
This research paper was presented at the 2023 IEEE/CVF International Conference on Computer Vision (opens in new tab) (ICCV), a premier academic conference for computer vision.

In the field of deep learning, where breakthroughs like the models ResNet (opens in new tab) and BERT (opens in new tab) have achieved remarkable success, a key challenge remains: developing efficient deep neural network (DNN) models that both excel in performance and minimize latency across diverse devices. To address this, researchers have introduced hardware-aware neural architecture search (NAS) to automate efficient model design for various hardware configurations. This approach involves a predefined search space, search algorithm, accuracy estimation, and hardware-specific cost prediction models.
However, optimizing the search space itself has often been overlooked. Current efforts rely mainly on MobileNets-based search spaces designed to minimize latency on mobile CPUs. But manual designs may not always align with different hardware requirements, limiting their suitability for a diverse range of devices.
In the paper, “SpaceEvo: Hardware-Friendly Search Space Design for Efficient INT8 Inference (opens in new tab),” presented at ICCV 2023, (opens in new tab) we introduce SpaceEvo, a novel method that automatically creates specialized search spaces optimized for efficient INT8 inference on specific hardware platforms. What sets SpaceEvo apart is its ability to perform this design process automatically, creating a search space tailored for hardware-specific, quantization-friendly NAS.
Microsoft research podcast

Abstracts: August 15, 2024
Advanced AI may make it easier for bad actors to deceive others online. A multidisciplinary research team is exploring one solution: a credential that allows people to show they’re not bots without sharing identifying information. Shrey Jain and Zoë Hitzig explain.
Notably, SpaceEvo’s lightweight design makes it ideal for practical applications, requiring only 25 GPU hours to create a hardware-specific solution and making it a cost-effective choice for hardware-aware NAS. This specialized search space, with hardware-preferred operators and configurations, enables the exploration of larger, more efficient models with low INT8 latency. Figure 1 demonstrates that our search space consistently outperforms existing alternatives in INT8 model quality. Conducting neural architecture searches within this hardware-friendly space yields models that set new INT8 accuracy benchmarks.
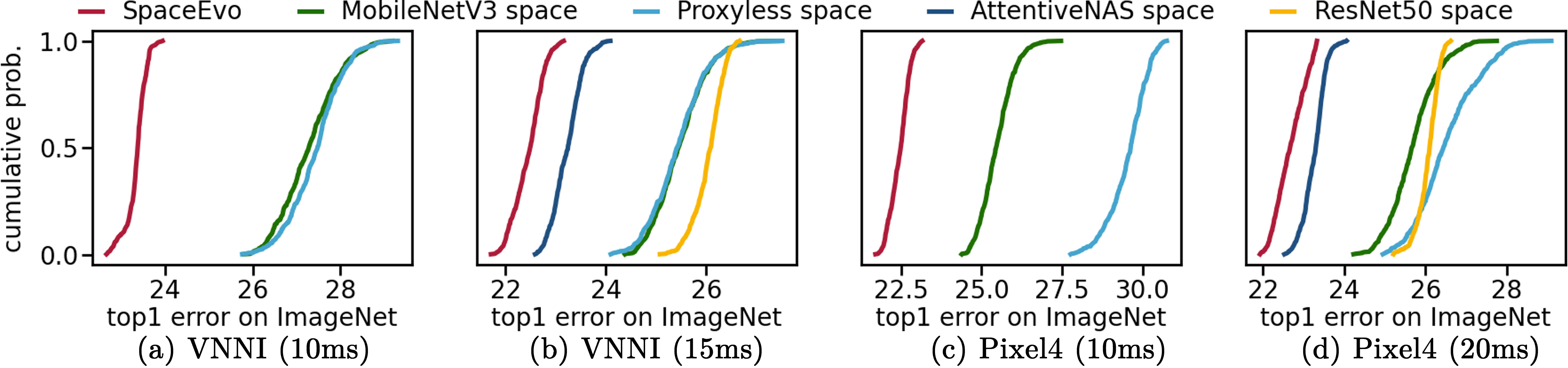
On-device quantization latency analysis
We began our investigation by trying to understand INT8 quantized latency factors and their implications for search space design. We conducted our study on two widely used devices: an Intel CPU with VNNI instructions and onnxruntime support, and a Pixel 4 phone CPU with TFLite 2.7.
