
By the Semantic Machines research team
“Easier said than done.” These four words reflect the promise of conversational AI. It takes just seconds to ask When are Megan and I both free? but much longer to find out manually from a calendar. Indeed, almost everything we do with technology can feel like a long path to a short goal. At Microsoft Semantic Machines, we’re working to bridge this gap—to build conversational AI experiences where you can focus on saying what you want and the system will worry about how to get it done. You should be able to speak as you speak to a friend: naturally, contextually, and collaboratively.
A truly powerful conversational AI needs to do more than deeply understand language. To be contextual, flexible, and robust, the AI must also deeply understand actions—most goals involve multiple steps and multiple sources of information. Representing goals, actions, and dialogue states is one of the central challenges in conversational AI systems. Our new paper in Transactions of the Association for Computational Linguistics (TACL), titled “Task-Oriented Dialogue as Dataflow Synthesis, (opens in new tab)” describes a new representation and modeling framework that interprets dialogues as dataflow graphs, enabling conversations about complex tasks that span multiple domains. We’re also releasing a dataset of over 40,000 dialogues annotated with dataflow graphs and a public leaderboard (opens in new tab), to help the AI community work on challenging and realistic problems in multi-turn, task-oriented dialogue.
- PUBLICATION Task-Oriented Dialogue as Dataflow Synthesis
Our new dataset illustrates the incredible diversity of user requests:
- Diverse goals. A user might want to Book a meeting with Megan. They might also want to Book a meeting with Megan on Tuesday, or even Book a meeting with Megan the first morning she’s free after Labor Day.
- Diverse language. A request for information might show up as What’s tomorrow’s weather? This same request might also appear as What’ll it be like out tomorrow, or as Do I need a jacket for the hike?
- Diverse contexts. The sentence How about three? means something totally different depending on what the agent just said. Following Megan is busy at 2:00, do you have other suggestions?, it’s a proposal to move a meeting. Following The forecast for noon is cloudy, it’s a query about the weather. Following Rivoli has a table for two available, it’s a request to increase the size of a dinner reservation.
Traditional «slotfilling» dialogue systems ignore much of this diversity. They support only a stock set of goals, and they have no representation of context beyond a list of arguments missing from the current goal. At the other extreme, recent «end-to-end» neural dialogue systems are free in principle to learn arbitrary context-dependent responses, but it’s not enough to be flexible in the words used because dialogue also requires flexibility in the actions performed. Deployed systems also have requirements of controllability and truthfulness that are challenging in unstructured systems.
on-demand event

