

In computer vision, one key property we expect of an intelligent artificial model, agent, or algorithm is that it should be able to correctly recognize the type, or class, of objects it encounters. This is critical in numerous important real-world scenarios—from biomedicine, where an intelligent system might be tasked with distinguishing between cancerous cells and healthy ones, to self-driving cars, where being able to discriminate between pedestrians, other vehicles, and road signs is crucial to successfully and safely navigating roads.
Deep learning is one of the most significant tools for state-of-the-art systems in computer vision, and its use has resulted in models that have reached or can even exceed human-level performance in important and challenging real-world image classification tasks. Despite their successes, these models still have difficulty generalizing, or adapting to tasks in testing or deployment scenarios that don’t closely resemble the tasks they were trained on. For example, a visual system trained under typical weather conditions in Northern California may fail to properly recognize pedestrians in Quebec because of differences in weather, clothes, demographics, and other features. As it’s difficult to predict—if not impossible to collect—all the possible data that might be present at deployment, there’s a natural interest in testing model classification performance under deployment scenarios in which very few examples of test classes are available, a scenario captured under the framework of few-shot learning. Zero-shot learning (ZSL) goes a step further: No examples of test classes are available when training. The model must instead rely on semantic information, such as attributes or text descriptions, associated with each class it encounters in training to correctly classify new classes.
Microsoft Research Blog

Microsoft Research Forum Episode 3: Globally inclusive and equitable AI, new use cases for AI, and more
In the latest episode of Microsoft Research Forum, researchers explored the importance of globally inclusive and equitable AI, shared updates on AutoGen and MatterGen, presented novel use cases for AI, including industrial applications and the potential of multimodal models to improve assistive technologies.
Humans express a remarkable ability to adapt to unfamiliar situations. From a very young age, we’re able to reason about new categories of objects by leveraging already existing information about related objects with similar attributes, parts, or properties. For example, upon being exposed to a zebra for the first time, a child might reason about it using her prior knowledge that stripes are a type of pattern and that a horse is an animal with similar characteristics and shape. This type of reasoning is intuitive and, we hypothesize, reliant mainly on two key concepts: locality, loosely defined as being dependent on local information, or small parts of the whole, and compositionality, arising from a combination of simpler parts or other characteristics, such as color, to determine the new objects we encounter. In the paper “Locality and Compositionality In Zero-Shot Learning,” (opens in new tab) which was accepted to the eighth International Conference on Learning Representations (ICLR2020) (opens in new tab), we demonstrate that representations that focus on compositionality and locality are better at zero-shot generalization. Considering how to apply these notions in practice to improve zero-shot learning performance, we also introduce Class-Matching DIM (CMDIM), a variant of the popular unsupervised learning algorithm Deep InfoMax, which results in very strong performance compared to a wide range of baselines.
Exploring locality and compositionality
In the field of representation learning, a locally aware representation can broadly be defined as one that retains local information. For example, in an image of a bird, relevant local information could be the beak, wings, feathers, tail, and so on, and a local representation might be one that encodes one or some of these parts, as well as their relative position in the whole image. A representation is compositional if it can be expressed as a combination of representations of these important parts, but also other important “facts” about the image, such as color, background, and other environmental factors or even actions. However, it’s difficult to determine whether a model is local or compositional without the help of human experts. To efficiently explore the role of these traits in learning good representations for zero-shot learning, we introduce proxies reliant on human annotations to measure these characteristics.
- We use supervised parts classification as a proxy for locality: On top of a representation, we train a parts localization module that tries to predict where the important parts are in the image and measure the module’s performance without backpropagating through the encoder. We then use the resulting classification F1 score as a proxy for locality. The core idea here is that if we’re able to correctly identify where a part is located—and where it’s not—the model must be encoding information on local structure.
- For compositionality, we rely on the TRE ratio, a modification of the tree reconstruction error (TRE) (opens in new tab). The TRE ratio measures how a representation differs from a perfectly compositional one according to a simple linear model. Rather than simply consider the TRE, we considered the ratio of the TRE computed with the actual attributes and the TRE computed with random attributes. This normalization makes it easier to compare different families of models, some of which are inherently more decomposable according to any sets of attributes.
Using the above proxies, in addition to others, as a method of evaluation, we analyze locality and compositionality in encoders trained using a diverse set of representation learning methods:
- fully supervised classifiers trained from scratch (FC)
- unsupervised generative methods: variational autoencoders (VAEs)/beta-VAEs, adversarial autoencoders (AAEs), and generative adversarial networks (GANs)
- mutual-information based methods: Deep InfoMax (DIM) and Augmented Multiscale DIM (AMDIM)
In addition to existing methods, we created the mutual-information based method CMDIM, for which positive samples, or good examples, are drawn from the set of images of the same class. Using our analyses on these representation learning methods gives us insight on and allows us to evaluate how well they “score” with respect to locality and compositionality.
Zero-shot learning from scratch
To tie this all together to generalization, we evaluate each of these models on the downstream task of zero-shot learning. However, because state-of-the-art ZSL in computer vision also relies heavily on pre-training from large-scale datasets like ImageNet, it’s more difficult to draw conclusions on the role of locality and compositionality on fundamental representation learning principles that aid in ZSL performance.
As such, we introduce a stricter ZSL setting defined as zero-shot learning from scratch (ZSL-FS), where we don’t use pre-trained models and instead rely on only the data in the training set to train an encoder. We use this setting for multiple reasons: It enables us to focus on the question of whether the representation learned by an encoder is robust to the ZSL setting, as well as extends the insights of our paper to settings in which pre-trained encoders don’t exist or result in poor performance, such as in the field of medical imaging or audio signals.
