Large pre-trained language models such as GPT-3, Codex, and others can be tuned to generate code from natural language specifications of programmer intent. Such automated models have the potential to improve productivity for every programmer in the world. But since the models can struggle to understand program semantics, the quality of the resulting code can’t be guaranteed.
In our research paper, Jigsaw: Large Language Models meet Program Synthesis (opens in new tab), which has been accepted at the International Conference on Software Engineering (opens in new tab) (ICSE 2022), we introduce a new tool that can improve the performance of these large language models. Jigsaw deploys post-processing techniques that understand the programs’ syntax and semantics and then leverages user feedback to improve future performance. Jigsaw is designed to synthesize code for Python Pandas API using multi-modal inputs.
Our experience suggests that as these large language models evolve for synthesizing code from intent, Jigsaw can play an important role in improving the accuracy of the systems.
The promise, and perils, of machine-written software
Large language models like OpenAI’s Codex are redefining the landscape of programming. A software developer, while solving a programming task, can provide a description in English for an intended code fragment and Codex can synthesize the intended code in languages like Python or JavaScript. However, the synthesized code might be incorrect and might even fail to compile or run. Codex users are responsible for vetting the code before using it. With Project Jigsaw, we aim to automate some of this vetting to boost the productivity of developers who are using large language models like Codex for code synthesis.
- Project Project Jigsaw
Suppose Codex provides a code fragment to a software developer. The developer might then undertake a basic vetting by checking whether the code compiles. If it doesn’t compile, then the developer might be able to use the error messages of the compiler to repair it. Once the code eventually does compile, a typical developer will test it on an input to check whether the code is producing the intended output or not. Again, the code might fail (raise an exception or produce incorrect output) and the developer would need to repair it further. We show that this process can be completely automated. Jigsaw takes as input an English description of the intended code, as well as an I/O example. In this way, it pairs an input with the associated output, and provides the quality assurance that the output Python code will compile and generate the intended output on the provided input.
In our ICSE 2022 paper, Jigsaw: Large Language Models meet Program Synthesis, we evaluate this approach on Python Pandas. Pandas is a widely used API in data science, with hundreds of functions for manipulating dataframes, or tables with rows and columns. Instead of asking a developer to memorize the usage of all these functions, an arguably better approach is to use Jigsaw. With Jigsaw, the user provides a description of the intended transformation in English, an input dataframe, and the corresponding output dataframe, and then lets Jigsaw synthesize the intended code. For example, suppose a developer wants to remove the prefix “Name: ” from the column “country” in the table below. Using Pandas, this can be solved performing the following operation:
df['c'] = df['c'].str.replace('Name: ', '')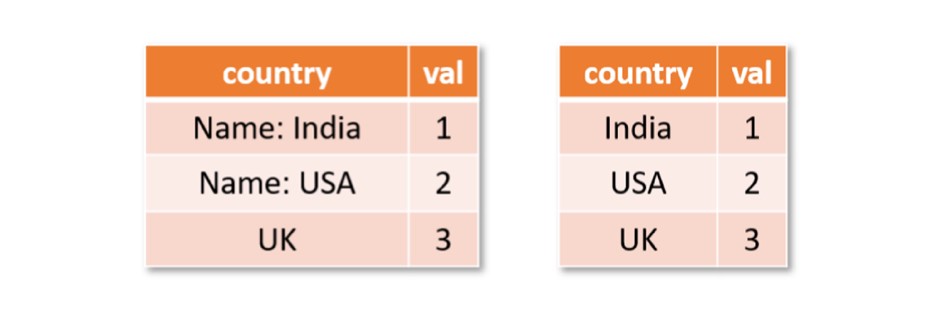
A developer who is new to Pandas will need to figure out the functions and their arguments to put together this code fragment or post the query and example to a forum like StackOverflow and wait for a good Samaritan to respond. In addition, they might have to tweak the response, at times considerably, based on the context. In contrast, it is much more convenient to provide the English query with an input-output table (or dataframe).
How Jigsaw works
Jigsaw takes the English query and pre-processes it with appropriate context to build an input that can be fed to a large language model. The model is treated as a black box and Jigsaw has been evaluated both with GPT-3 and Codex. The advantage of this design is that it enables plug-and-play with the latest and greatest available models. Once the model generates an output code, Jigsaw checks whether it satisfies the I/O example. If so, then Jigsaw is done! The model output is already correct. In our experiments, we found this happened about 30% of the time. If the code fails, then the repair process starts in a post-processing phase.
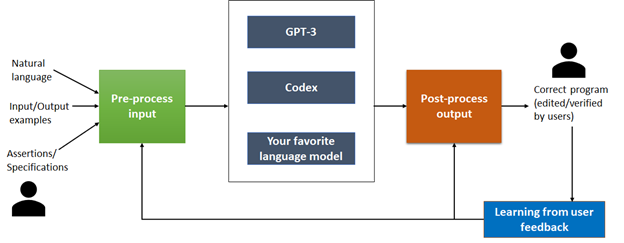
During post-processing, Jigsaw applies three kinds of transformations to repair the code. Each of these transformations is motivated by the failure modes that we have observed in GPT-3 and Codex. Surprisingly, both GPT-3 and Codex fail in similar ways and hence Jigsaw’s post-processing to address these failure modes is useful for both.
