
When people create, it’s not very often they achieve what they’re looking for on the first try. Creating—whether it be a painting, a paper, or a machine learning model—is a process that has a starting point from which new elements and ideas are added and old ones are modified and discarded, sometimes again and again, until the work accomplishes its intended purpose: to evoke emotion, to convey a message, to complete a task. Since I began my work as a researcher, machine learning systems have gotten really good at a particular form of creation that has caught my attention: image generation.
Looking at some of the images generated by systems such as BigGAN and ProGAN, you wouldn’t be able to tell they were produced by a computer. In these advancements, my colleagues and I see an opportunity to help people create visuals and better express themselves through the medium—from improving the user experience when it comes to designing avatars in the gaming world to making the editing of personal photos and production of digital art in software like Photoshop, which can be challenging to those unfamiliar with such programs’ capabilities, easier. Because of our background in dialogue, we see that help happening via natural language. We envision conversational technology that allows people to create images just by talking or typing a series of directions and feedback across multiple iterations. We even think it’s possible for such a system to eventually take a proactive approach, seeking clarification when instructions are ambiguous, essentially participating in a two-way conversation.
Spotlight: Microsoft research newsletter

Microsoft Research Newsletter
Stay connected to the research community at Microsoft.
Our team, comprising researchers from across Microsoft Research Montréal, the Vector Institute, and the Mila – Quebec AI Institute, recently introduced the Generative Neural Visual Artist (GeNeVA) task and a recurrent generative adversarial network (GAN)–based model, GeNeVA-GAN, to tackle it. In the GeNeVA task, a Teller, or user, gives an instruction to the Drawer, our system, and the Drawer generates an image corresponding to the instruction. The Teller then continues to provide further instructions for modifying the resulting image, and the Drawer continues to generate a modified image.

