

Text to speech (TTS) has attracted a lot of attention recently due to advancements in deep learning. Neural network-based TTS models (such as Tacotron 2, DeepVoice 3 and Transformer TTS) have outperformed conventional concatenative and statistical parametric approaches in terms of speech quality. Neural network-based TTS models usually first generate a mel-scale spectrogram (or mel-spectrogram) autoregressively from text input and then synthesize speech from the mel-spectrogram using a vocoder. (Note: the Mel scale is used to measure frequency in Hertz, and the scale is based on pitch comparisons. A spectrogram is a visual representation of frequencies measured over time.)
Due to the long sequence of the mel-spectrogram and the autoregressive nature, those models face several challenges:
- Slow inference speed for autoregressive mel-spectrogram generation, given the mel-spectrogram sequence usually has a length of hundreds or thousands of frames.
- Synthesized speech is usually not robust, with words being skipped and repeated, due to error propagation and the wrong attention alignments between text and speech in the autoregressive generation based on an encoder-attention-decoder framework.
- Lack of controllability due to the fact that the generation length is automatically determined by the autoregressive generation, and so the voice speed and the prosody (such as word breaks) cannot be adjusted.

GigaPath: Whole-Slide Foundation Model for Digital Pathology
Digital pathology helps decode tumor microenvironments for precision immunotherapy. In joint work with Providence and UW, we’re sharing Prov-GigaPath, the first whole-slide pathology foundation model, for advancing clinical research.
To address the above problems, researchers from Microsoft and Zhejiang University propose FastSpeech, a novel feed-forward network that generates mel-spectrograms with fast generation speed, robustness, controllability, and high quality. The paper accompanying our research, titled “FastSpeech: Fast, Robust and Controllable Text to Speech (opens in new tab),” has been accepted at the thirty-third Conference on Neural Information Processing Systems (opens in new tab) (NeurIPS 2019). FastSpeech utilizes a unique architecture that improves performance in a number of areas when compared to other TTS models. These conclusions resulted from our experiments with FastSpeech, which are detailed in greater length later in this post.
Experiments on the LJ Speech dataset, as well as on other voices and languages, demonstrate that FastSpeech has the following advantages. Briefly outlined, it is:
- fast: FastSpeech speeds up the mel-spectrogram generation by 270 times and voice generation by 38 times.
- robust: FastSpeech avoids the issues of error propagation and wrong attention alignments, and thus nearly eliminates word skipping and repeating.
- controllable: FastSpeech can adjust the voice speed smoothly and control the word break.
- high quality: FastSpeech achieves comparable voice quality to previous autoregressive models (such as Tacotron 2 and Transformer TTS).
Deconstructing the model framework that powers FastSpeech
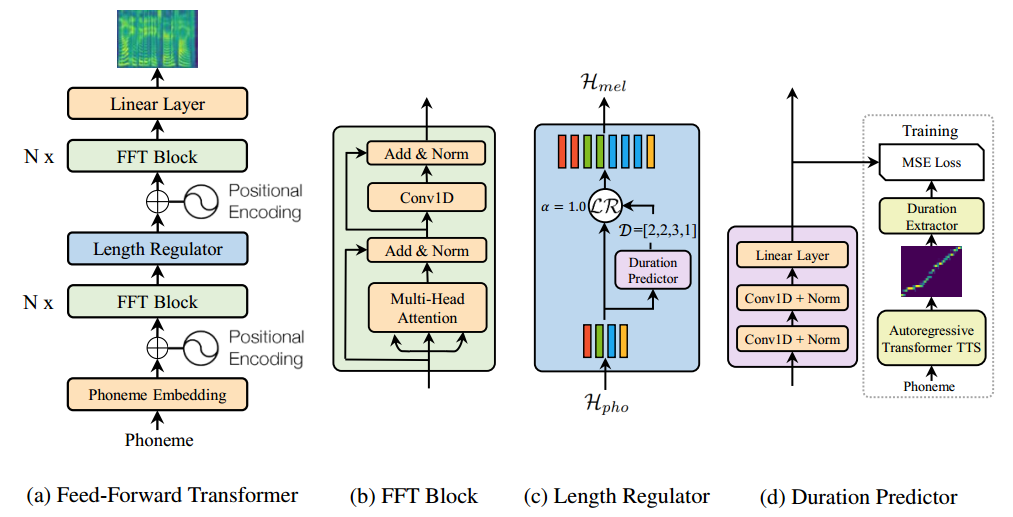
(opens in new tab) Figure 1: The overall architecture for FastSpeech. (a) The feed-forward transformer. (b) The feed-forward transformer block. (c) The length regulator. (d) The duration predictor. MSE loss denotes the loss between predicted and extracted duration, which only exists in the training process.
Feed-Forward Transformer
FastSpeech adopts a novel feed-forward transformer structure, discarding the conventional encoder-attention-decoder framework, as shown in Figure 1a. The major component of the feed-forward transformer is the feed-forward transformer block (FFT block, as shown in Figure 1b), which consists of self-attention and 1D convolution. FFT blocks are used for the conversion from phoneme sequence to mel-spectrogram sequence, with N stacked blocks in the phoneme side and mel-spectrogram side, respectively. Uniquely, there is a length regulator in between, which is used to bridge the length mismatch between the phoneme and mel-spectrogram sequences. (Note: Phonemes are the small, distinct sounds of speech.)
Length Regulator
The model’s length regulator is shown in Figure 1c. Since the length of the phoneme sequence is smaller than that of the mel-spectrogram sequence, one phoneme corresponds to several mel-spectrograms. The number of mel-spectrograms that aligns to a phoneme is called phoneme duration. The length regulator expands the hidden sequence of phonemes according to the duration in order to match the length of a mel-spectrogram sequence. We can increase or decrease the phoneme duration proportionally to adjust the voice speed and can also change the duration of blank tokens to adjust the break between words in order to control part of the prosody.
Duration Predictor
The duration predictor is critical for the length regulator to be able to determine the duration of each phoneme. As shown in Figure 1d, the duration predictor consists of a two-layer 1D convolution and a linear layer to predict the duration. The duration predictor stacks on the FFT block in the phoneme side and is jointly trained with FastSpeech through a mean squared error (MSE) loss function. The label of the phoneme duration is extracted from the attention alignment between the encoder and decoder in an autoregressive teacher model. Please refer to the paper for more details.
FastSpeech experiment results show improved TTS capabilities
In order to verify the effectiveness of FastSpeech, we evaluated the model from several perspectives: voice quality, generation speed, robustness, and controllability. We conducted our experiments on the LJ Speech dataset, which contains 13,100 English audio clips and the corresponding text transcripts, with the total audio length of approximately 24 hours. We randomly split the dataset into three sets: 12,500 samples for training, 300 samples for validation, and 300 samples for testing. FastSpeech is trained under the teacher-student framework: the teacher is the autoregressive TTS model that is used for sequence-level knowledge distillation and duration extraction, and the student model is the FastSpeech model.
Voice Quality
We conducted the mean opinion score (MOS) evaluation on the test set to measure the audio quality. Each audio is listened to by at least 20 testers, who are all native English speakers. We compared the MOS of the generated audio samples by our FastSpeech model with other systems, which include: 1) GT, the ground truth audio; 2) GT (Mel + WaveGlow), where we first convert the ground truth audio into mel-spectrograms, and then convert the mel-spectrograms back to audio using WaveGlow; 3) Tacotron 2 (Mel + WaveGlow); 4) Transformer TTS (Mel + WaveGlow); and 5) Merlin (WORLD), a popular parametric TTS system with WORLD as the vocoder. The results are shown below in Table 1. It can be seen that FastSpeech nearly matches the quality of the Transformer TTS model and Tacotron 2, and the audio comparison can be heard in our demo (opens in new tab).

