

Microsoft Excel is one of the world’s most important software tools, relied upon by users worldwide to create, understand, model, predict, and collaborate. As the Excel team works to leverage new areas of computer science – advancements in programming languages, NLP, Artificial Intelligence, Machine Learning – they turn to Microsoft Research both to leverage the incredible work done in the organization as well as to help co-create a vision for what Excel should look like years into the future. The Excel team has built multiple long-term relationships with labs in Cambridge, China, and Redmond working in areas across data types, programming languages, analytics, web architecture, and error detection, many of which employ artificial intelligence, natural language processing, and machine learning. Not only has this allowed the Excel team to deliver innovation that would simply not have been possible otherwise, but it has also put research in a strategic role with material impact on the vision and resultant roadmap for Excel. Simply put, Microsoft researchers are now a core part of the Excel team helping create the product’s future.
David Gainer, Vice President of Product, Office
Not only is Microsoft Excel the world’s most widely used spreadsheet, it could be argued that it is also the world’s most widely used programming language. There are tens of millions of self-described professional and hobbyist developers worldwide: yet hundreds of millions of people use Excel, and many of them use it to build themselves sophisticated tools that go far beyond the original capabilities of a spreadsheet. Excel provides ordinary users with tools for deriving insights from data without necessarily needing to learn a complex programming language or data visualization techniques – a particularly important and useful benefit in a world that is awash in data. In doing so, Excel helped democratize and accelerate the field of data science.
In fact, Excel recently became Turing-complete with the availability of LAMBDA, which allows users to define new functions written in Excel’s own formula language. Having achieved Turing-completeness, it is now theoretically possible to solve any classical computation problem using the application.
This milestone is the latest in a long history of collaboration and exploration among researchers and product engineers to expand the capabilities of Excel – particularly, moving beyond scalar values (numbers, strings and Booleans) to encompass richer data types and a richer semantic understanding of that data. For nearly 20 years, researchers across several Microsoft labs have used spreadsheets as the starting point for advances in programming languages and techniques, as well as novel applications of AI, data mining and analytics, knowledge computing, natural language processing and software analytics. At the same time, working side-by-side with product teams to understand Excel users’ needs and behavior has surfaced new problems for researchers to solve, and inspired new research directions in programming languages and human-computer interaction.
This research collection recounts the long history of research collaboration with and contributions to Excel, including work from the Calc Intelligence and Spreadsheet Intelligence projects, the Data, Knowledge and Intelligence, Knowledge Computing and Software Analytics groups, as well as several other researchers and groups throughout the company.
Explore more
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
-
2003
Researchers Simon Peyton-Jones, Margaret Burnett and Alan Blackwell publish A User-Centered Approach to Functions in Excel, which describes potential extensions to Excel that integrate user-defined functions into the spreadsheet grid – highlighting how programming language insights can be applied to a product not normally considered as a programming language. The following year, they publish Champagne Prototyping: A Research Technique for Early Evaluation of Complex End-User Programming Systems, which introduces new evaluation techniques for changes to end-user programming systems that are inexpensive to do, yet retain the credibility of evaluating changes with real users of the environment. These techniques were used in early studies into the benefits of user-defined functions within Excel – a research direction that laid the first stones on the road to LAMBDA and other product enhancements.
-
2009
While returning from a conference, researcher Sumit Gulwani has a chance conversation with an Excel user that inspires further research into programming by example (PBE) and, later, a shipping feature in Excel 2013. Building on his experience in program verification and program synthesis, he worked with the product team to create Flash Fill, which automates tedious tasks by implementing code based on an example of what the user wants to do. Variants of this technology later shipped as part of PowerShell and Azure Operations Management Suite, and ideas from the related PROSE program synthesis project have been implemented in many other Microsoft products and services. The pioneering vision and impact of Flash Fill shipping in Microsoft Excel, reaching millions of users, has inspired numerous subsequent research and product offerings exploring the power of program synthesis to empower non-programmers.
Explore more
-
2013
Researchers and Excel program managers begin speaking with customers to gather more ideas for enhancements to Excel. The collected ideas were organized in a spreadsheet, naturally, and the most promising ideas were highlighted in yellow – the foundation for what would be internally called Project Yellow – a focused collaboration between researchers and product teams that eventually grew to incorporate capabilities such as logic abstraction and data typing into Excel.
Meanwhile, researcher Andy Gordon and his collaborators published Tabular: A Schema-Driven Probabilistic Programming Language, which proposes a new kind of programming language for machine learning wherein programs are written by annotating existing relational schemas with probabilistic model expressions – a development with potential applications for spreadsheets, among other things. These ideas were explored in subsequent papers over the next several years, and Gordon would later work more closely with the Excel team on Project Yellow.
Explore more
-
2014
Microsoft researchers and Excel program managers continue to explore and refine the ideas they collected, drawing from ongoing research publications as well as further user research and scenario development work. They began developing early prototypes, and working with product leadership to define a plan to turn these ideas into usable features.
Meanwhile, researchers continue to publish work that proposes new capabilities for spreadsheets, as well as new programming approaches that could be relevant to people using them to develop increasingly sophisticated tools. In the Data, Knowledge and Intelligence group in Microsoft Research Asia, researchers kick off the IN4 initiative (Interactive Intuitive Instant Insights), which works to enable two-way interaction between users and systems: where systems don’t just respond to user requests, they can identify and surface recommendations. (This builds on previous work in software analytics research that began in 2009.) This work leads to several features that ship as part of Excel in subsequent years.
