

Making sense of the world around us is a skill we as human beings begin to learn from an early age. Though there is still much to know about the process, we can see that people learn a lot, both directly and indirectly, from observing and interacting with their environments and other people in them: an uncle points to a shiny red piece of fruit and tells his nephew it’s an apple; a teacher reads a book about a hungry caterpillar that turns into a butterfly; a child observes her parents talking about the mail and the mail carrier who delivered it as they shuffle white envelopes with printed lettering and stamps back and forth. Even if the context around an object changes—a flower in a vase on the kitchen table versus a flower planted in the ground in the backyard versus a field of many flowers—children are able to make new associations and adjust old ones as information is gained and call on their implicit commonsense knowledge to figure out what they encounter. The more we interact with our physical environments, our screens, photographs, and books, the better we become at understanding and using language to explain the items that exist and the things that are happening in our surroundings.
For machines, on the other hand, scene understanding and language understanding are quite challenging to hone, especially with only weak supervision, essentially the indirect learning people are able to leverage so well. Without exact labels for all the components in a scene to learn from, machines struggle to gain a solid foundation on which to build other capabilities that require scene and language understanding. Collecting the necessary labels is usually expensive, and even good labels provide only a reasonable understanding of the scene, not the language.
Spotlight: Event Series

Microsoft Research Forum
Join us for a continuous exchange of ideas about research in the era of general AI. Watch the first four episodes on demand.
The main question becomes, then, whether we can leverage the large amount of image-text pairs available on the web to mimic the way people improve their scene and language understanding. Can we build a model that unifies machine capabilities to perform well on both vision-language generation tasks and understanding tasks?
In our paper “Unified Vision-Language Pre-Training for Image Captioning and VQA,” we present a unified single-model encoder-decoder system capable of two disparate tasks: image captioning and visual question answering (VQA). Generating descriptions for scenes and answering natural language questions about them are good indicators of a system’s overall effectiveness at both scene understanding and language understanding. We believe the model, which we’re calling the Vision-Language Pre-training (VLP) model, is among the first to use data from both language and vision to show significant improvements on different downstream tasks. Our proposed model, which is open source on GitHub, was pre-trained using three million image-text pairs. If we can further take advantage of the vast amount of publicly available visuals with text data provided—think large corpora of movies with subtitles and human conversations grounded in images and videos, such as comments under an image or video posted on social media—we see machine scene and language understanding reaching human parity.
