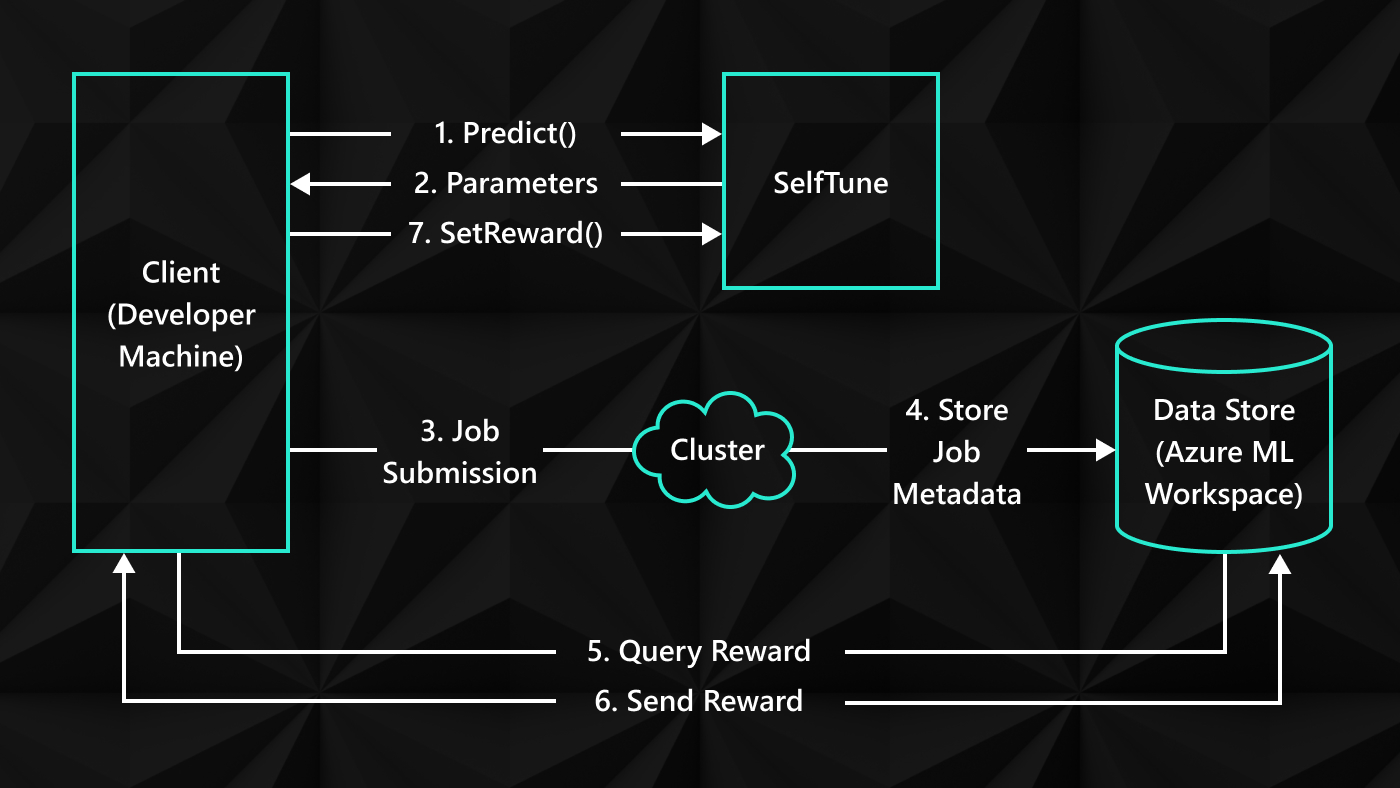
Researchers at Microsoft have been working for nearly a decade to address the increasing demand for data storage mechanisms to support the rapid advances in interactive web applications and services. Our new cache-store system called Garnet, which offers several advantages over legacy cache-stores, has been deployed in multiple use cases at Microsoft, such as those in the Windows & Web Experiences Platform, Azure Resource Manager, and Azure Resource Graph, and is now available as an open-source download at https://github.com/microsoft/garnet (opens in new tab). In open sourcing Garnet, we hope to enable the developer community to benefit from its performance gains and capabilities, to build on our work, and to expand the Garnet ecosystem by adding new API calls and features. We also hope that the open sourcing will encourage follow-up academic research and open future collaboration opportunities in this important research area.
