

For decades, causal inference methods have found wide applicability in the social and biomedical sciences. As computing systems start intervening in our work and daily lives, questions of cause-and-effect are gaining importance in computer science as well. To enable widespread use of causal inference, we are pleased to announce a new software library, DoWhy (opens in new tab). Its name is inspired by Judea Pearl’s do-calculus for causal inference. In addition to providing a programmatic interface for popular causal inference methods, DoWhy is designed to highlight the critical but often neglected assumptions underlying causal inference analyses. DoWhy does this by first making the underlying assumptions explicit, for example, by explicitly representing identified estimands. And secondly by making sensitivity analysis and other robustness checks a first-class element of the causal inference process. Our goal is to enable people to focus their efforts on identifying assumptions for causal inference, rather than on details of estimation.
Our motivation for creating DoWhy comes from our experiences in causal inference studies over the past few years, ranging from estimating the impact of a recommender system (opens in new tab) to predicting likely outcomes given a life event (opens in new tab). In each of these studies, we found ourselves repeating the common steps of finding the right identification strategy, devising the most suitable estimator, and conducting robustness checks, all from scratch. While we were impressed—sometimes intimidated—by the amount of knowledge in causal inference literature, we found that doing any empirical causal inference remained a challenging task. Ensuring we understood our assumptions and validated them appropriately was particularly daunting. More generally, we see that a “roll your own” approach to causal inference has resulted in studies with varying (sometimes minimal) approaches to testing of key assumptions.
Spotlight: blog post

GraphRAG auto-tuning provides rapid adaptation to new domains
GraphRAG uses LLM-generated knowledge graphs to substantially improve complex Q&A over retrieval-augmented generation (RAG). Discover automatic tuning of GraphRAG for new datasets, making it more accurate and relevant.
We therefore asked ourselves, what if there existed a software library that provides a simple interface to common causal inference methods that codified best practices for reasoning about and validating key assumptions? Unfortunately, the challenge is that causal inference depends on estimation of unobserved quantities—also known as the “fundamental problem” of causal inference. Unlike in supervised learning, such counterfactual quantities imply that we cannot have a purely objective evaluation through a held-out test set, thus precluding a plug-in approach to causal inference. For instance, for any intervention—such as a new algorithm or a medical procedure—one can either observe what happens when people are given the intervention, or when they are not. But never both. Therefore, causal analysis hinges critically on assumptions about the data-generating process.
To succeed, it became clear to us that the assumptions need to be first-class citizens in a causal inference library. We designed DoWhy using two guiding principles—making causal assumptions explicit and testing robustness of the estimates to violations of those assumptions. First, DoWhy makes a distinction between identification and estimation. Identification of a causal effect involves making assumptions about the data-generating process and going from the counterfactual expressions to specifying a target estimand, while estimation is a purely statistical problem of estimating the target estimand from data. Thus, identification is where the library spends most of its time, just like we commonly do in our projects. To represent assumptions formally, DoWhy uses the Bayesian graphical model framework where users can specify what they know, and more importantly, what they don’t know, about the data-generating process. For estimation, we provide methods based on the potential-outcomes framework such as matching, stratification and instrumental variables. A happy side-effect of using DoWhy is that you will realize the equivalence and interoperability of the seemingly disjoint graphical model and potential outcome frameworks.
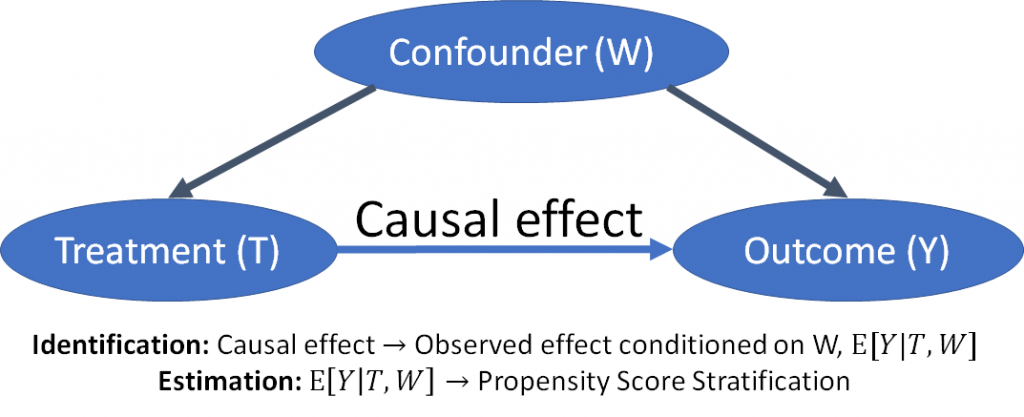
Figure 1 – DoWhy. Separating identification and estimation of causal effect.
Second, once assumptions are made, DoWhy provides robustness tests and sensitivity checks to test reliability of an obtained estimate. You can test how the estimate changes as underlying assumptions are varied, for example, by introducing a new confounder or by replacing the intervention with a placebo. Wherever possible, the library also automatically checks validity of obtained estimate based on assumptions in the graphical model. Still, we also understand that automated testing cannot be perfect. DoWhy therefore stresses interpretability of its output; at any point in the analysis, you can inspect the untested assumptions, identified estimands (if any) and the estimate (if any).
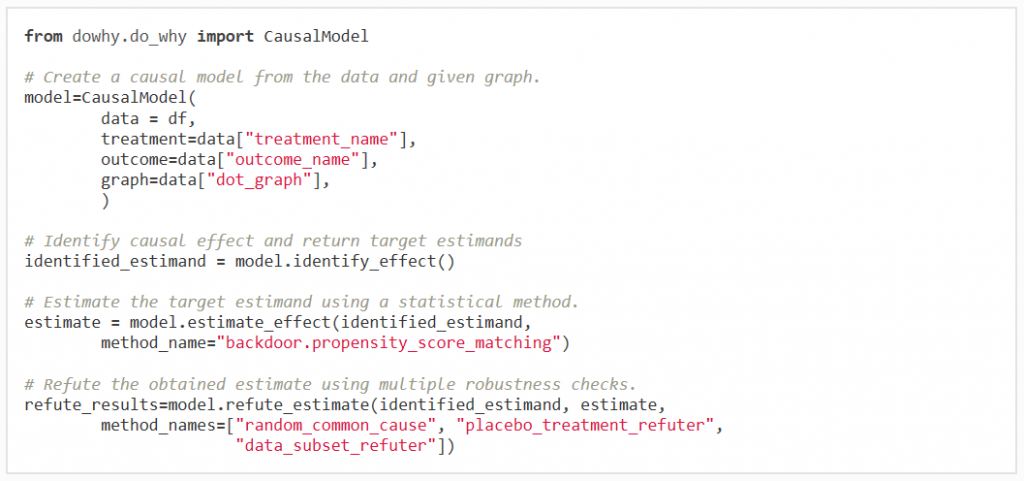
Figure 2 – Causal inference in four lines. A sample run of DoWhy.
In the future, we look forward to adding more features to the library, including support for more estimation and sensitivity methods and interoperability with available estimation software. We welcome your feedback and contributions as we develop the library. You can check out the DoWhy Python library on Github (opens in new tab). We include a couple of examples to get you started through Jupyter notebooks here (opens in new tab). If you are interested in learning more about causal inference, do check our tutorial on causal inference and counterfactual reasoning (opens in new tab), presented at KDD 2018 (opens in new tab) on Sunday, August 19th.