Microsoft Research Forum Episode 4
Learn about the latest multimodal AI models, advanced benchmarks for AI evaluation and model self-improvement, and an entirely new kind of computer for AI inference and hard optimization.
Our third way uses deep learning to produce and consume powerful «dataflow» representations that go beyond slot-filling, providing both flexible actions and controllable semantics. Dataflow aims to support the natural, flexible, open-ended dialogues humans have in everyday conversation. Our approach is based on five key ideas:
1. User requests are programs.
Established approaches to dialogue are great at interpreting requests for fixed, pre-defined tasks like turn on the lights or set a timer called pasta for 5 minutes. In these approaches, a dialogue system designer defines a fixed set of intents, each with a fixed set of arguments. The system labels each user request with the intent it expresses and the arguments to that intent:
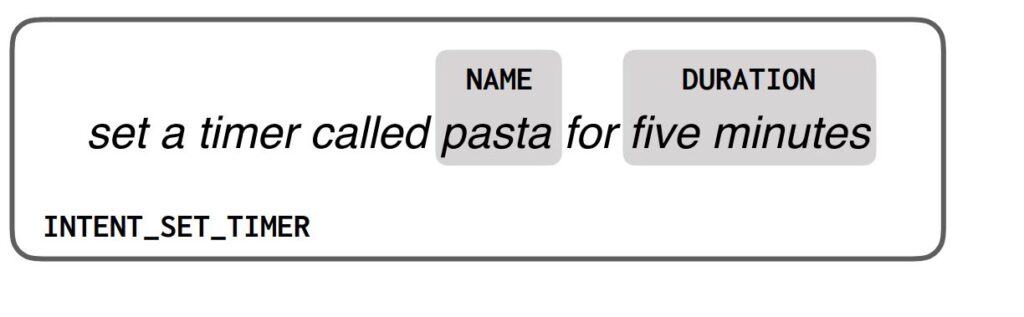
But what about more complicated requests, like What’s the temperature going to be like when I get coffee with Megan? Answering this question requires a dialogue agent to do a series of different things: figure out who Megan is, look up the event with Megan in a calendar application, figure out its start time, and use the time to query a weather service. Rather than requiring system builders to create a specialized weather_during_event_with_person intent, we translate the natural-language request into a program that ties all of these calls together. We represent this program as a dataflow graph that explicitly defines data dependencies (edges) between the steps (nodes) in the dialogue agent’s plan:
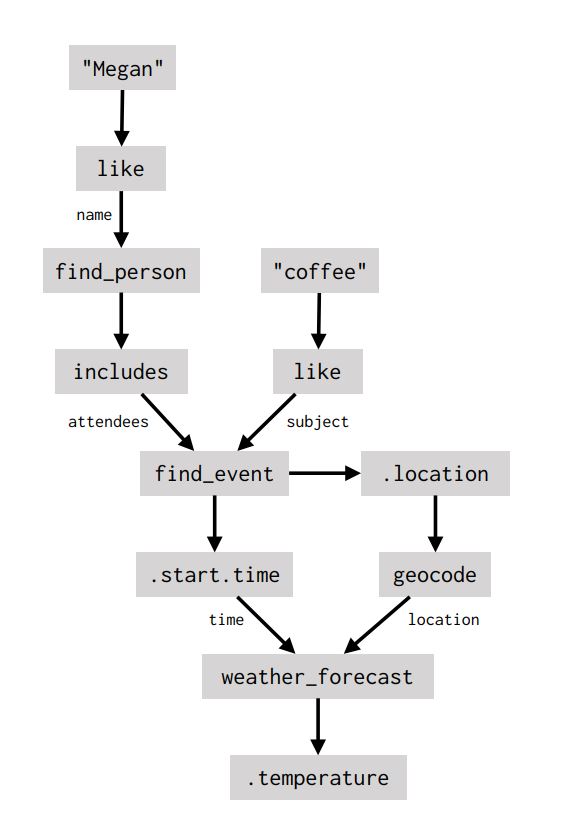
Once this program has been predicted by a neural net, the dialogue agent executes it, replies to the user based on the result, and stores the result in the dataflow graph.
2. Task-oriented dialogue is interactive programming.
One of the nice things about using dataflow as a representation of user intents is that it very naturally generalizes to interactions that unfold over multiple rounds of back-and-forth communication. If the user starts by asking When is my next meeting with Megan?, then the dialogue agent initially predicts a small graph fragment:
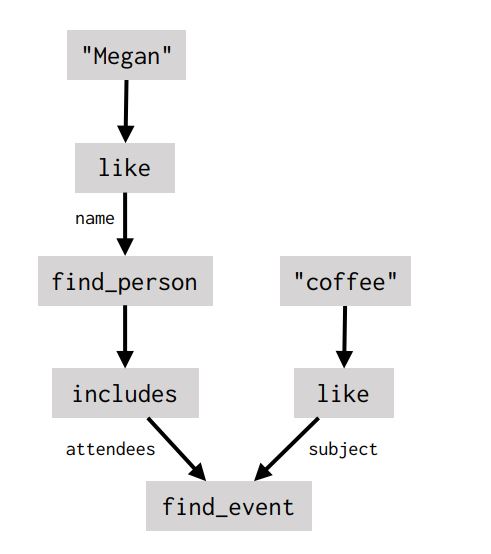
If the user follows up on the next turn with What’s the weather going to be like then?, most of the work needed to answer the new question has already been done. The dialogue agent refers back to the program fragment from the previous turn, feeds its output into a new API call, and then describes that result:
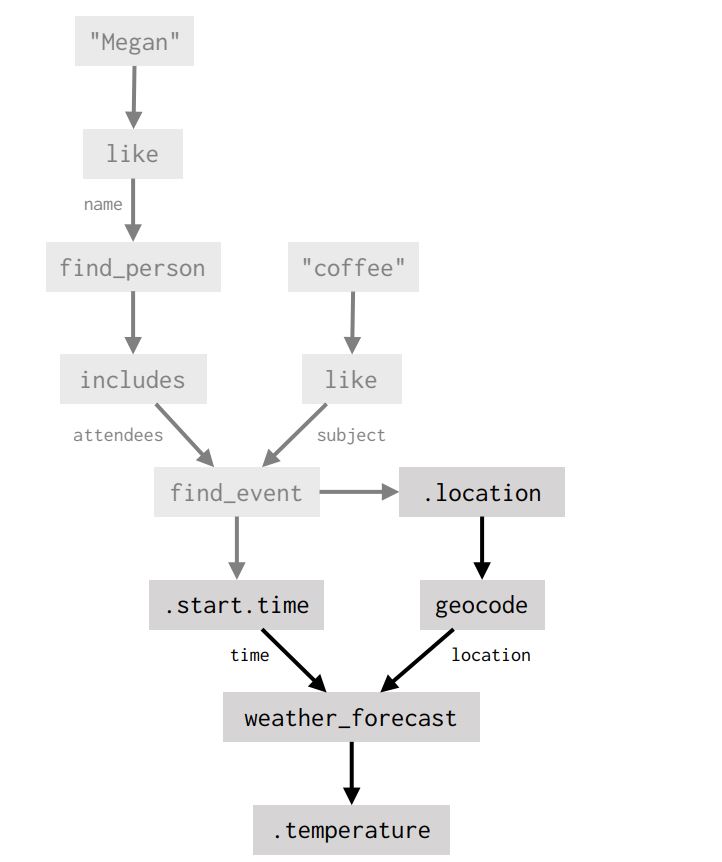
The result of this process is exactly the same program we generated for the single complex question earlier! This kind of reuse is a central feature of our framework—complex actions are built by composing simpler ones rather than defining a large set of top-level behaviors. This composition can happen all at once or gradually over multiple turns that successively extend the dataflow graph.
