This research was accepted by the 2023 International Conference on Learning Representations (ICLR) (opens in new tab), which is dedicated to the advancement of the branch of artificial intelligence generally referred to as deep learning.
Reinforcement learning (RL) hinges on the power of rewards, driving agents—or the models doing the learning—to explore and learn valuable actions. The feedback received through rewards shapes their behavior, culminating in effective policies. Yet, crafting reward functions is a complex, laborious task, even for experts. A more appealing option, particularly for the people ultimately using systems that learn from feedback over time, is an agent that can automatically infer a reward function. The interaction-grounded learning (IGL) paradigm from Microsoft Research enables agents to infer rewards through the very process of interaction, utilizing diverse feedback signals rather than explicit numeric rewards. Despite the absence of a clear reward signal, the feedback relies on a binary latent reward through which the agent masters a policy that maximizes this unseen latent reward using environmental feedback.
In our paper “Personalized Reward Learning with Interaction-Grounded Learning,” (opens in new tab) which we’re presenting at the 2023 International Conference on Learning Representations (ICLR) (opens in new tab), we propose a novel approach to solve for the IGL paradigm: IGL-P. IGL-P is the first IGL strategy for context-dependent feedback, the first use of inverse kinematics as an IGL objective, and the first IGL strategy for more than two latent states. This approach provides a scalable alternative to current personalized agent learning methods, which can require expensive high-dimensional parameter tuning, handcrafted rewards, and/or extensive and costly user studies.
- Publication Interaction-Grounded Learning
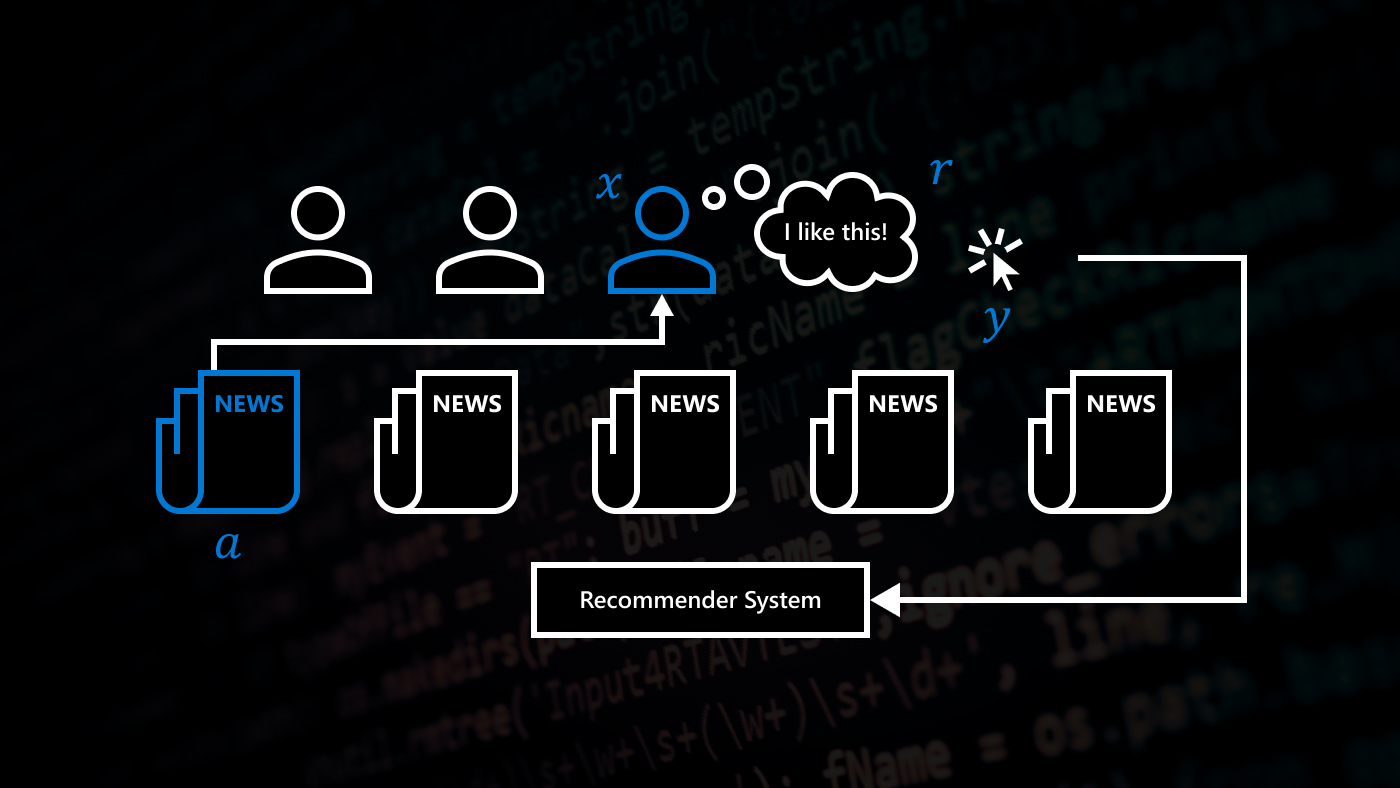
IGL-P in the recommender system setting
IGL-P is particularly useful for interactive learning applications such as recommender systems. Recommender systems help people navigate increasing volumes of content offerings by providing personalized content suggestions. However, without explicit feedback, recommender systems can’t detect for certain whether a person enjoyed the displayed content. To accommodate, modern recommender systems equate implicit feedback signals with user satisfaction. Despite the popularity of this approach, implicit feedback is not the true reward. Even the click-through rate (CTR) metric, the gold standard for recommender systems, is an imperfect reward, and its optimization naturally promotes clickbait.