Explore more
-
2016

The Calc Intelligence team and Excel colleagues sharing a moment at Microsoft Research Cambridge, UK. Project Yellow begins to move from user research and brainstorming to development, with the creation of a more concrete plan and resource requirements to begin adding new capabilities to Excel. This work is recounted in a 2020 presentation to industry customers.
In April 2018, two new data types – geography and stocks – are initially made available to Excel users who are part of the product’s Insiders program, and later rolled out to all users. This draws in part from Microsoft Research Asia researchers’ work on automated entity identification. Also that year, Excel added the ability to compute array values that spill over into adjacent cells, another product of collaboration between researchers and the program group.
Meanwhile, other researchers at Microsoft continue to explore other ways to enhance spreadsheets, including the use of neural networks and automatic extraction of insights from multi-dimensional data (a concept later implemented in Excel as Excel Ideas / Analyze Data (opens in new tab)), while the Calc Intelligence group explored new ideas such as implementing multiple-representation spreadsheets to better detect and fix errors and perform abstract operations.
In 2016, researchers at Microsoft Research Asia begin work on AnnaTalk, which enables users to query data using natural language – rather than writing a formula, users can ask Excel for “average sales per country,” for instance, as if they were talking with a data analyst. This taps into not just natural language capabilities, but also tabular intelligence: the ability to recognize and understand semantic data in tables (such as column and row titles), and the ability to recognize entities or data types within tabular data. This functionality is made available to PowerBI mobile users in 2017, and later ships to all Excel users in 2019. Some of the underlying entity recognition technology is used in several other Microsoft products and services, and has also been open-sourced (opens in new tab).
Another area of research is the development of tools for spreadsheet users that better match the sophistication and capabilities of those available to software developers, such as tools to identify bugs. For instance, the Melford classifier referenced below uses neural networks to identify common spreadsheet errors – such as the inclusion of a number where a formula should be – that have been responsible for significant financial losses.
At an internal company hackathon, the Calc Intelligence team creates a working demo for Calc Anywhere, a research vision to bring formula calculation to web applications such as Word or Teams, or even in Wikipedia. The demo, which showed formula evaluation within Word, won the hackathon and attracted the attention of a team of Excel developers based in Israel who were looking to implement client-side estimation in Excel for the web. Client-side estimation can dramatically improve the performance of web-based spreadsheets by evaluating formulas locally instead of in the cloud. The researchers and developers collaborated to rewrite the demo’s code in TypeScript, which became Calc.ts. This functionality began rolling out to customers in 2018.
Building on the Project Yellow work, Microsoft researchers in Cambridge formally establish the Calc Intelligence project in 2018, which aims to bring intelligence to end-user programming, and in particular to spreadsheets – transcending grids and formulas to enhance and extend the spreadsheet, inspired by the many ways that users have re-purposed them as programming environments.
Explore more
- Download Microsoft.Recognizers.Text
- Publication Expandable Group Identification in Spreadsheets
-
2019
Ideas in Excel (now called Analyze Data) is made available to Excel users. This functionality draws from work in several areas from Microsoft Research, including the natural language capabilities developed as part of AnnaTalk and several efforts focused on understanding the semantic structure of tabular data. Together, these research breakthroughs enable a more natural and fluid way of manipulating and visualizing data in spreadsheets, while also working more proactively to suggest ideas to users.
While development continues on scenarios and features identified by Project Yellow, including the implementation of first-class records and dynamic arrays, researchers across the company continue to use spreadsheets as a venue for research, as well as a testbed for explorations into user behavior. Key developments include using machine learning to identify and apply semantic understanding to content, as well as determining user intent; studies on how users perceive and manage uncertainty using spreadsheets despite their inherent limitations for doing so; and studies of the potential applicability to spreadsheets of probabilistic programming.
Explore more
- Publication End-User Probabilistic Programming
-
2020
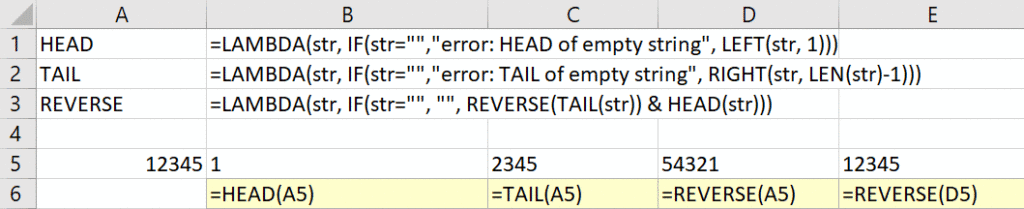
Example of a recursive LAMBDA function, which reverses a string using two auxiliary functions Project Yellow reaches a milestone with the introduction of LAMBDA, which allows users to define new functions written in Excel’s own formula language. These newly-defined functions can call other LAMBDA-defined functions, to arbitrary depth, even recursively – making Excel Turing-complete.
While this is a major milestone for Project Yellow, it is by no means the end of the story. In the publications below, researchers use spreadsheets as the starting point for a wide variety of research projects – from using neural networks to automatically format tables, to furthering spreadsheets’ semantic understanding of the information they contain, to understanding the overlap between spreadsheet use and programming. These ideas promise to further enhance spreadsheet software used by hundreds of millions of people every day, while also helping to advance the state of the art in software development and human-computer interaction.
Explore more
- Publication Gridlets: Reusing Spreadsheet Grids
- Publication Higher-Order Spreadsheets with Spilled Arrays
- Publication Neural Formatting for Spreadsheet Tables