The cache-store problem
The growth of cloud and edge computing has brought an increasing number and range of applications and services that need to access, update, and transform data with higher efficiency, lower latencies, and lower costs than ever before. These applications and services often require significant operational spending on storage interactions, making this one of the most expensive and challenging platform areas today. A cache-store software layer, deployed as a separately scalable remote process, can ease these costs and improve application performance. This has fueled a growing cache-store industry, including many open-source systems, such as Redis, Memcached, KeyDB, and Dragonfly.
Unlike traditional remote cache-stores, which support a simple get/set interface, modern caches offer rich APIs and feature sets. They support raw strings, analytic data structures such as Hyperloglog, and complex data types such as sorted sets and hash. They allow users to checkpoint and recover the cache, create data shards, maintain replicated copies, and support transactions and custom extensions.
Spotlight: blog post

GraphRAG auto-tuning provides rapid adaptation to new domains
GraphRAG uses LLM-generated knowledge graphs to substantially improve complex Q&A over retrieval-augmented generation (RAG). Discover automatic tuning of GraphRAG for new datasets, making it more accurate and relevant.
However, existing systems achieve this feature richness at a cost, by keeping the system design simple, which limits the ability to fully exploit the latest hardware capabilities (e.g., multiple cores, tiered storage, fast networks). Further, many of these systems are not explicitly designed to be easily extensible by app developers or to work well on diverse platforms and operating systems.
Introducing Garnet
At Microsoft Research, we have been investigating modern key-value database architectures since 2016. Our prior work, the FASTER (opens in new tab) embedded key-value library, which we open-sourced (opens in new tab) in 2018, demonstrated orders-of-magnitude better performance than existing systems, while focusing on the simple single-node in-process key-value model.
Starting in 2021, based on requirements from use-cases at Microsoft, we began building a new remote cache-store with all the necessary features to serve as a viable replacement to existing cache-stores. Our challenge was to maintain and enhance the performance benefits that we achieved in our earlier work, but in this more general and realistic network setting.
The result of this effort is Garnet – a new cache-store that offers several unique benefits:
- Garnet adopts the popular RESP wire protocol as a starting point, which makes it possible to use Garnet from unmodified Redis clients available in most programming languages today.
- Garnet offers much better scalability and throughput with many client connections and small batches, leading to cost savings for large apps and services.
- Garnet demonstrates better client latency at the 99th and 99.9th percentiles, which is critical to real-world scenarios.
- Based on the latest .NET technology, Garnet is cross-platform, extensible, and modern. It is designed to be easy to develop for and evolve, without sacrificing performance in the common case. We leveraged the rich library ecosystem of .NET for API breadth, with open opportunities for optimization. Thanks to our careful use of .NET, Garnet achieves state-of-the-art performance on both Linux and Windows.

API features: Garnet supports a wide range of APIs including raw string, analytical, and object operations described earlier. It also implements a cluster mode with sharding, replication, and dynamic key migration. Garnet supports transactions in the form of client-side RESP transactions (opens in new tab) and our own server-side stored procedures in C# and allows users to define custom operations on both raw strings and new object types, all in the convenience of C#, leading to a lower bar for developing custom extensions.
Network, storage, cluster features: Garnet uses a fast and pluggable network layer, enabling future extensions such as leveraging kernel-bypass stacks. It supports secure transport layer security (TLS) communications as well as basic access control. Garnet’s storage layer, called Tsavorite, was forked from OSS FASTER, and includes strong database features such as thread scalability, tiered storage support (memory, SSD, and cloud storage), fast non-blocking checkpointing, recovery, operation logging for durability, multi-key transaction support, and better memory management and reuse. Finally, Garnet supports a cluster mode of operation – more on this later.
Performance preview
We illustrate a few key results comparing Garnet to leading open-source cache-stores. A more detailed performance comparison can be found on our website at https://microsoft.github.io/garnet/ (opens in new tab).
We provision two Azure Standard F72s v2 virtual machines (72 vcpus, 144 GiB memory each) running Linux (Ubuntu 20.04), with accelerated TCP enabled. One machine runs different cache-store servers, and the other is dedicated to issuing workloads. We use our own benchmarking tool, called Resp.benchmark (opens in new tab), to generate all results. We compare Garnet to the latest open-source versions of Redis (opens in new tab) (v7.2), KeyDB (opens in new tab) (v6.3.4), and Dragonfly (opens in new tab) (v6.2.11). We use a uniform random distribution of keys in these experiments (Garnet’s shared memory design benefits even more with skewed workloads). The data is pre-loaded onto each server, and fits in memory in these experiments.