Our study revealed two critical findings:
- Both the choice of operator type and configurations, like channel width, significantly affect INT8 latency, illustrated in Figure 2. For instance, operators like Squeeze-and-Excitation and Hardswish, while enhancing accuracy with minimal latency, can lead to slower INT8 inference on Intel CPUs. This slowdown primarily arises from the added costs of data transformation between INT32 and INT8, which outweigh the latency reduction achieved through INT8 computation.
- Quantization efficiency varies among different devices, and preferred operator types can be contradictory.
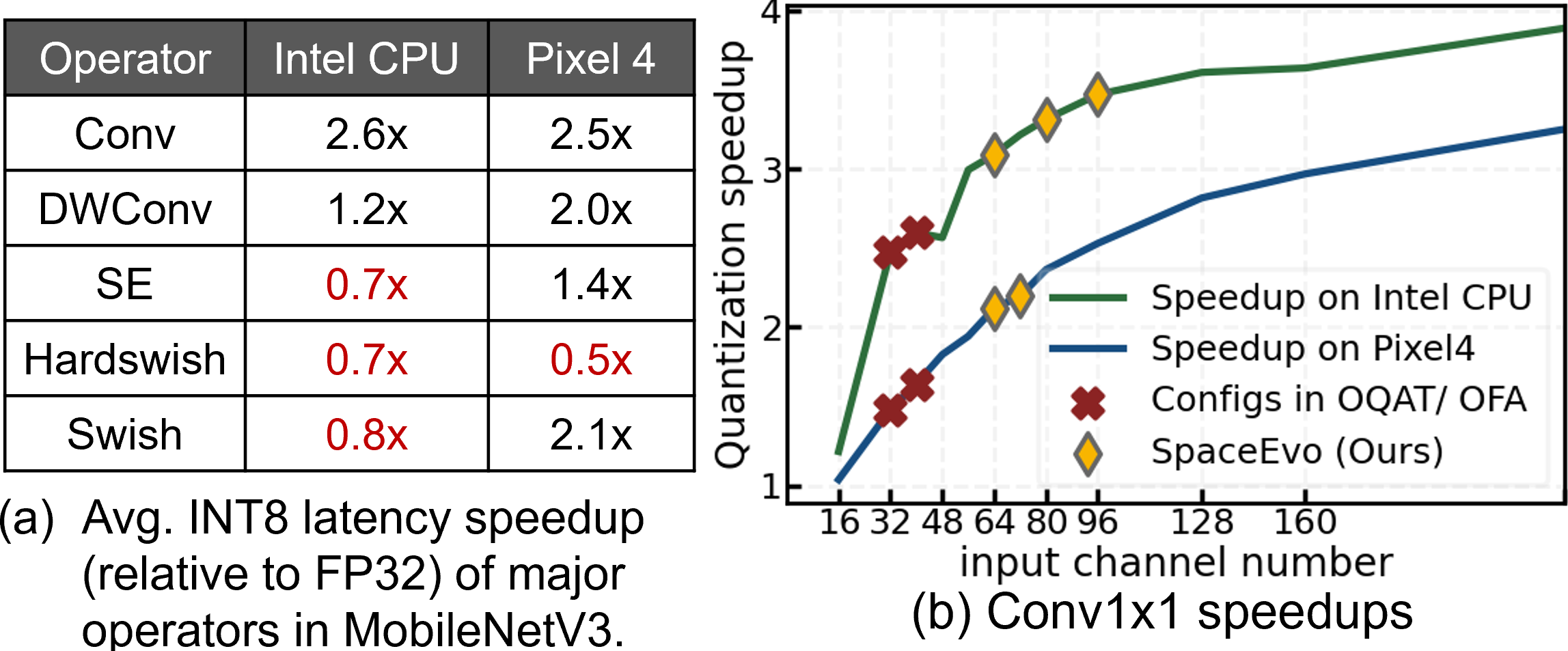
Finding diverse, efficient quantized models with SpaceEvo
Unlike traditional architecture search, which aims to find the best single model, our objective is to uncover a diverse population of billions of accurate and INT8 latency-friendly architectures within the search space.