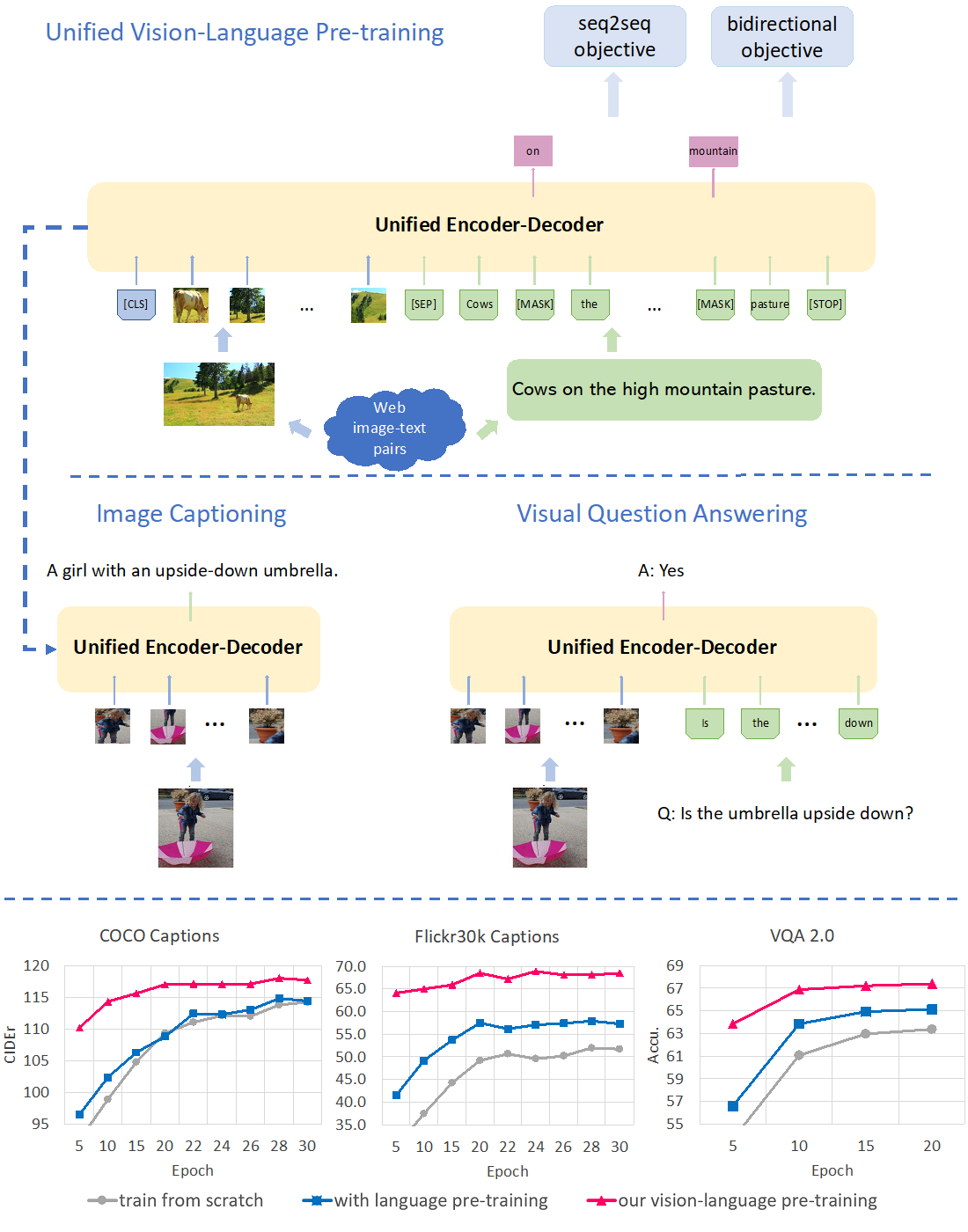
Microsoft researchers have developed a unified encoder-decoder model for general vision-language pre-training that they fine-tuned for image captioning and visual question answering. With the vision-language pre-training, both training speed and overall accuracy have been significantly improved on the downstream tasks compared to random initialization or language-only pre-training.
Improving on current models
Existing approaches for image captioning and VQA suffer from low-quality captions and reasoning capabilities. This is mainly due to three reasons:
- They’re not effective enough to leverage context, which is a very important capability, especially when there are various objects, relationships, and concepts in the given scene. Moreover, the model should be capable of identifying important components to describe images accurately and perform reasoning about them given a natural language question.
- They’re not leveraging large-scale training data for pre-training. This is crucial to learn universal representations for both language and vision that are practically useful for many downstream tasks, not just image captioning and VQA.
- Their architecture is not designed to perform equally well on diverse sets of tasks where both language and vision alignment—as is needed for VQA and information retrieval, for example—and language generation are performed using a single model.
VLP seeks to overcome the above limitations with an architecture that:
- deploys a shared multi-layer transformer network for encoding and decoding;
- is optimized for both bidirectional and sequence-to-sequence prediction; and
- incorporates special masks in a self-attention mechanism to enable a single model performing both generation and understanding tasks over a given scene.
In current approaches where models are pre-trained to handle multiple tasks, their encoders and decoders are pre-trained separately or just their encoders are pre-trained. But we pre-train the encoder and decoder together and optimize for both bidirectional and sequence-to-sequence prediction. Doing so creates better aligned encoder and decoder representations, allowing the same model to be used for tasks as different as image captioning and VQA.
Testing and evaluation
We evaluated VLP’s ability to caption and reason over images on three challenging benchmarks: COCO, Flickr30K, and VQA 2.0. VLP outperformed baseline models and state-of-the art models on several image captioning and VQA metrics, proving to be more accurate and converging faster during training.
Qualitative results on COCO and VQA 2.0 (Figure 2 below) show VLP is not only able to key in on more details when generating captions, as demonstrated by its caption for the first photo, but it also can be capable of answering challenging questions about the image where previous models trained only on language fail to answer them correctly. For example, VLP is able to identify the similarity in clothing design among different people in the first photo and recognizes the person is not taking his own picture in the second photo.
