
Visual understanding tasks are typically centered on objects, such as human pose tracking in Microsoft Kinect and obstacle avoidance in autonomous driving. In the deep learning era, these tasks follow a paradigm where bounding boxes are localized in an image, features are extracted within the bounding boxes, and object recognition and reasoning are performed based on these features.
The use of bounding boxes as the intermediate object representation has long been the convention because of their practical advantages. One advantage is that they are easy for users to annotate with little ambiguity. Another is that their structure is convenient for feature extraction via grid sampling.
Spotlight: Blog post

Research Focus: Week of September 9, 2024
Investigating vulnerabilities in LLMs; A novel total-duration-aware (TDA) duration model for text-to-speech (TTS); Generative expert metric system through iterative prompt priming; Integrity protection in 5G fronthaul networks.
However, bounding boxes come with disadvantages as well. As illustrated below, the geometric information revealed by a bounding box is coarse. It cannot describe more fine-grained information such as different human poses. In addition, feature extraction by grid sampling is inaccurate, as it may not conform to semantically meaningful image areas. As seen in the figure, many features are extracted on the background rather than on the foreground object.
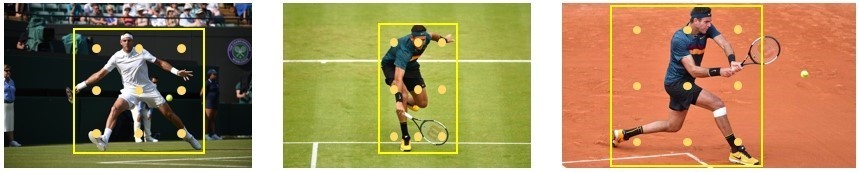
(opens in new tab) Bounding boxes of a tennis player. The boxes provide only a coarse geometric description, and feature extraction locations (denoted by yellow dots) may not lie on the foreground object.
In our paper that will be presented at ICCV 2019 (opens in new tab), “RepPoints: Point Set Representation for Object Detection (opens in new tab),” our team of researchers at Microsoft Research Asia introduce an alternative to bounding boxes in the form of a set of points. This point set representation, which we call RepPoints, can conform to object pose or shape, as shown in the figure below. RepPoints learn to adaptively position themselves over an object in a manner that circumscribes the object’s spatial extent and indicates semantically significant local regions. In this way, they provide a more detailed geometric description of an object, while pointing to areas from which useful features for recognition may be extracted.

(opens in new tab) RepPoints on the same tennis player. In comparison to bounding boxes, RepPoints reveal greater geometric detail of an object and identify better locations for feature extraction.
RepPoints identify key points of interest without explicit supervision
The way it works is rather simple. Given a source point near an object center (marked in the figure below in red), the network applies 3×3 convolutions on the point’s feature to regress 2D offsets from the source point to multiple target points in the image (shown in green in the figure below), which together comprise the RepPoints representation. As can be seen in the figure below, this allows for more accurate key point detection when compared with bounding boxes. The source points are uniformly sampled across the image, without the need to additionally hypothesize over multiple anchors as is done in bounding box-based techniques.
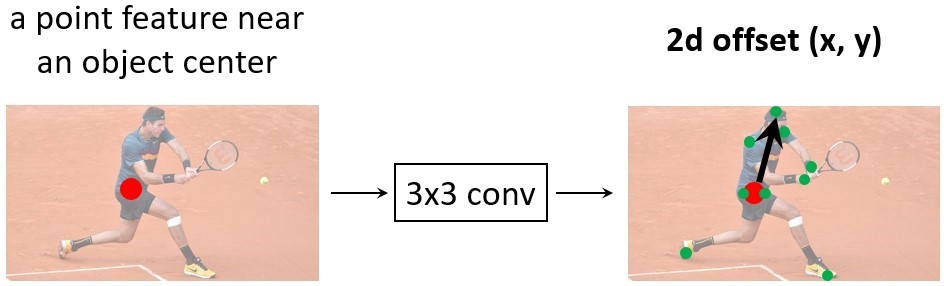
(opens in new tab) RepPoints (in green) are regressed over an object from a central source point (in red) via 3×3 convolutions.
RepPoints are learned through the implementation of two processes: localization supervision and recognition supervision. To drive the learning of RepPoints, our method utilizes bounding box information to constrain the point locations. This localization supervision is illustrated by the upper branch of the figure below, where a pseudo box formed from RepPoints needs to closely match the ground-truth bounding box. In addition, the learning is guided by recognition supervision in the lower branch, which favors point locations where the features aid in object recognition.
