
 (opens in new tab)Public competitions often help to advance the state of the art in challenging research problems. They frame a question, provide relevant data, and define evaluation metrics so that researchers across the world can work toward a shared goal—and ultimately learn from each other’s advances. The TextWorld team at Microsoft Research Montreal proposed “First TextWorld Problems” (FTWP), a machine learning competition that ran from January 2019 to July 2019, to encourage research on machines that interact with and learn from the world through language.
(opens in new tab)Public competitions often help to advance the state of the art in challenging research problems. They frame a question, provide relevant data, and define evaluation metrics so that researchers across the world can work toward a shared goal—and ultimately learn from each other’s advances. The TextWorld team at Microsoft Research Montreal proposed “First TextWorld Problems” (FTWP), a machine learning competition that ran from January 2019 to July 2019, to encourage research on machines that interact with and learn from the world through language.
The last year or so has seen remarkable advances in natural language processing (NLP), driven especially by large-scale pre-training of massive language models: ELMo, BERT, XLNET, and their ilk. However, we and others (opens in new tab) hypothesize that there is only so much a system can learn about language, from language itself, by processing massive text data. Deeper understanding requires language to be grounded in one’s world since words refer to things and actions (also ideas and places and so on) outside language that a model might never perceive in language modelling. Wittgenstein claimed that the meaning of a word is to be found in its use, and he illustrated this notion via language games (opens in new tab).
Text-based games like Zork (opens in new tab) are a modern take on Wittgenstein’s notion (well, not that modern). Text-based games ground words in a simulated environment and its dynamics. A human or machine player observes the world through text, which describes the surroundings—like There’s a locked door to your left—and both navigates and manipulates the world through short text utterances—such as pick up key, unlock door. See Figure 1 for an illustration of how text-based games work. Success in these games requires the player to understand what words “do.” It is this interactive use of language, and the possibility of teaching this use to machines, that inspired us to build FTWP, a text-based game competition.
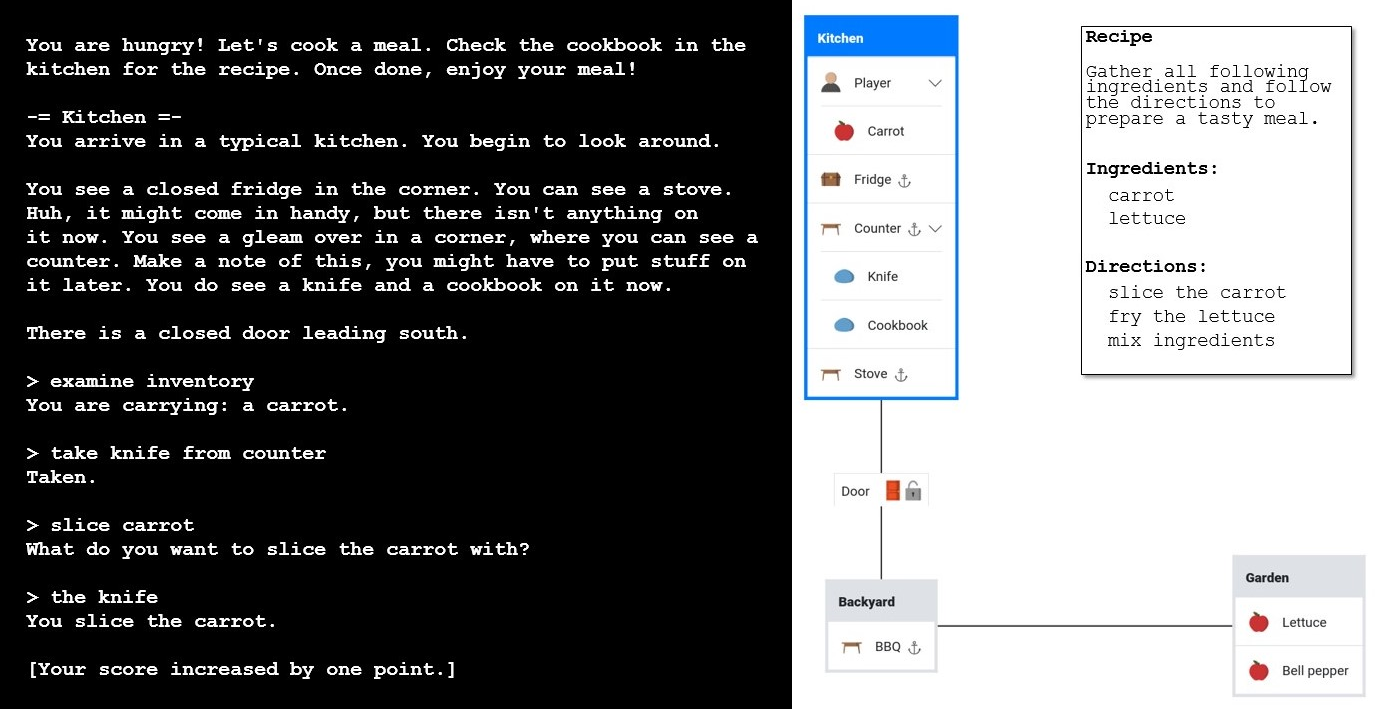

(opens in new tab) Figure 1: An Introduction for one of the text games followed by four commands resulting in slicing the carrot (left). A visual representation of the game (right).