Figure 1: In the Generative Neural Visual Artist (GeNeVA) task, the Drawer—a generative adversarial network-based model—iteratively constructs a scene based on instructions and feedback from a Teller, or user.
The task at hand
Work in the field of text-based image generation has mainly been dominated by one-step generation, which unfortunately doesn’t easily lend itself to more complex images people may be interested in creating; let’s say, a park scene with multiple people picnicking, tossing a football, or participating in other activities. You’d need a potentially large and detailed paragraph to elicit such an output. Plus, it doesn’t allow for the creative process as people naturally experience it. Unless you’ve specified things very precisely in the provided text—place the object one inch from the left and two from the top, for example—you won’t get exactly what you want.
The GeNeVA task places the focus on iteration, testing potential models on a couple of fronts: their ability to convert instructions into appropriate image modifications and their ability to maintain previous instructions and image properties, such as spatial relationships, across versions of the image. Since real-world image data paired with instructions is not available in large quantities, we use simpler datasets for this task. We introduce the Iterative CLEVR dataset—i-CLEVR, for short—an iterative version of the Compositional Language and Elementary Visual Reasoning (CLEVR) dataset in which the scenes are created step-by-step using natural language instructions. We also use the Collaborative Drawing (CoDraw) dataset, which consists of clip-art scenes of children playing in a park.
Recurrent GAN—our approach!
With the goal of ultimately extending the GeNeVA task to photo-realistic images, we chose to use a GAN–based model, as GANs are on the forefront of image generation in the pixel space today.
While a non-pixel-based approach—where the placement of clip art or cutouts of objects from real images is predicted, as in the task associated with the CoDraw dataset—is easier, copy and paste can lead to less natural-looking images. A pixel-based approach allows for the expression of lighting differences, a variety of angles for each object, and other characteristics that make for realistic images. To achieve the same effect with a non-pixel-based approach, you’d need an infinite collection of clip art representing these detailed distinctions.
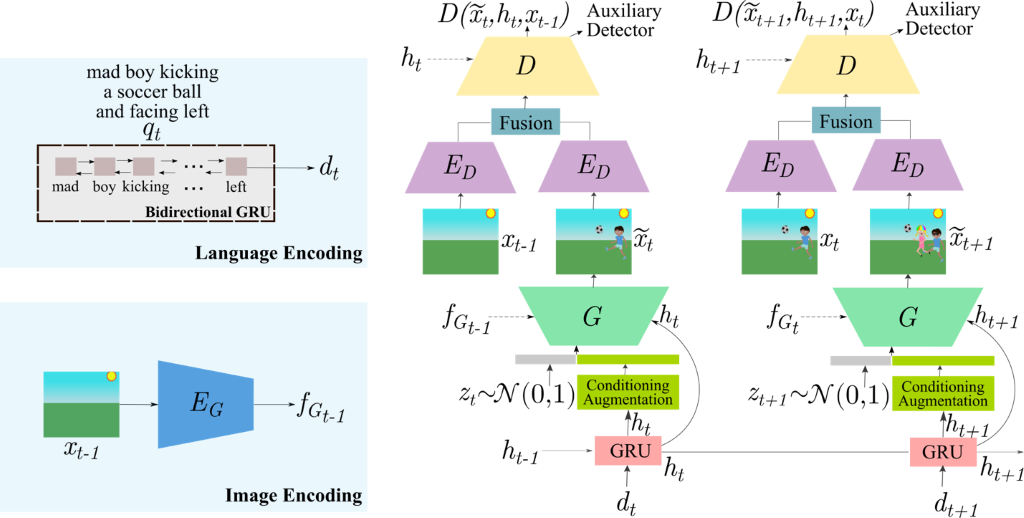
Figure 2: To ensure the system maintains image details across iterations and makes modifications based on the history of instructions provided, the GeNeVA-GAN architecture incorporates a gated recurrent unit (GRU)–based recurrent neural network to encode the current instructions and previous instructions and a convolutional neural network encoder to create a representation of the previous image. Both representations are passed through the generator G. An auxiliary object detector is added to the discriminator D, which allows the discriminator to determine whether the instructions were followed properly.
To tackle the task, we integrated several other machine learning components into the GAN model, including a recurrent neural network, specifically a gated recurrent unit (GRU); a convolutional neural network (CNN)–based image encoder; and an auxiliary object detector.
Traditional GAN models consist of two components: a generator, which produces an output given some input, and a discriminator, which differentiates between the generated data and the ground-truth data. To achieve the iterative approach we were seeking, we apply the generator at each instruction, or timestep, and modified the GAN architecture to use features from the previous timestep. Because it’s integral for the system to adhere to the previously provided instructions, we incorporated a hierarchical GRU-based recurrent neural network to encode not only the current instruction, but also the entire state of the conversation. These representations are then passed on to the next step.
With just the text, though, there is no guarantee the modified image would carry over the same properties the user just saw and responded to, the user’s current instruction aside. There could be multiple plausible ways of generating the image from the provided instructions. In the CoDraw samples of clip-art scenes in which two children are playing in the park, for example, placing the girl to the left of the boy could mean many positions— right beside him, at the very far left of him, and everywhere in between. We want the system to maintain the precise details of the previous image—to remember what was already drawn and how—not regenerate the image from scratch every time. To ensure this consistency, we include features from the previous image encoded using a CNN.
To continue to preserve the integrity of the iterative approach, we integrate into the discriminator an auxiliary object detector, enabling the discriminator to determine whether the objects in the instructions were properly generated in addition to determining whether the image is a quality image.

Figure 3: Example images generated by our best GeNeVA-GAN model on the CoDraw (top row) and i-CLEVR (bottom row) datasets; shown with the provided instructions.
Face-off—iterative vs. non-iterative
In experiments, our iterative approach outperforms a non-iterative GeNeVA-GAN baseline that receives all the instructions and then only generates a single final image. Metrics commonly used for evaluating GANs only consider the generated image quality and not whether the image is accurate for the provided instruction. Hence, we also propose a relationship similarity metric, called rsim, that evaluates the model’s ability to place objects in a position that aligns with the instructions. This new metric measures whether the left-right, front-behind relationships among objects in the ground-truth reference image are followed in the generated image. For determining objects and their locations, we train an object detector and localizer model. We also use the trained object detector to evaluate precision, recall, and F1 score on object detections. The performance of both the non-iterative and our best iterative model on these metrics and on rsim is presented below in Table 1.

Table 1: Results of the GeNeVA-GAN model on the CoDraw and i-CLEVR datasets. Precision, recall, and F1 score measure object detection performance on the generated image with regard to ground-truth labels; rsim measures to what extent left-right, front-behind relationships between objects in the ground-truth image are followed in the generated image. The iterative GeNeVA-GAN model can build on previous context and perform better than the non-iterative baseline.
For more details, please check out our paper “Tell, Draw, and Repeat: Generating and Modifying Images Based on Continual Linguistic Instruction,” which we’re presenting at the 2019 International Conference on Computer Vision (ICCV). Source code to generate the CoDraw and i-CLEVR datasets and code to train and evaluate GeNeVA-GAN models can be found on our project page.


