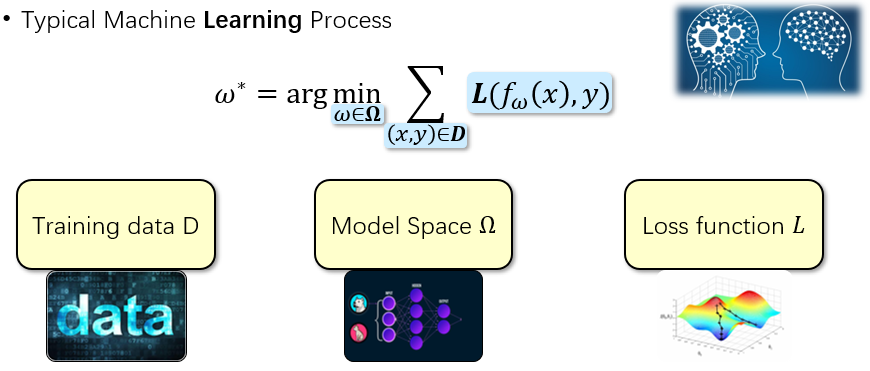
Figure 1 – The typical machine learning process.
Spotlight: Blog post

Research Focus: Week of September 9, 2024
Investigating vulnerabilities in LLMs; A novel total-duration-aware (TDA) duration model for text-to-speech (TTS); Generative expert metric system through iterative prompt priming; Integrity protection in 5G fronthaul networks.
Figure 2 describes an analogy between human teaching and teaching in AI, incorporating the aforementioned three responsibilities of teachers. First, proper training data must be chosen for the AI student, akin to the textbooks chosen by teachers. We call this data teaching. Second, a good student model hypothesis space needs to be designed, similar to the skillset to be taught to human students. We call this model space teaching. Third, appropriate loss functions must be set to optimize student models, similar to the exams designed by human teachers. We call this loss function teaching.

Figure 2 – An analogy of human teaching and teaching for AI.
We proposed an effective and efficient framework called “Learning to Teach” (L2T), published at ICLR this year. In L2T, we aimed to discover the best teaching strategy for AI using a completely automatic approach that takes into consideration the different abilities of various students, while maintaining the mutual growth of students and teachers. We demonstrated that an optimal data order can be discovered via L2T, successfully reducing training data by 40 percent for student model learning. At NeurIPS 2018, we extended the L2T framework from data teaching to loss function teaching; please refer to our paper, Learning to Teach with Dynamic Loss Functions (opens in new tab).
The goal of the loss function teaching is to automatically discover the best loss function to train the student model and ultimately improve the student model’s performance. We set two requirements for the loss function teaching. An adaptive requirement that states that the machine teachers should set different loss functions along with the different training phases of student model training. And a dynamic requirement—the machine teachers should optimize themselves to constantly enhance teaching ability to achieve co-growth with student model. To satisfy these two requirements, we set the loss function to be a neural network Lϕ (fω (x), y) with ϕ as its coefficient, and we used a teacher model μθ to dynamically set the coefficient ϕt by considering the student training status st. Then the student model is guided via the dynamic loss functions output via the teacher model at different timestep t, as shown in Figure 3.

Figure 3 – The training process of the student model (shown by the yellow line in the bottom 2d surface), under the guidance of different loss functions (the colored mesh surface), output via the teacher model.
In addition, we designed an effective optimization method for the teacher model μθ based on reverse mode differentiation. With this method, we achieved gradient based optimization instead of using the expensive reinforcement learning or evolutionary computing-based methods. We verified our approach both on image classification tasks and neural machine translation tasks. On CIFAR-10, CIFAR-100 image classification task and on IWSLT-14 German-English translation task, we achieved significant improvement compared with original cross entropy loss function and other proposed static loss functions, which clearly shows the effectiveness of our adaptive and dynamic loss functions.
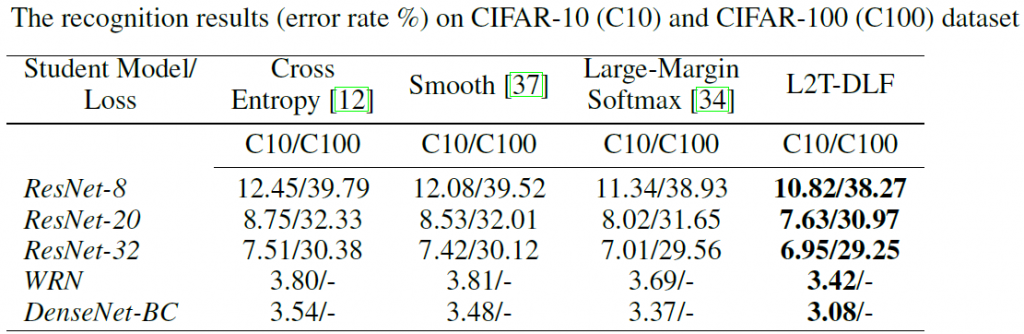
![]()
In summary, in this work we extended the “Learning to Teach” framework to the automatic design of loss function. Through careful inspection of human teaching and efficient optimization algorithms, it’s possible to discover the best adaptive and dynamic loss functions to train a deep neural network that can achieve impressive performances. We anticipate that in the future, there is great potential for L2T, both in terms of theoretical justification and empirical evidence.