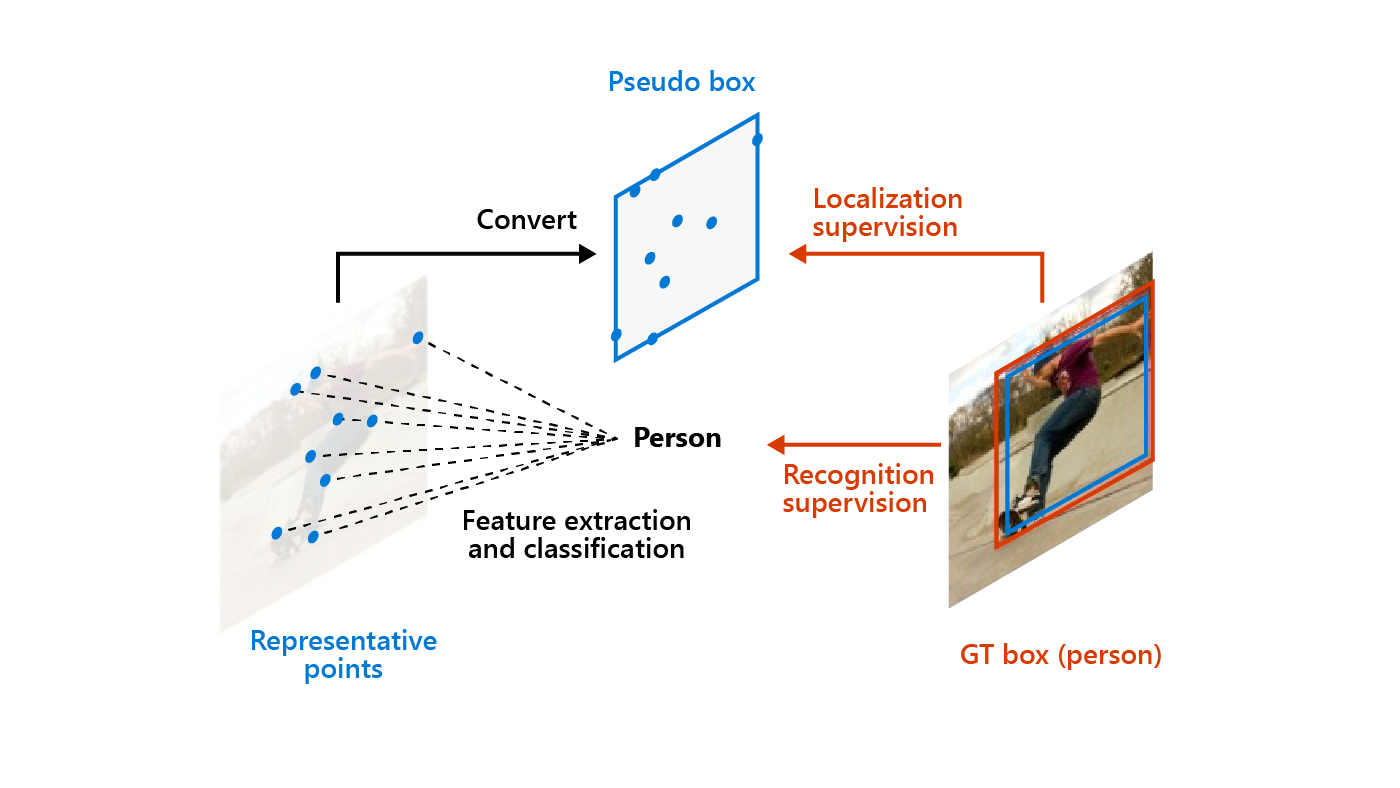
(opens in new tab) RepPoints are learned through two forms of supervision: localization from ground-truth bounding boxes and recognition from object class labels.
A visualization of learned RepPoints and the corresponding detection results are shown below for various kinds of objects. It can be seen that RepPoints tend to be located at extreme points or key semantic points of objects. These point distributions are automatically learned without explicit supervision.

(opens in new tab) RepPoints distributions and object detection results. Without explicit supervision, RepPoints identify and learn both extreme and key semantic points of objects accurately when objects are out of focus in an image (upper left), objects overlap (upper middle), objects vary in size (upper right), and object boundaries are, for various reasons, ambiguous (bottom row).
Performance on COCO benchmark and comparison to other object detectors
Our experiments on the COCO object detection benchmark show appreciable performance gains from changing the object representation from bounding boxes to RepPoints. With ResNet-50 or ResNet-101 as the network backbone, RepPoints obtain improvements of +2.1 mAP (mean Average Precision) or +2.0 mAP, respectively, as seen in the table below on the left. Reported in the second table below, a RepPoints based object detector, denoted as RPDet, compares favorably to existing leading object detectors. RPDet is the most accurate anchor-free detector to date (anchor-free methods are generally preferred due to the simplicity in use).