First TextWorld Problems presents complex machine learning challenges
Text-based games require not just language understanding and use, but also memory, planning, and exploration—all active areas of research in machine learning (ML). They can be described, formally, as partially observable Markov decision processes (POMDPs (opens in new tab)) and are well suited to techniques of Reinforcement Learning (RL). One of our goals in hosting FTWP was to provide a space for research at the intersection of RL and NLP (opens in new tab).
Because text-based games for human play involve many entangled challenges, we designed FTWP to minimally expose just a few of these. Our competition featured thousands of unique game instances broken down into training, validation, and test games. All games were generated using the TextWorld framework (opens in new tab) to share the same overarching theme: an agent finds itself hungry in a simple modern house with the goal of gathering ingredients and cooking a meal.
The agent must determine the necessary ingredients from a recipe book found in the kitchen, explore the house to find them, and then return to the kitchen to prepare them according to the recipe. The agent must use appropriate tools, like knives and frying pans, to prepare the meal. Along the way, it must overcome obstacles, like closed doors.
To solve FTWP games, agents must learn:
- To perceive the underlying game state based solely on text descriptions. This is a problem of natural language understanding and partial observability. Partially observable environments require also building some representation of game history.
- To express actions as sequences of words. This is a simplified natural language generation problem. Action commands must respect the grammar of the game engine to be valid, and the commands must “make sense” in the current game state to affect the environment. (A door cannot be unlocked without a key, for example.)
- To understand the overarching task and how different actions lead to different outcomes. The agent must explore, use items, and recognize the progress it has made and what remains to be done to complete the meal.
The last important challenge posed by FTWP is generalization. In each individual game instance, the necessary ingredients and their locations change along with the layout of the house. At test time, agents even encounter food types never seen during training. This means that agents cannot simply memorize a procedure to succeed. They must learn a general method for hunting, gathering, and preparing that transfers across games. This distinguishes our competition from many previous game-based settings for RL, where training and testing occur in the same instance. We believe our setup better encourages agents to learn abstract world and task structure as well as how to ground language in their environment.
First TextWorld Problems by the numbers: mechanics, scoring, and handicaps
FTWP ran from January 1st to June 30th, 2019. A total of 16 teams participated actively, from all around the world. The competition was split into two phases: training and evaluation. During the training phase (about 7 months), participants leveraged the training set of 4,440 games to build and optimize their agents. In this phase participants could also submit trained agents to be scored on the 222 withheld validation games. This gave participants an idea of how their agents generalized. For the final evaluation phase, we selected the best submitted agent for each participant (according to validation performance) and tested it on the hidden test set of 514 games.
To score an agent, we let it play each test game 10 times (that is, 10 episodes) with a budget of 100 commands per episode. While playing, an agent earns one point for each of the following: (1) it picks up an ingredient that is part of the recipe, (2) it prepares an ingredient as per the recipe, (3) it completes the recipe, and (4) it eats the meal—at which point the game ends.
