Today people use personal digital assistants for help with scheduling, playing music, turning on or adjusting other devices, and answering basic questions such as “What time’s the game on?” or “Where’s the nearest hardware store?” But what if these assistants could do more to help us in our daily lives?
Imagine it’s 10 p.m., and you’ve just settled in for some much-needed sleep when you’re jolted awake by a single thought: Did I leave the back door open? No worries. That personal digital assistant of yours is on wheels and able to provide the answer to your question without you having to further disrupt your nighttime routine by getting out of bed. You ask the digital assistant to check the door for you, but before doing so, it asks for clarification. Which door? You respond, and your digital assistant is off. It winds its way to the back of the house, identifies the right door, determines whether it’s open, closes it if need be, and returns with an update. The open door has been closed. The report is reassuring, and you fall asleep with peace of mind.
Spotlight: Blog post

Research Focus: Week of September 9, 2024
Investigating vulnerabilities in LLMs; A novel total-duration-aware (TDA) duration model for text-to-speech (TTS); Generative expert metric system through iterative prompt priming; Integrity protection in 5G fronthaul networks.
That’s one of the dream scenarios for those working in artificial intelligence. Our goal is to have robots in the physical world and agents in the digital, virtual, and mixed worlds naturally interact with people via language to assist them in a variety of tasks. We have some way to go toward that goal, since even relatively simple scenarios such as a home assistive robot physically helping us locate a misplaced cellphone—oh, how useful that would be!—aren’t as easy as they seem.
To help bring the dream within reach, we’ve created Vision-based Navigation with Language-based Assistance (VNLA). VNLA is a new grounded vision-language task for training agents not only to respond to open-ended requests—that is, those without turn-by-turn instructions—but to also strategically ask for help via language when it is needed. This capability relies on a novel framework we’ve termed “Imitation Learning with Indirect Intervention” (I3L). We’re presenting the paper on this work at the annual computer vision conference CVPR. A video demonstrating the approach is available, and code and data-downloading scripts for the work can be accessed via GitHub.
What’s holding AI back?
Requests such as “check the back door” and “help me find my phone” pose significant challenges to AI systems today. Among them:
- Grounding natural language to vision: The agent has to understand what is being asked of it. In the example of the missing cellphone, that means knowing which cellphone the person is referring to when he or she says “my,” what the word “phone” means visually, and when the phone of interest is in its field of view.
- Navigating and avoiding collisions in GPS-denied environments: The agent must also understand common locations within the house where phones are likely to be left and how to navigate efficiently to these locations without explicit localization information via simultaneous localization and mapping (SLAM) or GPS. Further, the agent—just like humans—must be able to do this without access to an explicit metric map of the house. It must also navigate to these locations without bumping into or colliding with people and household objects sharing the space.
- Interacting with people more naturally: When people ask one another for help, communication is not limited to a single command; there is a back-and-forth, a giving and taking of information. Often when lending a hand, people will ask specific follow-up questions that can yield valuable feedback. In the case of the cellphone, perhaps they’ll ask for a reminder of what color the cellphone case is or where the person last remembers using it, and they can pose these types of questions at any point in the process. We believe robots and agents must be endowed with similar abilities to collaboratively accomplish tasks. A first step would be for robots and agents to understand how to deal appropriately with cases of known unknowns. In other words, they need to understand when they’re uncertain and should ask for help.
Overcoming the hurdles
Each of these challenges represents an active research area crucial to the advancement of AI. They’re particularly important in the case of interactive robots, where the challenges are occurring simultaneously, which also exacerbates the issue of collecting sequential interaction data to train such agents. These settings are inherently non-i.i.d—independent and identically distributed—ensuring that naïve supervised learning will fail when fielded.

Figure 1: An example run of the Vision-based Navigation with Language-based Assistance task in an unseen environment. (a) A bird’s-eye view of the environment annotated with the agent’s path. The agent observes the environment only through a first-person view. (b) A requester (wearing a hat) asks the agent to find a towel in the kitchen. Two towels are in front of the agent, but the room is labeled as a “bathroom.” The agent ignores them without being given the room label. (c) The agent leaves the bathroom. Sensing that it is lost, the agent signals the advisor (with mustache) for help. The advisor responds with an “easier” low-level subgoal: “Turn 60 degrees right, go forward, turn left.” (d) After executing the subgoal, the agent is closer to the kitchen, but still confused. It requests help again. (e) Executing the second subgoal helps the agent see the target towel.
