
As part of Microsoft AI at Scale (opens in new tab), the Turing family of NLP models are being used at scale across Microsoft to enable the next generation of AI experiences. Today, we are happy to announce that the latest Microsoft Turing model (T-NLRv5) is the state of the art at the top of SuperGLUE and GLUE leaderboards, further surpassing human performance and other models. Notably, T-NLRv5 first achieved human parity on MNLI and RTE on the GLUE benchmark, the last two GLUE tasks which human parity had not yet met. In addition, T-NLRv5 is more efficient than recent pretraining models, achieving comparable effectiveness with 50% fewer parameters and pretraining computing costs.
- Research Project AI at Scale
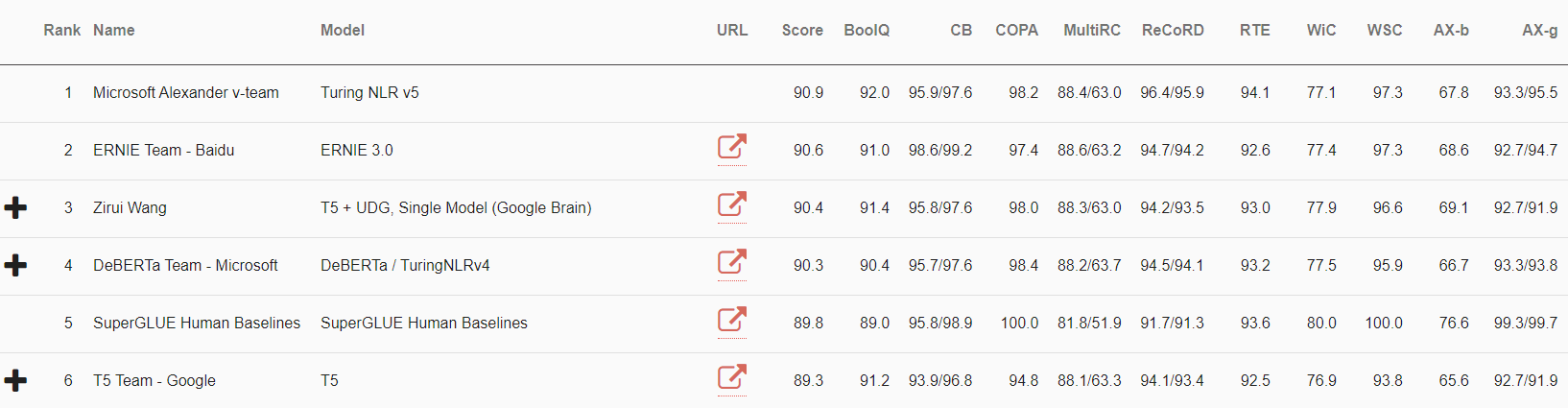
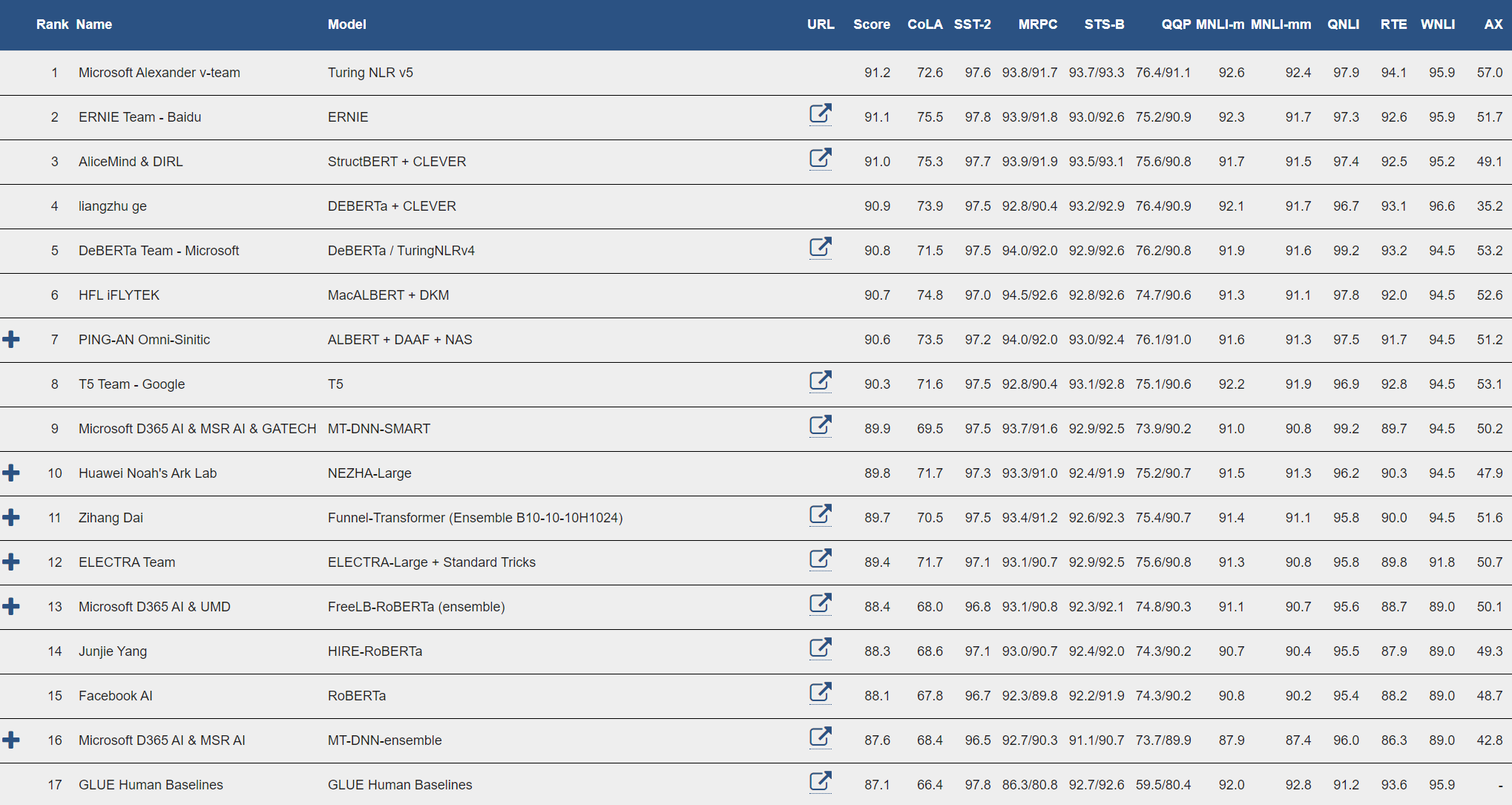
The Turing Natural Language Representation (T-NLRv5) integrates some of the best modeling techniques developed by Microsoft Research, Azure AI, and Microsoft Turing. The models are pretrained at large scale using an efficient training framework based on FastPT and DeepSpeed. We’re excited to bring new AI improvements to Microsoft products using these state-of-the-art techniques.
Model architecture and pretraining task
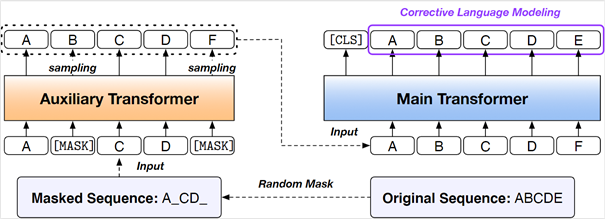
T-NLRv5 is largely based on our recent work, COCO-LM (opens in new tab), a natural evolution of pretraining paradigm converging the benefits of ELECTRA-style models and corrective language model pretraining. As illustrated in Figure 2, T-NLRv5 employs an auxiliary transformer language model to corrupt an input text sequence, and the main transformer model is pretrained using the corrective language model task, which is to detect and correct tokens replaced by the auxiliary model. This augments the ELECTRA model family with language modeling capacity, bringing together the benefits from pretraining with adversarial signals generated from the auxiliary model and the language modeling capacity, which is handy for prompt-based learning.
Spotlight: On-demand video

AI Explainer: Foundation models and the next era of AI
Explore how the transformer architecture, larger models and more data, and in-context learning have helped advance AI from perception to creation.
We also leverage the training dataset and the data processing pipeline optimized for developing previous T-NLR releases, including DeBERTa (opens in new tab) and UniLM (opens in new tab), as well as the implementation optimizations from other Microsoft pretraining research efforts, such as TUPE (opens in new tab).
Another key property of T-NLRv5 is that it maintains the effectiveness of the model at smaller sizes, e.g., base and large size with a few hundred million parameters, to bigger sizes with billions of parameters. This is achieved by careful selection of techniques of maintaining model simplicity and optimization stability. We disabled dropout in the auxiliary model so that the pretraining of the auxiliary model and the generation of the main model’s training data are done in one pass. We also disabled the sequential contrastive learning task in COCO-LM to reduce computing cost. This enables us to stick to the post-layer norm transformer architecture that allows us to train deeper transformer networks more thoroughly.