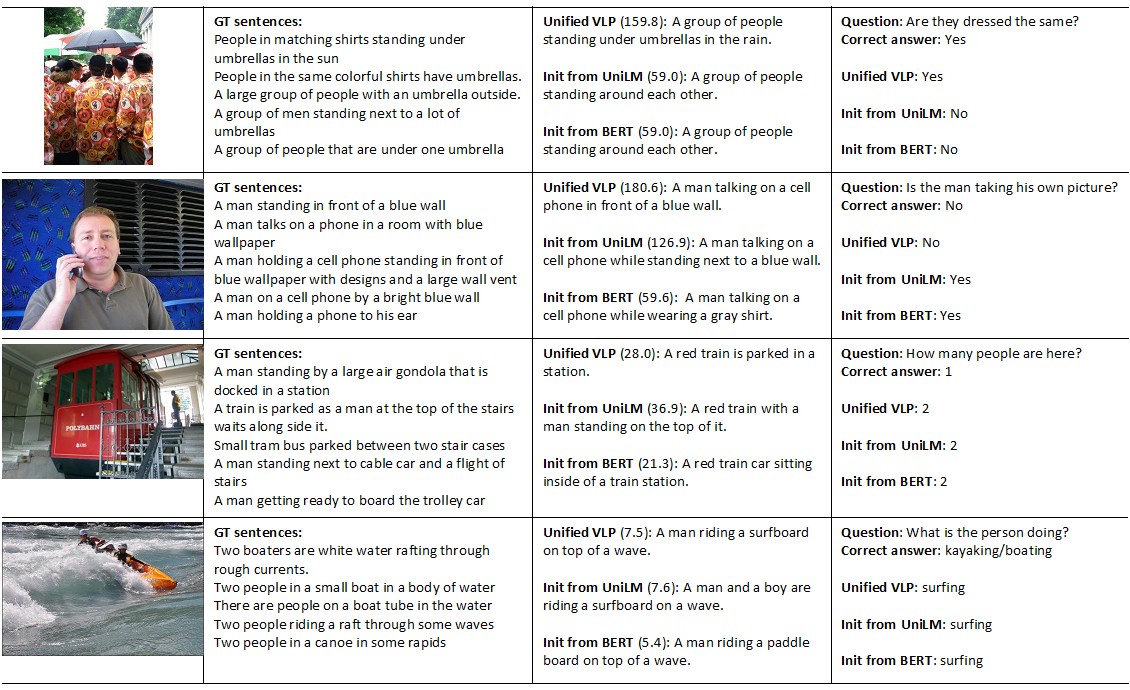
Figure 2: The above table shows qualitative examples on COCO and VQA 2.0. The first column indicates images from the COCO validation set. The second column shows the five human-annotated ground-truth (GT) captions. The third column indicates captions generated by three different models and their corresponding CIDEr scores, a metric used to evaluate caption quality. Only Unified VLP has vision-language pre-training. The last column shows VQA questions and correct answers associated with the image and answers generated by the models. The top two are successful cases and the bottom two are failed cases.
Looking ahead
People learn to understand language and how it relates to their environment as children by observing and interacting with various objects and events surrounding them. For machines, that interaction happens with data such as image-text pairs. With smart model design and smart data selection, we can capitalize on existing publicly available resources to reach even greater heights in language and scene understanding, as evidenced by VLP.
With VLP, we believe we show the potential of unified models to reach the levels of language and scene understanding necessary to successfully complete a variety of distinct downstream tasks—single models that complete multiple tasks efficiently without sacrificing performance. That means more effective and capable vision-language systems without the costs of several separately trained models to achieve the same goals. We look forward to continuing to strengthen the VLP architecture and pre-training method while adding more data during pre-training and a more diverse set of downstream tasks.
This work was spearheaded by University of Michigan PhD student Luowei Zhou during a Microsoft Research internship. University of Michigan Professor Jason J. Corso and Hamid Palangi, Lei Zhang, Jianfeng Gao, and Houdong Hu of Microsoft served as advisors on the work. A special thanks to Furu Wei and Li Dong from Microsoft Research Asia for sharing their initial code base for language pre-training.