(opens in new tab) Table 1: The MOS with 95% confidence intervals.
Inference Speedup
We evaluated the inference latency of FastSpeech and compared it with the autoregressive Transformer TTS model, which has a similar number of model parameters to FastSpeech. It can be seen from Table 2 that FastSpeech speeds up the mel-spectrogram generation by about 270 times and speeds up the end-to-end audio synthesis by about 38 times.

(opens in new tab) Table 2: The comparison of inference latency with 95% confidence Intervals. The evaluation is conducted on a server with 12 Intel Xeon CPUs, 256GB memory, and 1 NVIDIA V100 GPU. The average length of the generated mel-spectrograms for the two systems are both about 560.
Robustness
The encoder-decoder attention mechanism in the autoregressive model may cause wrong attention alignments between phoneme and mel-spectrogram, resulting in instability with word repeating and skipping. To evaluate the robustness of FastSpeech, we selected 50 sentences that are particularly hard for TTS systems and counted the errors in Table 3. It can be seen that Transformer TTS is not robust when it comes to these hard cases and gets a 34% error rate, while FastSpeech can effectively eliminate word repeating and skipping to improve intelligibility, as can also be observed in our demo (opens in new tab).

(opens in new tab) Table 3: The comparison of robustness between FastSpeech and Transformer TTS on the 50 particularly hard sentences. Each kind of word error is counted at most once per sentence.
Length Control
FastSpeech can adjust the voice speed through the length regulator, varying speed from 0.5x to 1.5x without loss of voice quality. You can refer to our page (opens in new tab) for the demo of length control for voice speed and word break, which includes recordings of FastSpeech at various speed increments between 0.5x and 1.5x.
Ablation Study
We also studied the importance of the components in FastSpeech, including 1D convolution in FFT block and the sequence-level knowledge distillation. The CMOS evaluation is shown in Table 4. As can be seen, both 1D convolution in FFT block and the sequence-level knowledge distillation are important to ensure the voice quality of FastSpeech.

We conducted experiments on more voices and languages as well, and we found that FastSpeech can always match the voice quality of the autoregressive teacher model, with the benefits of extremely fast generation, robustness, and controllability. For future works, we will combine the optimization of FastSpeech and parallel vocoder in a single model for a purely end-to-end TTS solution.
If you are attending NeurIPS 2019, our research will be a part of the poster session on Wednesday, December 11th, from 5:00 PM PST to 7:00 PM PST. We encourage you to learn more about FastSpeech there! Further detail for FastSpeech and our experiments can be found in our paper (opens in new tab), and at the demo link: https://speechresearch.github.io/fastspeech/ (opens in new tab)