Experiment 1: Throughput with varying number of client sessions
We start with large batches of GET operations (4096 requests per batch) and small payloads (8-byte keys and values) to minimize network overhead and compare the systems as we increase the number of client sessions. We see from Figure 1 that Garnet exhibits better scalability than Redis and KeyDB, while achieving higher throughput than all three baseline systems (the y-axis is log scale). Note that, while Dragonfly shows similar scaling behavior as Garnet, it is a pure in-memory system. Further, Garnet’s throughput relative to other systems remains strong when the database size (i.e., the number of distinct keys pre-loaded) is significantly larger, at 256 million keys, than what would fit in the processor caches.
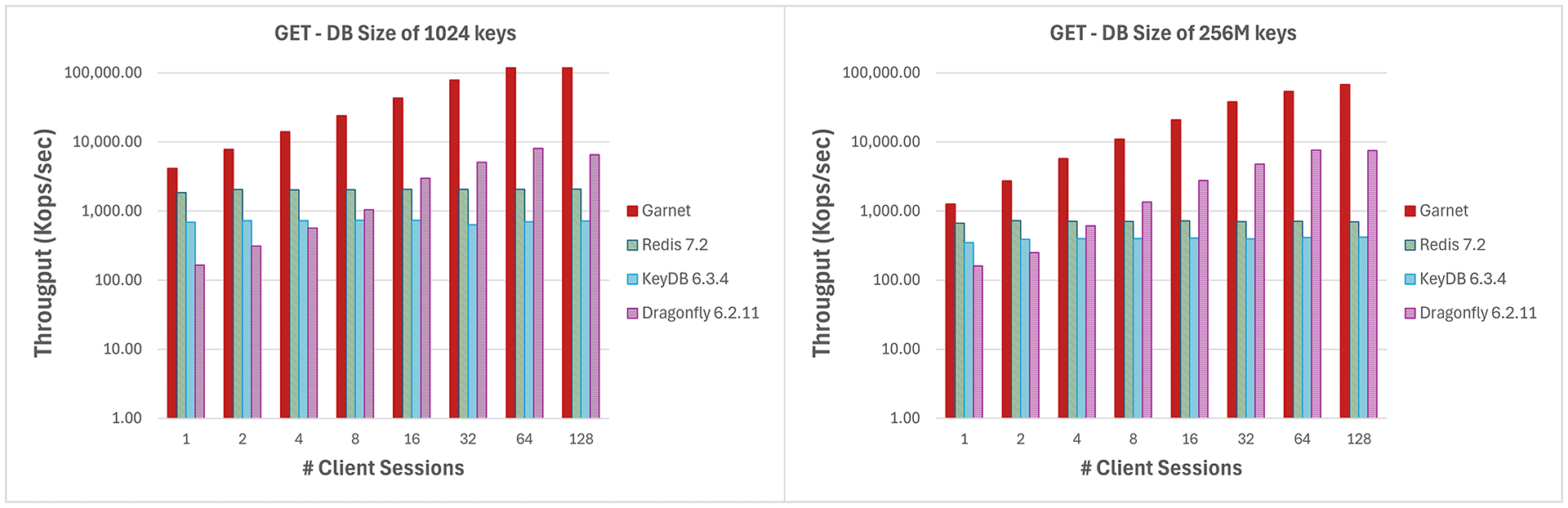
Experiment 2: Throughput with varying batch sizes
We next vary the batch size, with GET operations and a fixed number (64) of client sessions. We experiment with two different database sizes as before. Figure 2 shows that Garnet performs better even with no batching, and the gap increases even for very small batch sizes. Payload sizes are the same as before. Again, the y-axis is log scale.

Experiment 3: Latency with varying number of client sessions
We next measure client-side latencies for the various systems. Figure 3 shows that, as we increase the number of client sessions, Garnet’s latency (measured in microseconds) at various percentiles stays much more stable and lower as compared to other systems. Here, we issue a mix of 80% GET and 20% SET operations, with no operation batching.

Experiment 4: Latency with varying batch sizes
Garnet’s latency is optimized for adaptive client-side batching and many sessions querying the system. We increase the batch sizes from 1 to 64 and plot latency at different percentiles below with 128 active client connections. We see in Figure 4 that Garnet’s latency is low across the board. As before, we issue a mix of 80% GET and 20% SET operations.
