

Figure 1: Milestone network architectures (2012 – present)
Since AlexNet was invented in 2012, there has been rapid development in convolutional neural network architectures in computer vision. Representative architectures (Figure 1) include GoogleNet (2014), VGGNet (2014), ResNet (2015), and DenseNet (2016), which are developed initially from image classification. It’s a golden rule that classification architecture is the backbone for other computer vision tasks.
What’s next for a new architecture that is broadly applicable to general computer vision tasks? Can we design a universal architecture from general computer vision tasks rather than from classification tasks?

GigaPath: Whole-Slide Foundation Model for Digital Pathology
Digital pathology helps decode tumor microenvironments for precision immunotherapy. In joint work with Providence and UW, we’re sharing Prov-GigaPath, the first whole-slide pathology foundation model, for advancing clinical research.
We pursued these questions and developed HRNet, a network that comes from general vision tasks and wins on many fronts of computer vision, including semantic segmentation, human pose estimation, and object detection. We’ve also released the code for HRNet on GitHub (opens in new tab), and the paper on an extension of HRNet, called “HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation,” (opens in new tab) has been published at CVPR 2020.
What’s essential for tasks beyond classification? The typical tasks, such as those mentioned in the paragraph above, require spatially fine representations. Before HRNet, most techniques extend classification networks, that is, they add an extra stage to raise the spatial granularity (Figure 2) or use dilated convolutions.

Figure 2: The structure of recovering high resolution from low resolution. (a) A low-resolution representation learning subnetwork (such as AlexNet, GoogleNet, VGGNet, ResNet, DenseNet), which is formed by connecting high-to-low convolutions in series. (b) A high-resolution representation recovering subnetwork, which is formed by connecting low-to-high convolutions in series. Representative examples include SegNet, DeconvNet, U-Net and Hourglass, encoder-decoder, and SimpleBaseline.
How does HRNet do this? It is conceptually different from the classification architecture. HRNet is designed from scratch, rather than from the classification architecture, and it breaks the dominant design rule, connecting the convolutions in series from high resolution to low resolution, which goes back to LeNet-5 (LeCun et al., 1998) (opens in new tab).
High-Resolution Network: Design and its four stages
The HRNet maintains high-resolution representations through the whole process. We start from a high-resolution convolution stream, gradually add high-to-low resolution convolution streams one by one, and connect the multi-resolution streams in parallel. The resulting network consists of several (four in the current design) stages as depicted in Figure 3, and the nth stage contains n streams corresponding to n resolutions. We conduct repeated multi-resolution fusions by exchanging the information across the parallel streams over and over.
The high-resolution representations learned from HRNet are not only semantically strong, but also spatially precise. This comes from two aspects. First, our approach connects high-to-low resolution convolution streams in parallel rather than in series. Therefore, our approach is able to maintain the high resolution instead of recovering high resolution from low resolution, and the learned representation is spatially more precise accordingly. Second, most existing fusion schemes aggregate high-resolution low-level and upsampled low-resolution high-level representations. Instead, we repeat multi-resolution fusions to boost the high-resolution representations with the help of the low-resolution representations, and vice versa. As a result, all the high-to-low resolution representations are semantically stronger.