In our task, we ask the agent—which “sees” its environment via a monocular camera that captures its view as an image—to find objects in specific locations. For example, we may request that our agent find a towel in the kitchen as demonstrated by Figure 1. Through the solution pathway of our task, we address the challenges in several ways.
For one, we leverage rich simulation environments in helping ground language to vision. Robotics and vision communities have increasingly come to rely on rich high-fidelity simulation environments such as AirSim for training agents end-to-end. We use the Matterport3D dataset, which has high-fidelity 3D reconstructions of real homes via the Room-to-Room simulator, to train our agent in a photorealistic environment.
Secondly, we chose to use imitation learning over reinforcement learning for the training paradigm. Imitation learning, in which the agent learns directly from expert demonstrations rather than a reward function used in traditional reinforcement learning, can be exponentially faster in terms of trials with the environment. One drawback, though, is that imitation learning often relies on human experts to demonstrate the optimal sequence of actions necessary to complete the task, which can be costly. Not so here, another reason we chose to use IL. Simulation training provides a natural programmatic expert at training time at no extra cost: a planning algorithm with access to the full environment state. Specifically, we have a shortest path algorithm (A*), which has knowledge of the full map and location of all objects in the scene. This paradigm of imitating an expert that has much more information than the agent has been effectively used in complex planning problems in robotics.
I am lost—help!
Lastly—and most importantly—we train the agent to ask for help. In our task, there are an additional two key players: the requester—in real-world scenarios, the person giving the task—and the advisor. In real-world scenarios, the person giving the task would generally also be the advisor, but in theory, the advisor can be any entity with the ability to guide the agent. During execution of the task, the agent can ask for assistance from the advisor when it thinks it’s lost and can do so a budgeted number of times. A budget is important; otherwise, the agent—seeking to increase its success and noting that asking for help does so—will learn to ask for help at every step, which largely defeats the purpose. After all, who really wants an assistant that can’t get through a task without asking a million questions? The agent receives help via language aimed at putting it back on track for completing the task. For example, the advisor may say, “From where you are, turn right and take three steps.”
This way of providing assistance, via language, seeks to mimic the natural form of communication people use to help each other. With the ability to ask for help at critical points, the agent is able to successfully complete the tasks more often. In unseen environments, it performs more than five times better than baseline agents that don’t allow for such intervention. During training time, we also teach the agent when it should ask for help. This form of learning how to strategically ask for help improves agent performance in unseen test scenarios by about 38 percent over asking for help randomly and by about 72 percent over asking for help in the beginning. Learning when it isn’t confident and will benefit from asking for help is especially important for AI agents not only because doing so would help create more natural interactions, but also because AI agents are imperfect and intervention would be useful in helping the agent safely carry out complex requests.
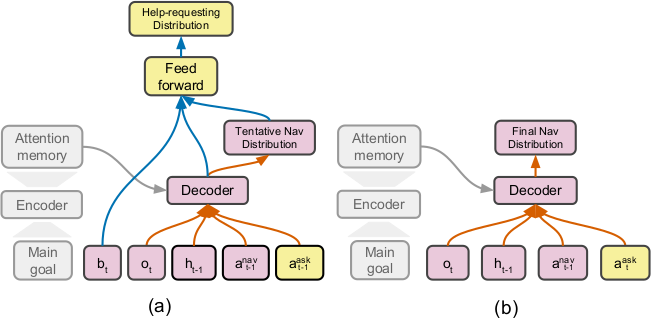
Figure 2: Two decoding passes of the navigation module. (a) The first decoding pass computes the tentative navigation distribution, which is used as a feature for computing the help-requesting distribution. (b) The second pass computes the final navigation distribution.
In the overall agent policy architecture, the agent runs two forward passes as shown in Figure 2. In the first pass, the tentative navigation distribution is computed and is used as a feature for the help-requesting decision. If there is a lot of uncertainty in the navigation distribution, then the agent can decide if it should stop and ask for help, so long as its budget allows. In the second pass, it computes the final navigation distribution, taking into account the extra help provided if help was requested.
Our framework seeks to help facilitate in our personal digital assistants the kinds of back-and-forth common to people helping one another. We see VNLA as a foundation on which to realize richer human-AI collaboration that incorporates more natural language and in which robots and agents can participate in perspective taking.
This work was spearheaded by University of Maryland, College Park PhD student Khanh Nguyen during a Microsoft Research summer internship. Team members Debadeepta Dey, Chris Brockett, and Bill Dolan served as advisors on the work.