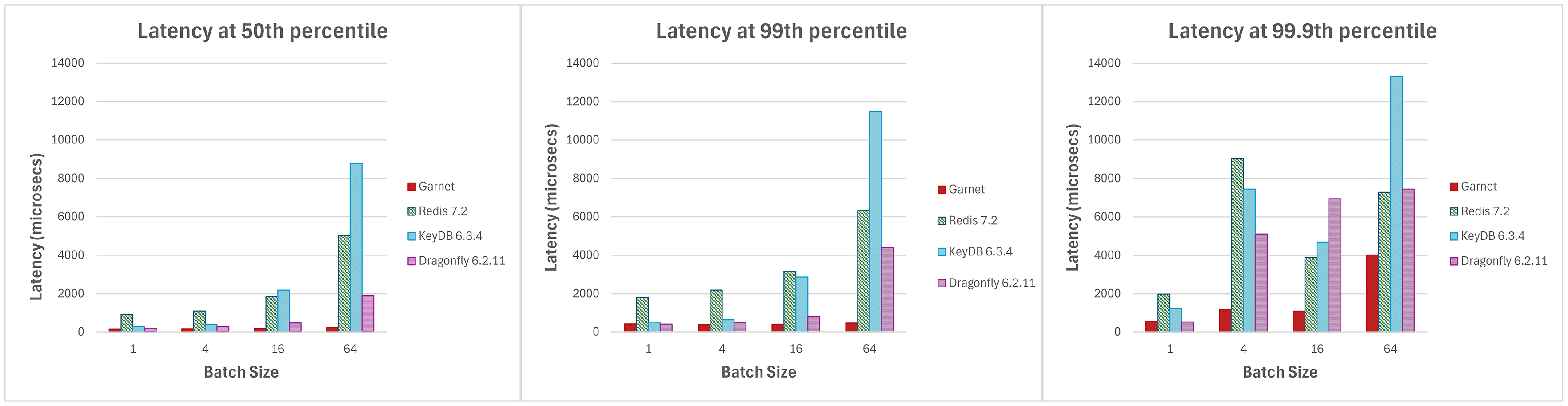
Other experiments
We have also experimented with other features and operation types and found Garnet to perform and scale well. Our documentation (opens in new tab) has more details, including how to run these experiments so that you can see the benefits for your own use cases.
Garnet’s design highlights
Garnet’s design re-thinks the entire cache-store stack – from receiving packets on the network, to parsing and processing database operations, to performing storage interactions. We build on top of years of research, with over 10 research papers published over the last decade. Figure 5 shows Garnet’s overall architecture. We highlight a few key ideas below.
Garnet’s network layer inherits a shared memory design inspired by our prior research on ShadowFax. TLS processing and storage interactions are performed on the IO completion thread, avoiding thread switching overheads in the common case. This approach allows CPU cache coherence to bring the data to the network, instead of traditional shuffle-based designs, which require data movement on the server.
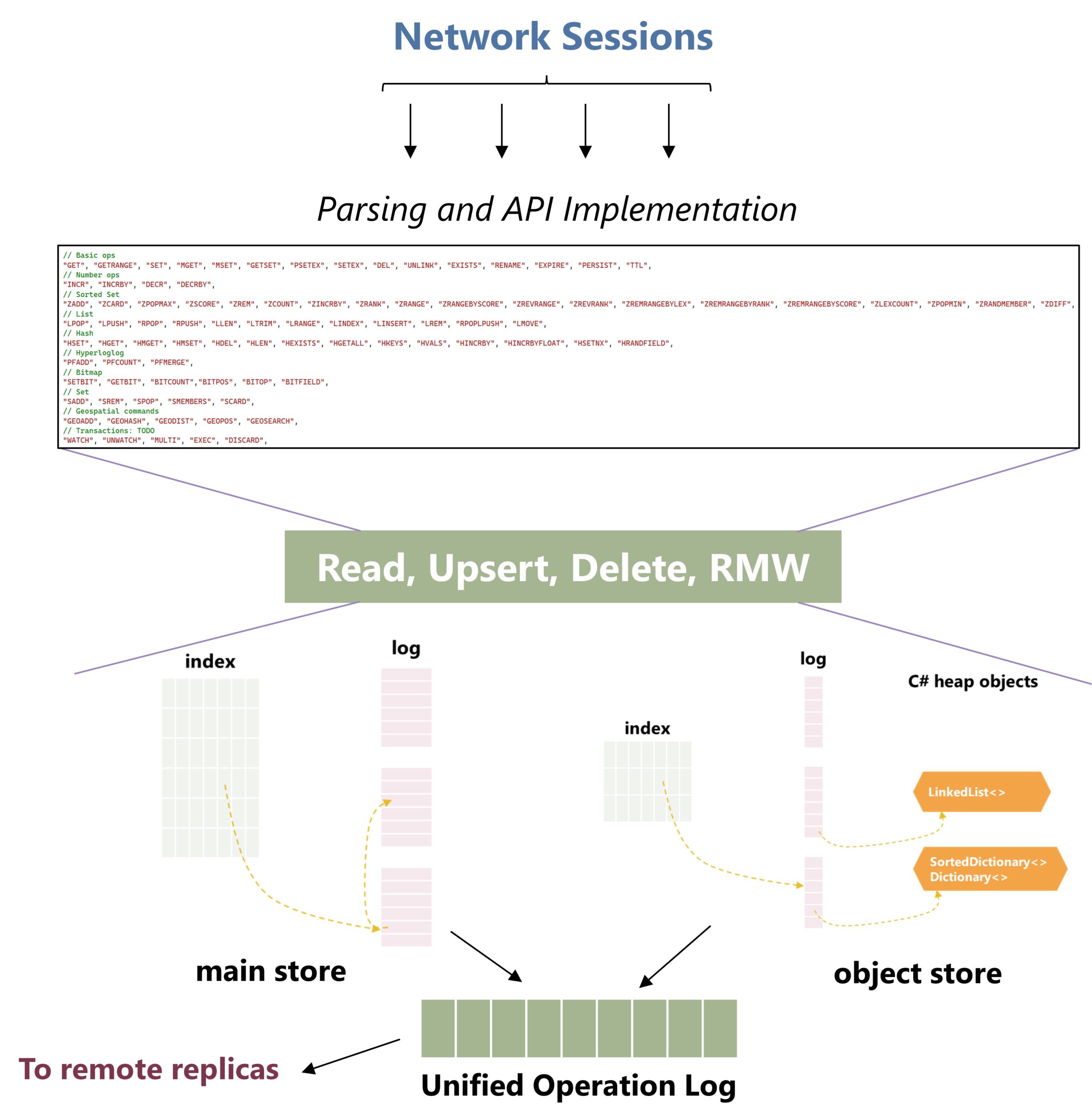
Garnet’s storage design consists of two Tsavorite key-value stores whose fates are bound by a unified operation log. The first store, called the “main store,” is optimized for raw string operations and manages memory carefully to avoid garbage collection. The second, and optional, “object store” is optimized for complex objects and custom data types, including popular types such as Sorted Set, Set, Hash, List, and Geo. Data types in the object store leverage the .NET library ecosystem for their current implementations. They are stored on the heap in memory (which makes updates very efficient) and in a serialized form on disk. In the future, we plan to investigate using a unified index and log to ease maintenance.
