
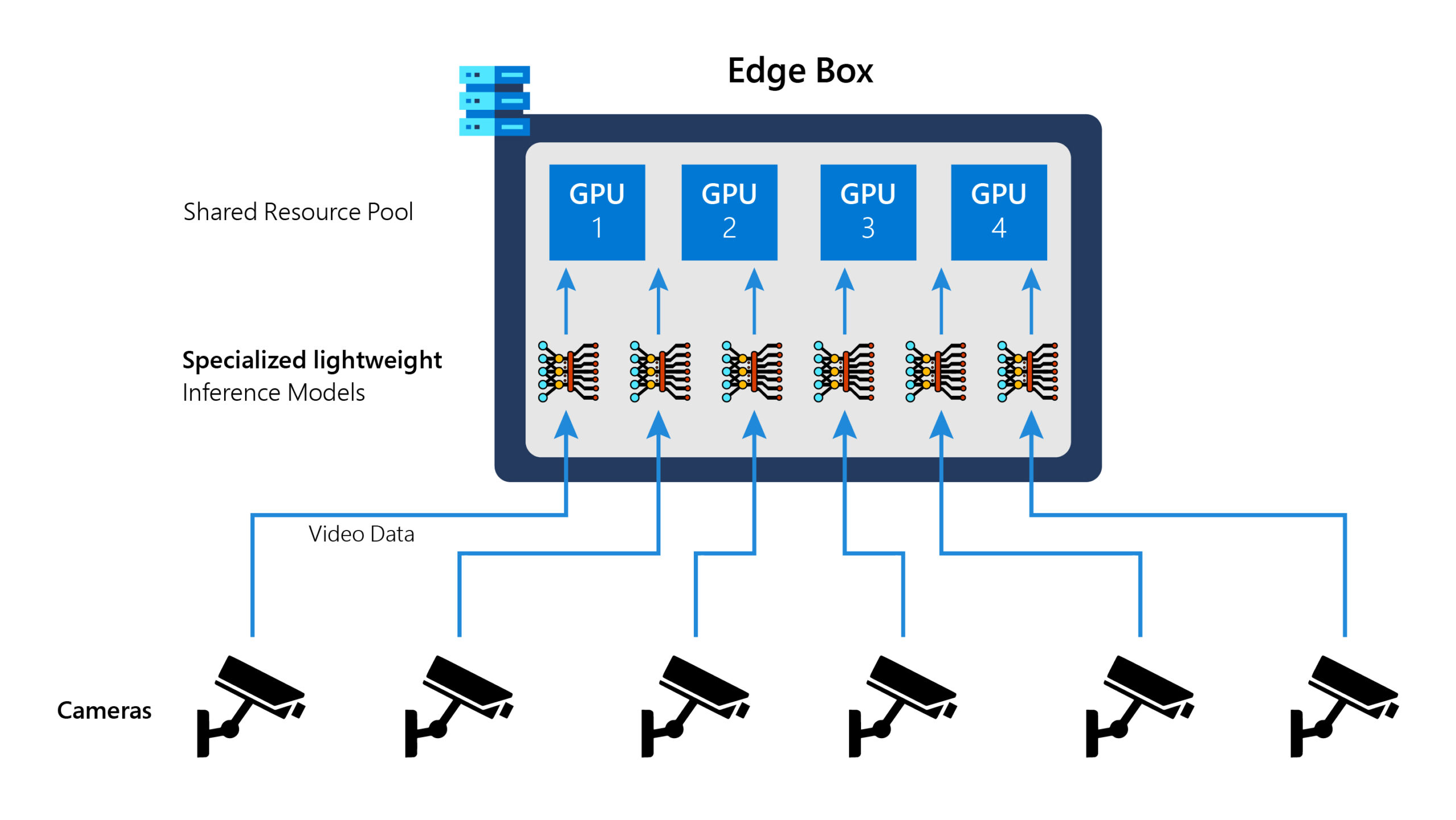
Edge computing has come of age, with deployments enabling many applications that process data from IoT sensors and cameras. In 2017, we identified the symbiotic relationship between edge computing and video analytics in an article (opens in new tab), noting that live video analytics is the “killer app” for edge computing. Edge devices come in various shapes and sizes but are inherently resource-constrained relative to the cloud.
These resource constraints necessitate lightweight machine learning (ML) models at the edge. Using techniques for model specialization and compression, the community has obtained edge models whose compute and memory footprints are substantially lower (by 96x for object detector models). Such models are super amenable to deploy at the edge.
Smooth going so far, but the villain in the story is data drift! This is the phenomenon where the live data in the field diverges significantly from the initial training data. We achieved the phenomenally low compute footprints for edge models only because we specialized the models to be specific to the camera streams. But in the bargain, they lost their ability to generalize much beyond what they have seen during training. This lack of generality comes back to bite us when data drifts and accuracy of the models drop – by as much as 22% – when they are deployed in the field.

GigaPath: Whole-Slide Foundation Model for Digital Pathology
Digital pathology helps decode tumor microenvironments for precision immunotherapy. In joint work with Providence and UW, we’re sharing Prov-GigaPath, the first whole-slide pathology foundation model, for advancing clinical research.
Ekya is a solution, developed with collaborators at University of California, Berkeley and University of Chicago, that addresses the problem of data drift on the edge compute box. Instead of sending video data to the cloud for periodic retraining of models, which is costly in its bandwidth usage and can raise privacy questions, Ekya enables both retraining and inference to co-exist on the edge box. For more details, take a look at our paper: Ekya: Continuous Learning of Video Analytics Models on Edge Compute Servers (opens in new tab), which has been published at NSDI 2022 (opens in new tab). We are excited to release the code for Ekya (opens in new tab) as well.
Not only can you use the code to reproduce all experiments in our paper, we also hope that the code can help you easily build a continuous learning system for your edge deployment. Oh, and one more thing—we are also pointing to the raw video datasets (opens in new tab) released by the City of Bellevue. This includes 101 hours of video from five traffic intersections, all of which have also been labeled with our golden YOLOv3 model (opens in new tab). We hope that the videos from the City of Bellevue as well as the other datasets included in the repository will aid in the building of new edge models as well as improving our pre-trained specialized models to significantly advance the state of the art.
Please reach out to Ganesh Ananthanarayanan (opens in new tab) with any questions.
Explore More
-
Abstract
Bellevue, Microsoft, UW team up to prevent traffic deaths
Leading Pedestrian Intervals – Yay or Nay? A Before-After Evaluation using Traffic Conflict-Based Peak Over Threshold Approach
-
Video
Video Analytics for Smart Cities
Microsoft Research has an on-going pilot in Bellevue, Washington for active traffic monitoring of traffic intersections live 24X7. This project is focused on is video streams from cameras at traffic intersections. Traffic-related accidents are among the top 10 reasons […]