Figure 3: An example HRNet. Only the main body is illustrated, and the stem is not included. There are four stages. The 1st stage consists of high-resolution convolutions. The 2nd (3rd, 4th) stage repeats two-resolution (three-resolution, four-resolution) blocks several (that is, 1, 4, 3) times.
Applications
The HRNet is a universal architecture for visual recognition. The HRNet has become a standard for human pose estimation since the paper was published in CVPR 2019 (opens in new tab). It has been receiving increasing attention in semantic segmentation due to its high performance. HRNet shows superior or competitive performance on a wide-range of position-sensitive tasks, including object detection, face detection, and facial landmark detection, elaborated on in this paper published at IEEE TPAMI 2020 (opens in new tab). In our CVPR 2020 paper (opens in new tab), we recently extended it to learn higher-resolution multi-scale representations for handling the scale diversity in bottom-up pose estimation and obtained the state-of-the-art result.
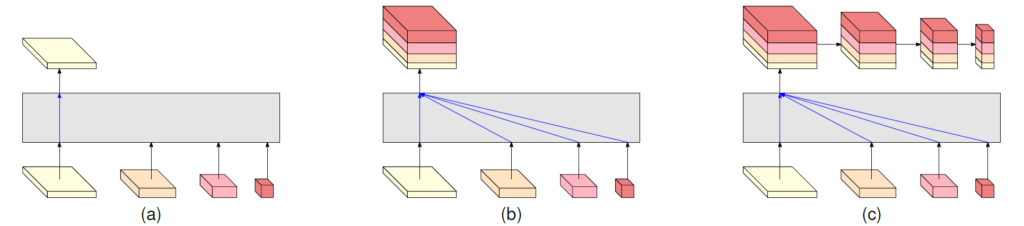
Figure 4: (a) HRNetV1: only output the representation from the high-resolution convolution stream. (b) HRNetV2: Concatenate the (upsampled) representations that are from all the resolutions. (c) HRNetV2p: form a feature pyramid from the representation by HRNetV2. The four-resolution representations at the bottom in each sub-figure are outputted from the network in Figure 3. The gray box indicates how the output representation is obtained from the input four-resolution representations.
Human Pose Estimation
Human pose estimation, also known as keypoint detection, aims to detect the locations of keypoints or parts (for example, elbow, wrist, and so on) from an image. The HRNet applied to human pose estimation uses the representation head shown in Figure 4(a), called HRNetV1. Visual example results are shown in Figure 5.
The comparison with ResNet-based methods is shown in Figure 6. We can see that HRNet outperforms ResNet in terms of estimation performance (AP), parameter complexity (#parameters), and computation complexity (GFLOPS). The detailed comparison is given in Table 1.

Figure 5: Qualitative COCO human pose estimation results over representative images with various human size, different poses, or clutter background.

Figure 6: Comparison on COCO human pose estimation between ResNet and HRNet under the same setting. HRNet performs better in terms of AP, #parameters, and computation complexity. 32 (48) in W32 (48) is the width of the high-resolution convolution.

Table 1: Comparison with state-of-the-arts on COCO test-dev.
Sematic Segmentation
Semantic segmentation is a problem of assigning a class label to each pixel. The HRNet applied to semantic segmentation uses the representation head shown in Figure 4(b), called HRNetV2. Some visual example results are given in Figure 7.

Figure 7: Qualitative segmentation on Cityscapes images.
The HRNet compared to state-of-the-art methods, U-Net++, DeepLab and PSPNet on the Cityscapes validation data is given in Table 2. We can see that the HRNet achieves better results with even less parameter and computation complexities. Comparison to existing state-of-the-arts on Cityscapes test is provided in Table 3. The results on other datasets can be found in this IEEE TPAMI 2020 paper (opens in new tab).

Table 2: Comparison with representative segmentation methods on Cityscapes validation. HRNet performs superiorly in terms of parameter complexity, computation complexity, and segmentation quality.
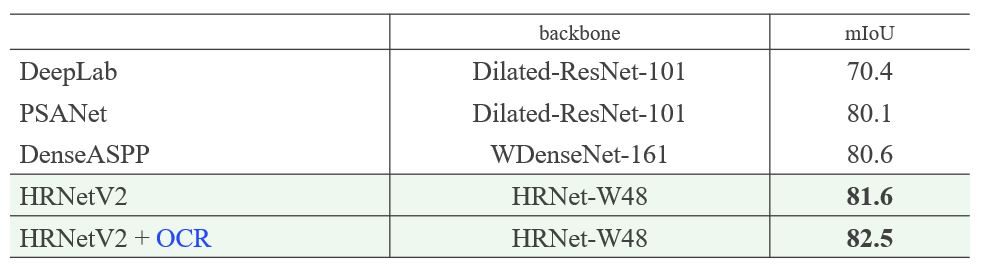
Table 3: Comparison to existing state-of-the-arts on Cityscapes test. OCR is the abbreviation of object-contextual representation we proposed.
Object Detection and Instance Segmentation
Object detection aims to identify the bounding box of the object instance in an image, and instance segmentation aims to identify the pixels belonging to an object instance. Examples are shown in Figure 8. We apply the multi-level representations, HRNetV2p, shown in Figure 4(c) to object detection and instance segmentation. The comparison shown in Tables 4 and 5 shows that HRNet outperforms with ResNet and ResNeXt.