A distinguishing feature of Garnet’s design is its narrow-waist Tsavorite storage API, which is used to implement the large, rich, and extensible RESP API surface on top. This API consists of read, upsert, delete, and atomic read-modify-write operations, implemented with asynchronous callbacks for Garnet to interject logic at various points during each operation. Our storage API model allows us to cleanly separate Garnet’s parsing and query processing concerns from storage details such as concurrency, storage tiering, and checkpointing.
Garnet further adds support for multi-key transactions based on two-phase locking. One can either use RESP client-side transactions (MULTI/EXEC) or use our server-side transactional stored procedures in C#.
Cluster mode
In addition to single-node execution, Garnet supports a cluster mode, which allows users to create and manage a sharded and replicated deployment. Garnet also supports an efficient and dynamic key migration scheme to rebalance shards. Users can use standard Redis cluster commands to create and manage Garnet clusters, and nodes perform gossip to share and evolve cluster state. Overall, Garnet’s cluster mode is a large and evolving feature, and we will cover more details in subsequent posts.
Looking ahead
As Garnet is deployed in additional scenarios, we will continue to share those details in future articles. We also look forward to continuing to add new features and improvements to Garnet, as well as working with the open-source community.
Project contributors
Garnet Core: Badrish Chandramouli, Vasileios Zois, Lukas Maas, Ted Hart, Gabriela Martinez Sanchez, Yoganand Rajasekaran, Tal Zaccai, Darren Gehring, Irina Spiridonova.
Collaborators: Alan Yang, Pradeep Yadav, Alex Dubinkov, Venugopal Latchupatulla, Knut Magne Risvik, Sarah Williamson, Narayanan Subramanian, Saurabh Singh, Padmanabh Gupta, Sajjad Rahnama, Reuben Bond, Rafah Hosn, Surajit Chaudhuri, Johannes Gehrke, and many others.