Editor’s note: Since 2018, pre-training has without a doubt become one of the hottest research topics in Natural Language Processing (NLP). By leveraging generalized language models like the BERT, GPT and XLNet, great breakthroughs have been achieved in natural language understanding. However, in sequence to sequence based language generation tasks, the popular pre-training methods have not achieved significant improvements. Now, researchers from Microsoft Research Asia have introduced MASS—a new pre-training method that achieves better results than BERT and GPT.
BERT and XLNet have achieved great success in natural language understanding tasks (for example, sentiment classification, natural language inference, and SQuAD machine reading comprehension). However, besides natural language understanding tasks in NLP, there are other sequence to sequence based language generation tasks, such as neural machine translation, abstract summarization, conversational response generation, question answering, and text style transfer. For these tasks, encoder-attention-decoder is the dominant approach.

(opens in new tab) Figure 1: The Encoder-Attention-Decoder framework.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
As shown in Figure 1, the encoder takes the source sequence X as input and transforms it into a sequence of hidden representations, and then the decoder extracts the hidden representations from the encoder through an attention mechanism and generates a target sequence Y autoregressively.
BERT and XLnet pre-train an encoder for natural language understanding, while GPT pre-trains a decoder for language modeling. We usually have to pre-train the encoder and decoder separately when leveraging BERT and GPT for sequence to sequence based language generation tasks. In such circumstances, the encoder-attention-decoder framework and the attention mechanism cannot be jointly trained. However, the attention mechanism is extremely important in these kinds of tasks and hinders BERT and GPT in achieving optimal performance.
A new pre-training method
With sequence to sequence based language generation tasks in mind, the Machine Learning Group at Microsoft Research Asia envisioned a new pre-training method. We called it MASS: Masked Sequence to Sequence Pre-training. MASS randomly masks a sentence fragment with length k and predicts this masked fragment through an encoder-attention-decoder framework.

(opens in new tab) Figure 2: MASS framework.
As shown in the Figure 2, the 3rd-6th tokens of the sentence on the encoder side are masked, while on the decoder side, only the masked tokens are predicted and the other tokens are masked.
MASS pre-training brings the following advantages:
- The other tokens on the decoder side (the tokens that are not masked on the encoder side) are masked, which can encourage the decoder to extract more information to help with the prediction of the sentence fragment. As a result, the encoder-attention-decoder is forced to be jointly pre-trained;
- In order to provide more useful information for the decoder, the encoder is forced to extract the meaning of the unmasked tokens on the encoder side, which can improve the capability of the encoder in language understanding;
- The decoder is designed to predict consecutive tokens (sentence fragments), which can improve the language modeling capability of the decoder.
General pre-training framework
MASS possesses an important hyperparameter k (the length of the masked fragment). By adjusting k, MASS can incorporate the masked language modeling in BERT and the standard language modeling in GPT, which extends MASS into a general pre-training framework.
When k=1, according to the design of MASS, one token on the encoder side is masked, and the decoder side predicts this masked token, as shown in Figure 3. The decoder side has no input information and MASS is equivalent to the masked language model in BERT.

(opens in new tab) Figure 3: k=1. One token on encoder side is masked; the decoder side predicts the masked token.
When k=m (m is the length of the sequence), in MASS all tokens on the encoder side are masked, and the decoder side predicts all tokens, as shown in Figure 4. The decoder side cannot extract any information from the encoder side, and MASS is equivalent to the standard language model in GPT.

(opens in new tab) Figure 4: k=m. All tokens on encoder side are masked; the decoder side predicts all tokens, just as in GPT.
The probability formulations of MASS under different values of k are shown in Table 1, where m is the length of the sequence, u and v are the start and end positions of the masked fragment respectively, Χu:v represents the fragment from position u to v, and X\u:v represents the sequence where the tokens from position u to v are masked. It can be seen that when k=1 or m, the probability formulation of MASS is equivalent to the masked language model in BERT and the standard language model in GPT.

(opens in new tab) Table 1: Probability formulations of MASS under different values of k.
We conducted experiments to analyze the performance of MASS with different values of k, as shown in Figure 5.