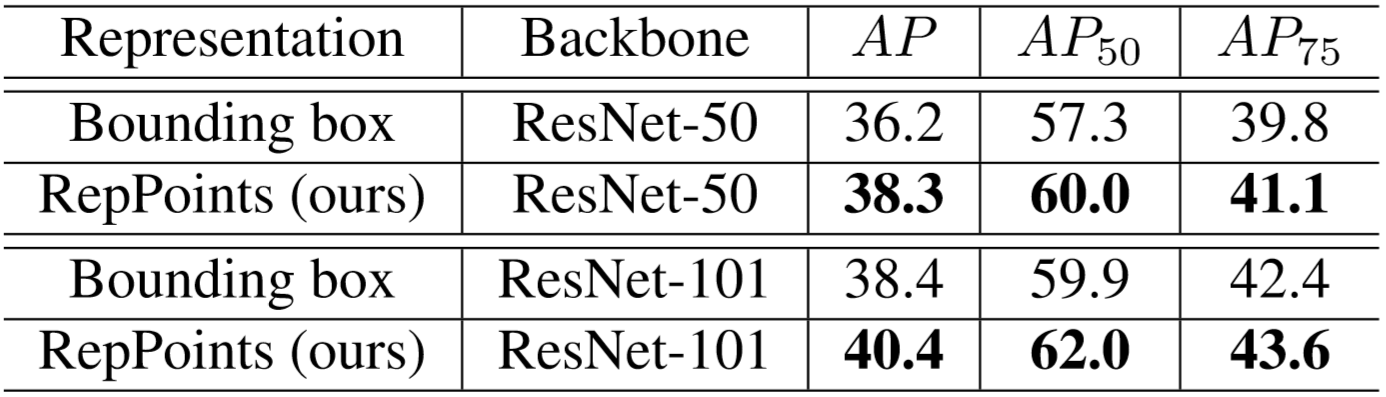
(opens in new tab) Bounding box vs. RepPoints
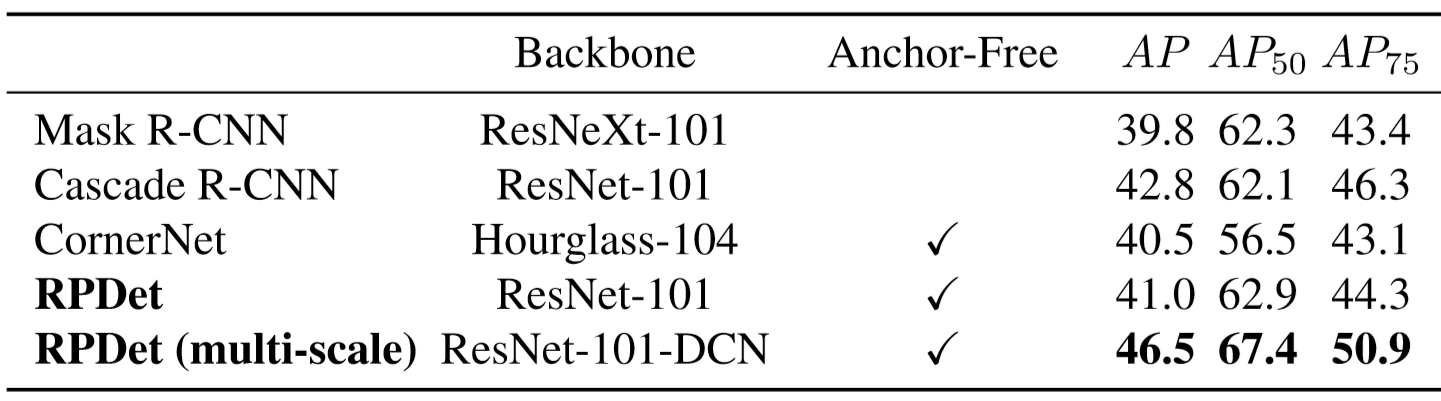
(opens in new tab) Our object detector (RPDet) is the most accurate anchor-free method to date when compared with other methods’ accuracy.
Learning richer and more natural object representations like RepPoints is a direction that holds much promise for object detection in general. The descriptiveness of RepPoints may make it useful for other visual understanding tasks, such as object segmentation, as well. If you are curious about exploring RepPoints in more depth, we encourage you to check out our source code, which is available on GitHub here (opens in new tab).