To make the competition more approachable, agents may request additional state information from the game engine. However, doing so incurs a penalty depending on the type of information requested. An agent’s handicap is defined as the highest handicap number associated with the requested information, as follows. Numbers in parentheses represent the score multiplier for the given handicap.

And the winner of the First TextWorld Problems competition is…
Pedro Lima (opens in new tab), data scientist and partner at Cognitiva, a consulting company from Portugal.
Congratulations!
So, how did he do it? The short answer: a clever combination of specialized BERT models, plus some optimism in the face of uncertainty.
“This TextWorld competition offers a large number of very simple games, making it possible to build agents that are able to progress and complete games,” Lima says. His winning agent builds a representation of the game state based on the location and inventory descriptions from the TextWorld engine (equivalent to the feedback from commands “look” and “inventory,” a handicap of 1).
Lima’s agent also used the command templates from TextWorld (a handicap of 2) to build a list of potential commands at each step. The agent must fill slots in these templates with entities from the location and inventory texts, so Lima trained a specialized BERT model with a token classification head to do named-entity recognition and populate the templates.
Given the game state and the constructed set of potential commands, the task is to select the best command for the current state. Lima trained a model to predict a probability value independently for each command, again based on a pre-trained BERT model with a specialized output head. This classification model takes text pairs as input, where the first text element is the game state, and the second is a command option.
This follows the basic formulation of a question-answering model and can be seen as computing state-action values. “It is possible [in this competition] to try different ideas and see the impact in the performance metric,” Lima explains. “The concept of handicaps also makes it easier to start by focusing only on the best command decision and then increase the scope of the agent to also generate the commands.”
The agent’s final decision on which command to issue is based not only on the relation between the command and the current state, but also on history (the state trajectory the agent has taken up to that step). Without this, the agent could not deal with partial observability nor have any sense of its progress toward the goal. Lima’s agent uses a UCB1 (opens in new tab)-like formula for this purpose. UCB1 is an optimistic bandit algorithm that balances exploration and exploitation via tighter reward estimates for actions that have been tried more often.
Lima’s agent maintains a count of how many times each command has been executed in each state and uses UCB1 to adjust the command probabilities from the second BERT module accordingly: it increases the probability assigned to commands used less in the past. After this adjustment, the agent selects the command with the highest probability to issue to the game engine.

Lima’s agent obtained a raw score of 91.9% of the maximum possible across the 514 test games, indicating that it generalized effectively from the training set. Because it used command templates and the outputs from the look and inventory commands, we applied a score multiplier of 0.77 (handicap 2) to arrive at a final, penalized score of 70.8%. For comparison, the second-place agent achieved raw and penalized scores of 85.6% and 65.9% respectively. That agent was also assigned handicap 2.
Remaining challenges and thoughts for the future of machine learning
Now that the dust has settled on “First TextWorld Problems,” we turn our eyes to the future. What did we learn in hosting the competition? First, that representations from powerful, pre-trained language models (such as BERT) can be harnessed in RL settings to build effective, general policies. This line of research has been advocated convincingly here (opens in new tab), and we think the FTWP results provide good motivation to push further in that direction. Second, that under the right constraints and by mixing generation with structure, large, compositional action spaces can be tackled successfully.
On the other hand, the winning submission makes clear that the games of FTWP do not require significant or complex long-term planning. While Pedro Lima’s agent earned just over 90% of the possible points, its capacity for state tracking, reasoning, and planning is clearly limited. “There is still a large gap between the TextWorld games in this competition and real games,” says Lima on the difficulty level of FTWP.
It is likely that his agent’s BERT modules and the command templates reduced the search space enough for the agent to stumble upon a simple yet general strategy. We consider this a limitation of the games themselves rather than the models that tackled them. It is possible to generate more challenging and involved game types within the TextWorld framework, and we will consider doing so for a future competition. But don’t take our word for it. Ask the winner himself. “It would be very interesting to have a second TextWorld competition with a larger space of objectives and entities, games that are a step closer to real games but still simpler, so that we can have the fun of seeing our agents solve some games to the end.”