(opens in new tab) Figure 5: MASS performance under various masked length k, both in pre-training and fine-tuning stages, including PPL of pretrained model on English sentences (a), and French sentences (b) from WMT newstest2013 on English-French translation; the BLEU score of unsupervised English-French translation on WMT newstest2013 (c); the ROUGE score (F1 score in RG-2) on the validation set of text summarization (d); and the PPL on the validation set of conversational response generation (e).
When k equals half the sentence length, the downstream tasks can reach their best performance. Masking half the sentence can provide good balance in the pre-training of the encoder and decoder. Bias to the encoder (k=1, BERT), on the other hand, or bias to the decoder (k=m, LM/GPT) does not deliver good performance. This shows the advantages of MASS in sequence to sequence based language generation tasks.
Experimenting on sequence-to-sequence-based language generation tasks
Pre-training
Notably, MASS only requires unsupervised monolingual data for pre-training (for example, WMT News Crawl Data or Wikipedia Data). MASS supports both cross-lingual tasks (for example, neural machine translation) and monolingual tasks (abstractive summarization and conversational response generation). When pre-training for cross-lingual tasks such as English-French translation, we pre-trained both English-English and French-French in one model, with an additional language embedding to differentiate between the languages. We fine-tuned MASS on unsupervised machine translation, low-resource machine translation, abstractive summarization and conversational response generation to verify its effectiveness.
Unsupervised machine translation
We compared MASS with previous methods, including the previous state-of-the-art method, Facebook XLM, on unsupervised machine translation tasks. XLM uses a masked language model in BERT and a standard language model to pre-train the encoder and decoder separately. As shown in Table 2, MASS outperforms XLM in six translation directions on WMT14 English-French, WMT16 English-German and English-Romanian, and achieves new state-of-the-art results.
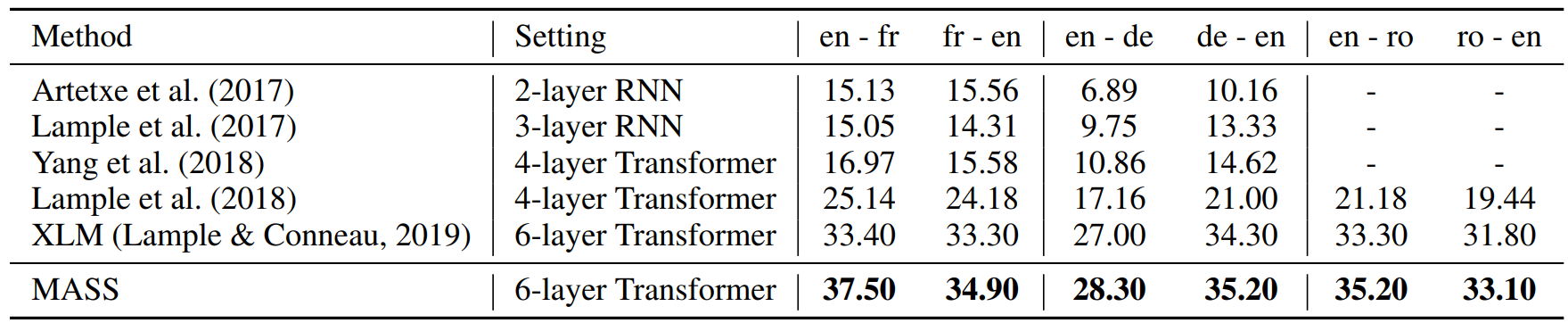
(opens in new tab) Table 2: BLEU score comparisons between MASS and previous work on unsupervised NMT. Results on en-fr and fr-en pairs reported on newstest2014; others are on newstest2016. Because XLM uses different combinations of MLM and CLM in the encoder and decoder, we report the highest BLEU score for XLM on each language pair.
Low-resource machine translation
Low-resource machine translation refers to machine translation with limited bilingual training data. We simulated a low-resource scenario on WMT14 English-French, WMT16 English-German and English-Romanian translation (10K, 100K, and 1M bilingual data respectively).

(opens in new tab) Figure 6: The BLEU score comparisons between MASS and the baseline on low-resource NMT with different scales of paired data.
Figure 6 shows MASS outperforms the low-resource baseline on different data scales and the improvement becomes larger with fewer bilingual data.
Abstractive Summarization
We compared MASS with BERT+LM (with the encoder pretrained with BERT and decoder pre-trained with LM) and DAE (Denoising Auto-Encoder) on the Gigaword Corpus. As can be seen in Table 3, MASS outperformed both BERT+LM and DAE.
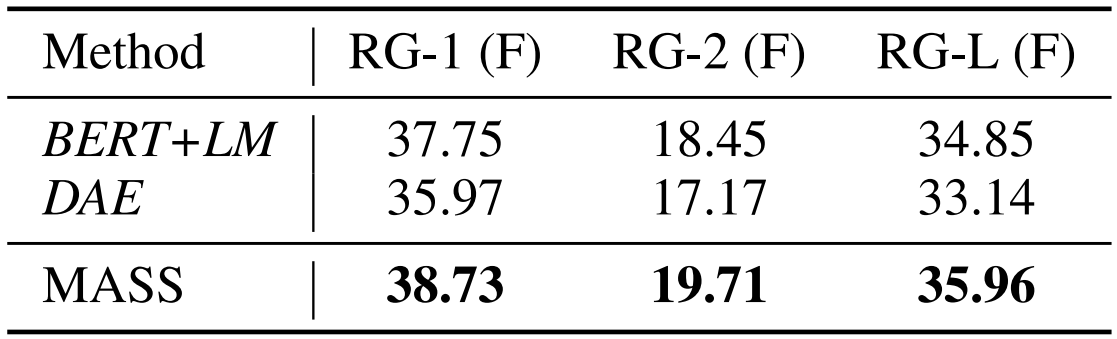
(opens in new tab) Table 3: Comparisons between MASS and two pre-training methods for ROGUE score on text summarization task on the whole 3.8M training data.
Conversational response generation
We compared MASS with BERT+LM on Cornell Movie Dialog Corpus. Table 4 shows that MASS achieved lower PPL than BERT+LM and the baseline without any pre-training.
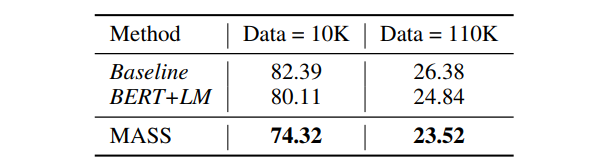
(opens in new tab) Table 4: Comparisons between MASS and other baseline methods for PPL on Cornell Movie Dialog corpus.
MASS consistently achieves significant gains on different sequence to sequence based language generation tasks. We are looking forward to testing the performance of MASS on natural language understanding tasks. Future work includes applying MASS to other sequence to sequence based generation tasks in the image and video domains.
For more details, we invite you to peruse our paper, “MASS: Masked Sequence to Sequence Pre-training for Language Generation (opens in new tab)”. Our source code and the pre-trained models are also available on GitHub (opens in new tab). We welcome your feedback!