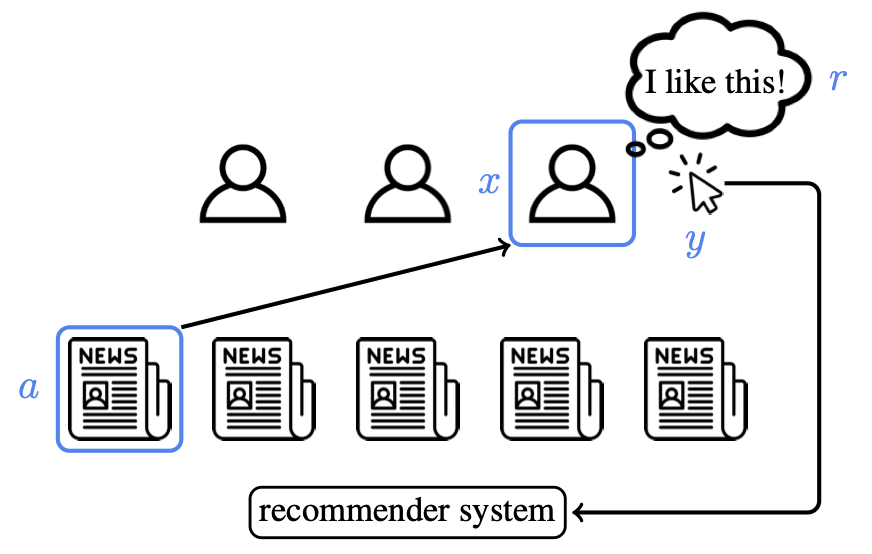
This problem has led to the handcrafting of reward functions with various implicit feedback signals in modern recommender systems. Recommendation algorithms will use hand-defined weights for different user interactions, such as replying to or liking content, when deciding how to recommend content to different people. This fixed weighting of implicit feedback signals might not generalize across a wide variety of people, and thus a personalized learning method can improve user experience by recommending content based on user preferences.
Spotlight: Blog post

Research Focus: Week of September 9, 2024
Investigating vulnerabilities in LLMs; A novel total-duration-aware (TDA) duration model for text-to-speech (TTS); Generative expert metric system through iterative prompt priming; Integrity protection in 5G fronthaul networks.
The choice of reward function is further complicated by differences in how people interact with recommender systems. A growing body of work shows that recommender systems don’t provide consistently good recommendations across demographic groups. Previous research suggests that this inconsistency has its roots in user engagement styles. In other words, a reward function that might work well for one type of user might (and often does) perform poorly for another type of user who interacts with the platform differently. For example, older adults have been found to click on clickbait more often (opens in new tab). If the CTR is used as an objective, this group of users will receive significantly more clickbait recommendations than the general public (opens in new tab), resulting in higher rates of negative user experiences and leading to user distrust in the recommender system.
IGL-P provides a novel approach to optimize content for latent user satisfaction—that is, rewards that a model doesn’t have direct access to—by learning personalized reward functions for different people rather than requiring a fixed, human-designed reward function. IGL-P learns representations of diverse user communication modalities and how these modalities depend on the underlying user satisfaction. It assumes that people may communicate their feedback in different ways but a given person expresses (dis)satisfaction or indifference to all content in the same way. This enables the use of inverse kinematics toward a solution for recovering the latent reward. With additional assumptions that rewards are rare when the agent acts randomly and some negatively labeled interactions are directly accessible to the agent, IGL-P recovers the latent reward function and leverages that to learn a personalized policy.
IGL-P successes
The success of IGL-P is demonstrated with experiments using simulations, as well as with real-world production traces. IGL-P is evaluated in three different settings:
- A simulation using a supervised classification dataset shows that IGL-P can learn to successfully distinguish between different communication modalities.
- A simulation for online news recommendation based on publicly available data from Facebook users (opens in new tab) shows that IGL-P leverages insights about different communication modalities to learn better policies and achieve consistent performance among diverse user groups (the dataset, created in 2016, consists of public posts from the official Facebook pages of news companies from 2012 to 2016 and aggregated user reactions; because of this aggregation, identifying information can’t be extracted).
- A real-world experiment deployed in the Microsoft image recommendation product Windows Spotlight showcases that the proposed method outperforms the hand-engineered reward baseline and succeeds in a practical application serving millions of people.