Drawing inspiration from neural architecture search, we introduced an evolutionary search algorithm to explore this quantization-friendly model population in SpaceEvo. Our approach incorporated three key techniques:
- The introduction of the Q-T score as a metric to measure the quantization-friendliness of a candidate search space, based on the INT8 accuracy-latency of top-tier subnets.
- Redesigned search algorithms that focus on exploring a collection of model populations (i.e., the search space) within the vast hyperspace, as illustrated in Figure 3. This is achieved through the “elastic stage,” which divides the search space into a sequence of elastic stages, allowing traditional evolution methods like aging evolution to explore effectively.
- A block-wise search space quantization scheme to reduce the training costs associated with exploring a search space that has a maximum Q-T score.
After discovering the search space, we employed a two-stage NAS process to train a quantized-for-all supernet over the search space. This ensured that all candidate models could achieve comparable quantized accuracy without individual fine-tuning or quantization. We utilized evolutionary search and nn-Meter (opens in new tab) for INT8 latency prediction to identify the best quantized models under various INT8 latency constraints. Figure 3 shows the overall design process.

Extensive experiments on two real-world edge devices and ImageNet demonstrated that our automatically designed search spaces significantly surpass manually designed search spaces. Table 1 showcases our discovered models, SEQnet, setting new benchmarks for INT8 quantized accuracy-latency tradeoffs.
| (a) Results on the Intel VNNI CPU with onnxruntime | |||||
| Model | Top-1 Acc % | Latency | Top-1 Acc % | FLOPs | |
| INT8 | INT8 | Speedup | FP32 | ||
| MobileNetV3Small | 66.3 | 4.4 ms | 1.1x | 67.4 | 56M |
| SEQnet@cpu-A0 | 74.7 | 4.4 ms | 2.0x | 74.8 | 163M |
| MobileNetV3Large | 74.5 | 10.3 ms | 1.5x | 75.2 | 219M |
| SEQnet@cpu-A1 | 77.4 | 8.8 ms | 2.4x | 77.5 | 358M |
| FBNetV3-A | 78.2 | 27.7 ms | 1.3x | 79.1 | 357M |
| SEQnet@cpu-A4 | 80.0 | 24.4 ms | 2.4x | 80.1 | 1267M |
| (b) Results on the Google Pixel 4 with TFLite | |||||
| MobileNetV3Small | 66.3 | 6.4 ms | 1.3x | 67.4 | 56M |
| SEQnet@pixel4-A0 | 73.6 | 5.9 ms | 2.1x | 73.7 | 107M |
| MobileNetV3Large | 74.5 | 15.7 ms | 1.5x | 75.2 | 219M |
| EfficientNet-B0 | 76.7 | 36.4 ms | 1.7x | 77.3 | 390M |
| SEQnet@pixel4-A1 | 77.6 | 14.7 ms | 2.2x | 77.7 | 274M |
Potential for sustainable and efficient computing
SpaceEvo is the first attempt to address the hardware-friendly search space optimization challenge in NAS, paving the way for designing effective low-latency DNN models for diverse real-world edge devices. Looking ahead, the implications of SpaceEvo reach far beyond its initial achievements. Its potential extends to applications for other crucial deployment metrics, such as energy and memory consumption, enhancing the sustainability of edge computing solutions.
We are exploring adapting these methods to support diverse model architectures like transformers, further expanding its role in evolving deep learning model design and efficient deployment.