Spotlight: blog post

GraphRAG auto-tuning provides rapid adaptation to new domains
GraphRAG uses LLM-generated knowledge graphs to substantially improve complex Q&A over retrieval-augmented generation (RAG). Discover automatic tuning of GraphRAG for new datasets, making it more accurate and relevant.
Variable transformations
We have observed that Codex can produce output that uses incorrect variable names. For example, most publicly available code uses names like df1, df2, etc. for dataframes. So, the Codex output also uses these names. Now, if the developer uses g1, g2, etc. as dataframe names, the Codex output is probably going to use df1, df2, etc. and fail. Other times Codex confuses variable names provided to it. For instance, it produces df2.merge(df1)instead of df1.merge(df2). To fix these kinds of errors, Jigsaw replaces names in Codex generated code with all possible names in the scope until it finds a program that satisfies the I/O example. We find this simple transformation to be quite useful in many cases.
Argument transformations
Sometimes Codex generated code calls the expected API functions but with some of the arguments incorrect. For example:
a.) Query – Drop all the rows that are duplicated in column ‘inputB’
dfout = dfin.drop_duplicates(subset=['inputB']) # Model
dfout = dfin.drop_duplicates(subset=['inputB'],keep=False) # Correctb.) Query – Replace Canada with CAN in column country of df
df = df.replace({'Canada':'CAN'}) # Model
df = df.replace({'country':{'Canada':'CAN'}) # CorrectTo fix such errors, Jigsaw systematically enumerates over all possible arguments, using the function and argument sequences generated by Codex as a starting point, until it finds a program that satisfies the I/O example.
AST-to-AST transformations
An AST (abstract-syntax-tree) is a representation of code in the form of a tree. Since models like Codex work at a syntactic level, they might produce code which is syntactically very close to the intended program, but some characters might be incorrect. For example:
a.) Query – Select rows of dfin where value in bar is <38 or >60
dfout = dfin[dfin['bar']<38|dfin['bar']>60] # Model
dfout = dfin[(dfin['bar']<38)|(dfin['bar']>60)] # CorrectMistake – missing parentheses change precedence and cause exception
b.) Query – Count the number of duplicated rows in df
out = df.duplicated() # Model
out = df.duplicated().sum() # CorrectMistake – missing required summation to get the count
To fix this failure mode, Jigsaw provides AST-to-AST transformations that are learned over time. The user would need to fix the code themselves — then the Jigsaw UI will capture the edit, generalize the edit to a more widely applicable transformation, and learn this transformation. With usage, the number of transformations increases, and Jigsaw becomes more and more effective.
Evaluation
We evaluated Codex and Jigsaw (with Codex) on various datasets and measured accuracy, which is the percentage of tasks in the dataset where the system produces the intended result. Codex gives an accuracy of about 30% out-of-the-box, which is what is expected from OpenAI’s paper (opens in new tab) as well. Jigsaw improves the accuracy to >60% and, through user feedback, the accuracy improves to >80%.
The road ahead
We have released the datasets that we used to evaluate Jigsaw in the public domain. Each dataset includes multiple tasks, where each task has an English query and an I/O example. Solving a task requires generating a Pandas code that maps the input dataframe provided to the corresponding output dataframe. We hope that this dataset will help evaluate and compare other systems. Although there are datasets where the tasks have only English queries or only I/O examples, the Jigsaw datasets are the first to contain both English queries and the associated I/O examples.
As these language models continue to evolve and become more powerful, we believe that Jigsaw will still be required for providing the guardrails and making these models viable in real-world scenarios. This is just addressing the tip of the iceberg for research problems in this area and many questions remain to be answered:
- Can these language models be trained to learn semantics associated with code?
- Can better preprocessing and postprocessing steps be integrated into Jigsaw? For example, we are looking at static analysis techniques to improve the post-processing.
- Are I/O examples effective for other APIs apart from Python Pandas? How do we tackle scenarios where I/O examples are not available? How do we adapt Jigsaw for languages like JavaScript and general code in Python?
- The developer overhead of providing an example over just providing a natural language query needs further evaluation and investigation.
These are some of the interesting directions we are pursuing. As we refine and improve Jigsaw, we believe it can play an important role in improving programmer productivity through automation. We continue to work on generalizing our experience with the Python Pandas API to work across other APIs and other languages.
Other contributors:
Naman Jain (opens in new tab), Research fellow at Microsoft Research India Lab
Skanda Vaidyanath (opens in new tab), Intern at Microsoft Research India Lab, currently pursuing master’s degree at Stanford