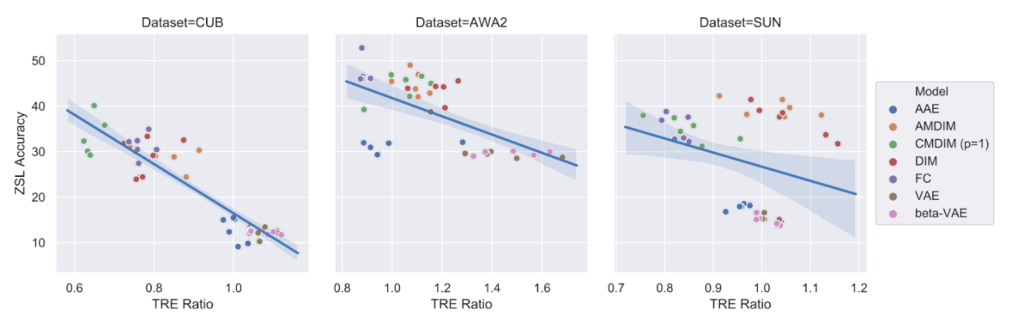
The results: Locality, compositionality, and improved ZSL accuracy
As shown in Figure 2 above, there is a very strong link between zero-shot learning accuracy and TRE ratio that holds across encoders and datasets. We used three datasets: Caltech-UCSD Birds-200-2011 (CUB) (opens in new tab), Animals with Attributes 2 (AWA2) (opens in new tab), and SUN Attribute (opens in new tab). It’s interesting to note the correlation is weaker for the SUN dataset, for which the attributes carry less semantic meaning (being the result of averaging per-instance attributes across classes).
While the TRE ratio focuses on implicit compositionality, as measured by a simple linear model, we can also consider the case of an explicitly compositional model. This refers to a model that is by definition compositional because it first learns part representations and then combines them. We run a second set of experiments to investigate this. In this set of experiments, we compare the performance of a model averaging part representations (the parts are local patches of the image) with a model averaging predictions (an ensemble). We show that the explicitly compositional model outperforms the non-compositional one across model families.
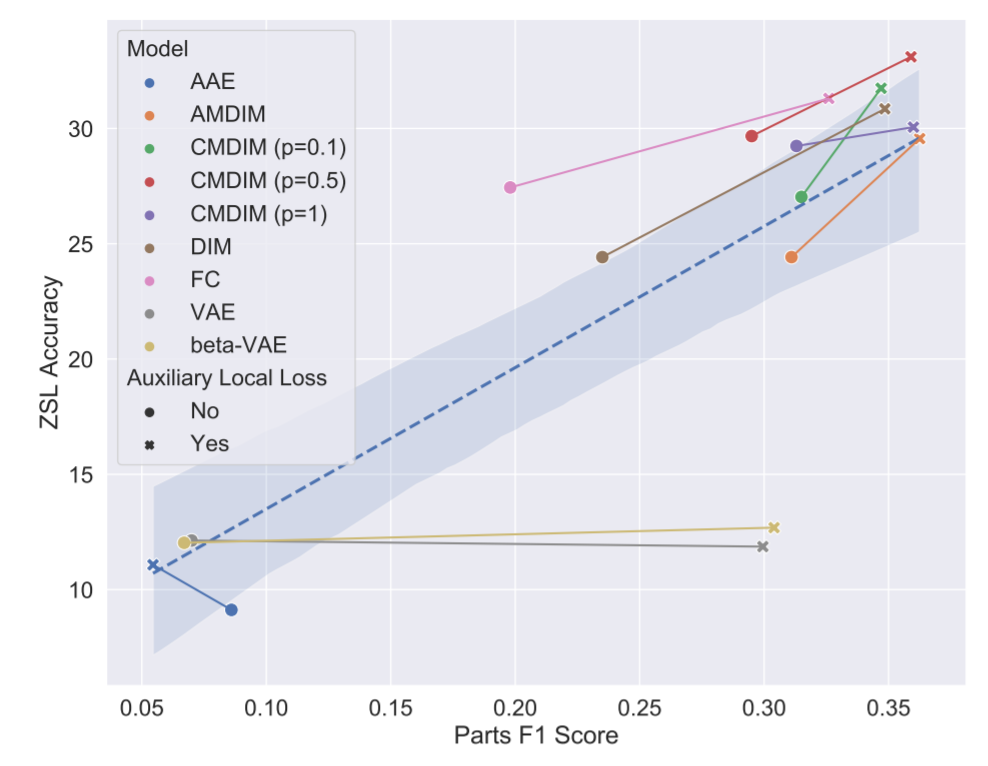
Concerning locality, there’s also a clear relationship between parts F1 score and zero-shot learning accuracy. The better an encoder’s understanding of local information is, indicated by a higher parts F1 score, the better its ZSL performance. This relationship breaks down for reconstruction-based models (AAEs and VAEs, in our case), which seem to focus on capturing pixel-level information rather than semantic information. We used a visualization technique based on mutual information heat maps to estimate where the encoder focuses. The technique revealed that AAEs and VAEs, contrary to the other families of models, have trouble finding semantically relevant parts of an image, such as wings or the contour of the bird, and instead focus on the whole image.
In conclusion, these findings around the relationship between accuracy and locality and compositionality will hopefully provide researchers with a more principled approach to zero-shot learning, one that focuses on these concepts when designing new methods. In future work, we aim to investigate how locality and compositionality impact other zero-shot tasks, such as zero-shot semantic segmentation.