Figure 8: Qualitative examples for COCO object detection (left three images) and instance segmentation (right three images).
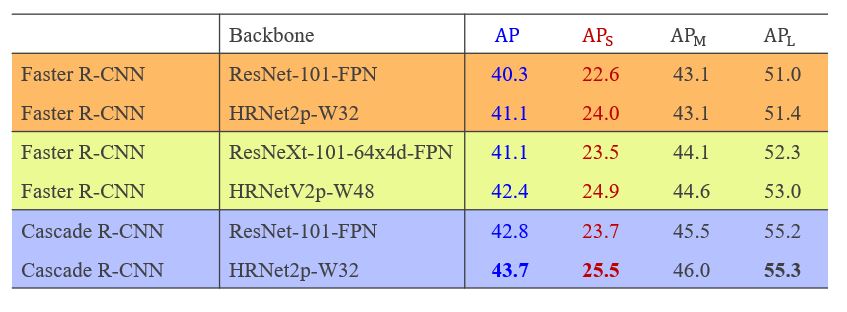
Table 4: Object detection comparison with ResNet and ResNeXt with similar parameter and computation complexes under the Faster R-CNN and Cascade R-CNN frameworks on COCO test-dev without mutli-scale training and testing. This shows that HRNet HRNet performs better than ResNet and ResNeXt

Table 5: Object detection (bbox) and instance segmentation (mask) Comparison with ResNet with similar parameter and computation complexes under the Mask R-CNN framework on COCO val. without mutli-scale training and testing. This shows that HRNet HRNet performs better than ResNet and ResNeXt.
Runtime Cost
What about runtime costs for HRNet? Is HRNet expensive in terms of memory and computation complexity? The answer is an emphatic no. The comparison is given in Table 6 for the runtime cost comparison on the PyTorch 1.0 platform. In human pose estimation, HRNet gets superior estimation score with much lower training and inference memory cost and slightly larger training time cost and inference time cost. In semantic segmentation, HRNet overwhelms PSPNet and DeepLabV3 in terms of all the metrics, and the inference-time cost is less than half of PSPNet and DeepLabV3. In object detection, HRNet is also better than ResNet and ResNeXt.
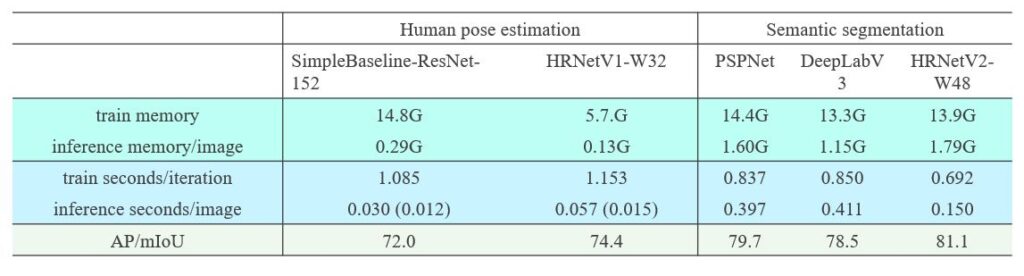
Table 6.1: Memory and time cost for human pose estimation on COCO val and semantic segmentation on Cityscapes val.
We report inference time for pose estimation on MXNet 1.5.1, which supports static graph inference that multi-branch convolutions used in the HRNet benefits from. The numbers for training are obtained on a machine with 4 V100 GPU cards. During training, the input sizes are 256×192$, 512×1024, and 800×1333, and the batch sizes are 128, 8 and 8 for pose estimation, segmentation and detection respectively. The numbers for inference are obtained on a single V100 GPU card. The input sizes are 256×192, 1024×2048, and 800×1333, respectively. The score means AP for pose estimation on COCO val and detection on COCO val, and mIoU for cityscapes val segmentation. PSPNet and DeepLabV3 use dilated ResNet-101 as the backbone. (See Tables 6.1 and 6.2.)