Efficiently scaling up language model pretraining
Training billion-parameter neural models can be prohibitively expensive in both time and computing costs. This yields a long experimental cycle that slows down scientific developments and raises cost-benefit concerns. In making T-NLRv5, we leveraged two approaches to improve its scaling efficiency to ensure optimal use of model parameters and pretraining compute.
Customized CUDA kernels for mixed precision. We leverage the customized CUDA kernels developed for Fast PreTraining (FastPT), which are customized for transformer architecture and optimized for the speed in mixed precision (FP16) pretraining. This not only significantly improves the efficiency of transformer training and inference by 20%, but also provides better numerical stability in mixed-precision training. The latter is one of the most important needs when pretraining language representation models with billions of parameters.
ZeRO optimizer. When scaling up T-NLRv5 to billions of parameters, we bring in our ZeRO optimizer technique of DeepSpeed, described in a previous blog post, to reduce the GPU memory footprint of pretraining models in multi-machine parallel pretraining processes. Specifically, T-NLRv5 XXL (5.4 billion) version uses ZeRO optimizer stage 1 (optimizer stage partitioning), which reduces the GPU memory footprint by five times.
Achieving best effectiveness and efficiency simultaneously
By combining the above modeling techniques and infrastructure improvements, T-NLRv5 provides the best effectiveness and efficiency simultaneously at various trade-off points. To the best of our knowledge, T-NLRv5 achieves state-of-the-art effectiveness at various model sizes and pretraining computing costs.
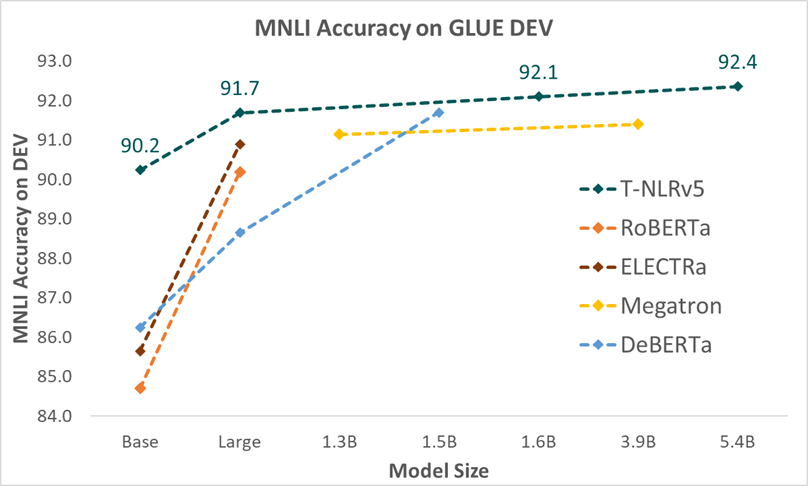
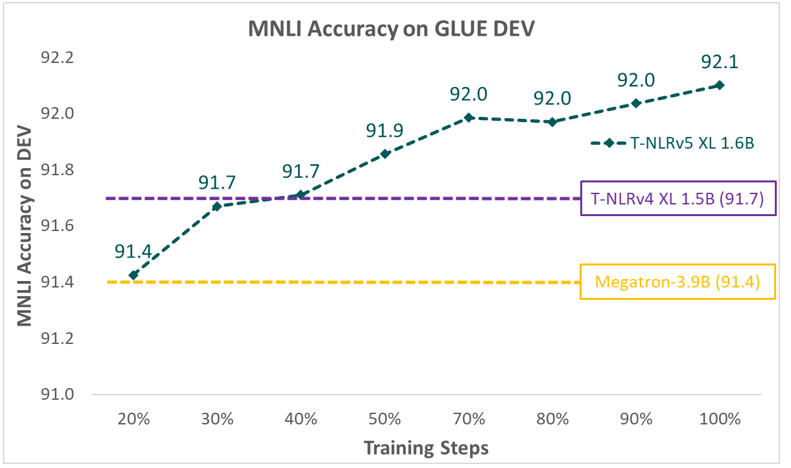
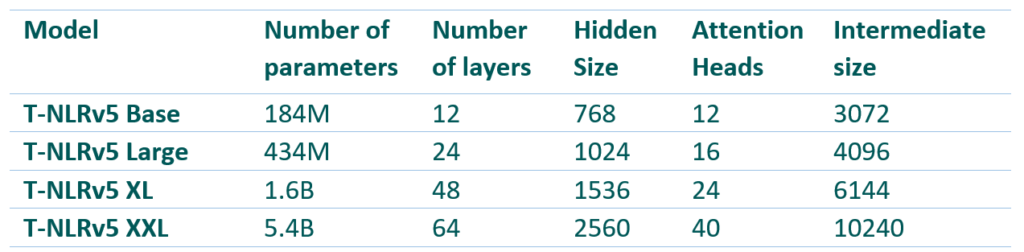
The model configurations for T-NLRv5 variants are displayed in Table 1. As shown in Figure 4 and Figure 5, when measured on MNLI, one of the most stable tasks on GLUE, T-NLRv5 variants with substantially fewer parameters or computing steps often significantly outperform previous pretraining models with larger pretraining costs. T-NLRv5’s base version outperforms RoBERTa Large using 50% of the parameters. Using 434 million parameters, T-NLRv5 Large performs on par with DeBERTa XL (1.5 billion parameters) and outperforms Megatron encoder with 3.9 billion parameters. T-NLRv5 also significantly improves pretraining efficiency: it reaches the accuracy of our latest XL model, T-NLRv4-1.5B with only 40% pretraining steps using the same training corpora and computing environments.