Table 6.2: Train and inference Memory and time cost for object detection on COCO segmentation.
ImageNet Pretraining
We pretrain HRNet, augmented by a classification head, shown in Figure 9. We do not aim to push the state-of-the-art result for ImageNet classification, and so we do not utilize some tricks to improve training. The pretraining results and the comparison with ResNet are given in Table 7. The results are similar with and slightly better than ResNet.
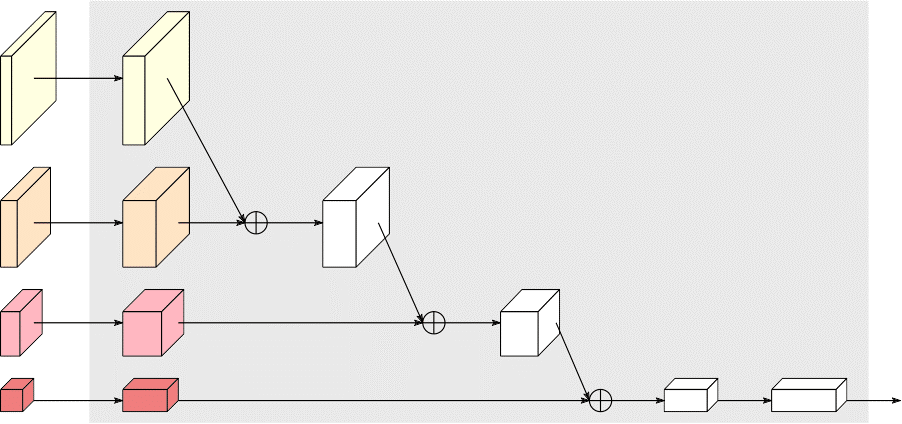
Figure 9: Representation for ImageNet classification. The input of the box is the representations of four resolutions.
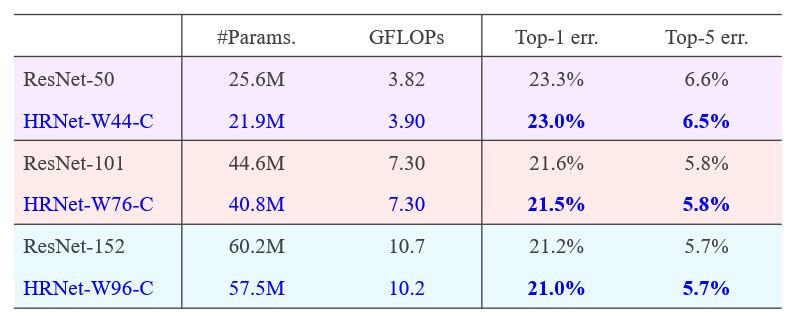
Table 7: ImageNet Classification results of HRNet and ResNet. The proposed method is named HRNet-Wx-C. In this case, x means the width.
Conclusions
The high-resolution network (HRNet) is a universal architecture for visual recognition. The applications of the HRNet are not limited to what we have shown above, and they are suitable to other position-sensitive vision applications, such as face alignment, face detection, super-resolution, optical flow estimation, depth estimation, and so on. There are already follow-up works, looking into using HRNet for image stylization, inpainting, image enhancement, image dehazing, temporal pose estimation, drone object detection.
It is reported in this paper (opens in new tab) that a slightly-modified HRNet combined with ASPP achieved the best performance for Mapillary panoptic segmentation in the single model case. In the COCO and Mapillary Joint Recognition Challenge Workshop with ICCV 2019, the COCO Dense Pose challenge winner and almost all the COCO keypoint detection challenge participants adopted the HRNet. The OpenImage instance segmentation challenge winner (ICCV 2019) also used the HRNet.