Robust model adaptation
Robustness is important for a model to perform well on test samples, which are dramatically different from training data. In this work, we use two methods to improve the robustness of adapting T-NLRv5 to downstream tasks. The first method enhances model robustness through PDR (posterior differential regularization), which regularizes the model posterior difference between clean and noisy inputs during model training. The second method is multi-task learning, as in multi-task deep neural network (MT-DNN), which improves model robustness by learning representations across multiple NLU tasks. MT-DNN not only leverages large amounts of cross-task data, but also benefits from a regularization effect that leads to more general representations in order to adapt to new tasks and domains.
With these robust model adaptation techniques, our T-NLRv5 XXL model is the first to reach human parity on MNLI in test accuracy (92.5 versus 92.4), the most informative task on GLUE, while only using a single model and single task fine-tuning, i.e., without ensemble.
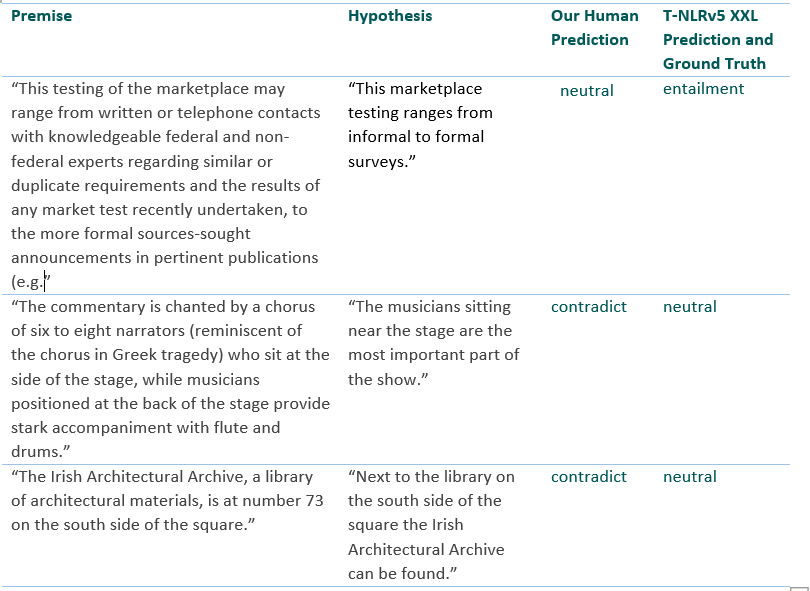
Table 2 presents some examples from MNLI dev-mismatched set where the T-NLRv5 XXL model can predict the correct label, but one of our authors made the wrong prediction. These are quite difficult examples, and we are glad to see T-NLRv5 XXL can accurately complete the task.
T-NLRv5: Release Information
We will make T-NLRv5 and its capabilities available in the same way as with other Microsoft Turing models.
We will leverage its increased capabilities to further improve the execution of popular language tasks in A (opens in new tab)zure Cognitive Services (opens in new tab). Customers will automatically benefit from these.
Customers interested in using Turing models for their own specific task can submit a request to join the Turing Private Preview. Finally, we will make T-NLRv5 available to researchers for collaborative projects via the Microsoft Turing Academic Program.
Learn more:
Explore an interactive demo with AI at Scale models
Learn more about the technology layers that power AI at Scale models (opens in new tab)
Conclusion: Building and democratizing more inclusive AI
The Microsoft Turing model family plays an important role in delivering language-based AI experiences in Microsoft products. T-NLRv5 further surpassing human performance on SuperGLUE and GLUE leaderboards reaffirms our commitment to keep pushing the boundaries of NLP and continuously improving these models so that we can ultimately bring smarter, more responsible AI product experiences to our customers.
We welcome your feedback and look forward to sharing more developments in the future.