3. Meanings depend on context.
The extended graph serves as the dialogue state. It records all the computations the agent has performed so far to understand, serve, and reply to the user. Subsequent utterances are interpreted in this context (via deep learning), and they can refer back to these earlier computations and their results. As we show in our paper, explicit mechanisms for referencing and reusing earlier computations improve the data efficiency and accuracy of machine learning for dialogue agents. They also make it easier for engineers to reason about and control the behavior of dialogue agents.
In the previous example, the user referred back to an earlier node in the dataflow graph using the word then. Other referring expressions, like that, her, or the second meeting you mentioned can also indicate a request to re-use values or entities mentioned earlier in the dialogue.
Such references can also happen implicitly. Imagine asking your device What’s the weather going to be like? Normally you mean the weather in the near future. But if you asked the same question after a future event has been mentioned, you’d likely be inquiring about the weather during that event and at the event’s location. Ultimately, these two cases require two different computations. Below, the computation on the left would be used for the near-future interpretation presented above. The computation on the right would be used for the latter event-specific interpretation:
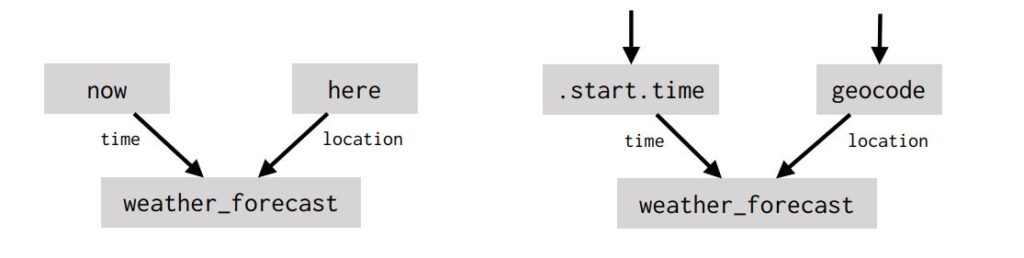
Figuring out how to distinguish these uses (not to mention other interpretations of the question) is a challenging machine learning problem. But intuitively, What’s the weather going to be like? means the same thing in both cases—the user wants to know the weather at the time and place that are most relevant to the conversational context.
In our approach, this kind of reasoning is made explicit: when interpreting user input in context, our dialogue agent explicitly predicts programs that refer to pieces of existing computation, including pieces like here and now that are implicitly available from the beginning of the conversation. For the two examples above, this looks like:
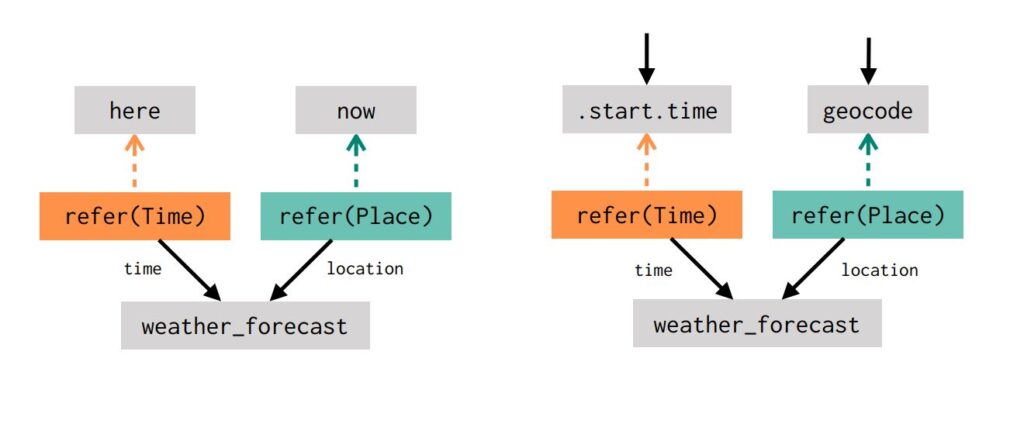
In other words, the dialogue agent interprets What’s the weather going to be like? the same way in both dialogues. It predicts the same dataflow graph fragment, with calls to refer(Time) and refer(Place), but the interpretation of this fragment changes based on the preceding context.
A question that interacts even more strongly with context is What about during the company retreat? Here, the user isn’t just referring to an existing entity but is instead asking the dialogue agent to compute a new answer to an earlier question, with some of the details changed. We call this kind of transformation a revision. Like references, revisions provide a powerful mechanism for performing complex graph transformations in response to simple requests. Here’s a schematic representation of the revision that the agent predicts when a user asks What’s the weather going to be like during my coffee with Megan? and then What about during the company retreat?
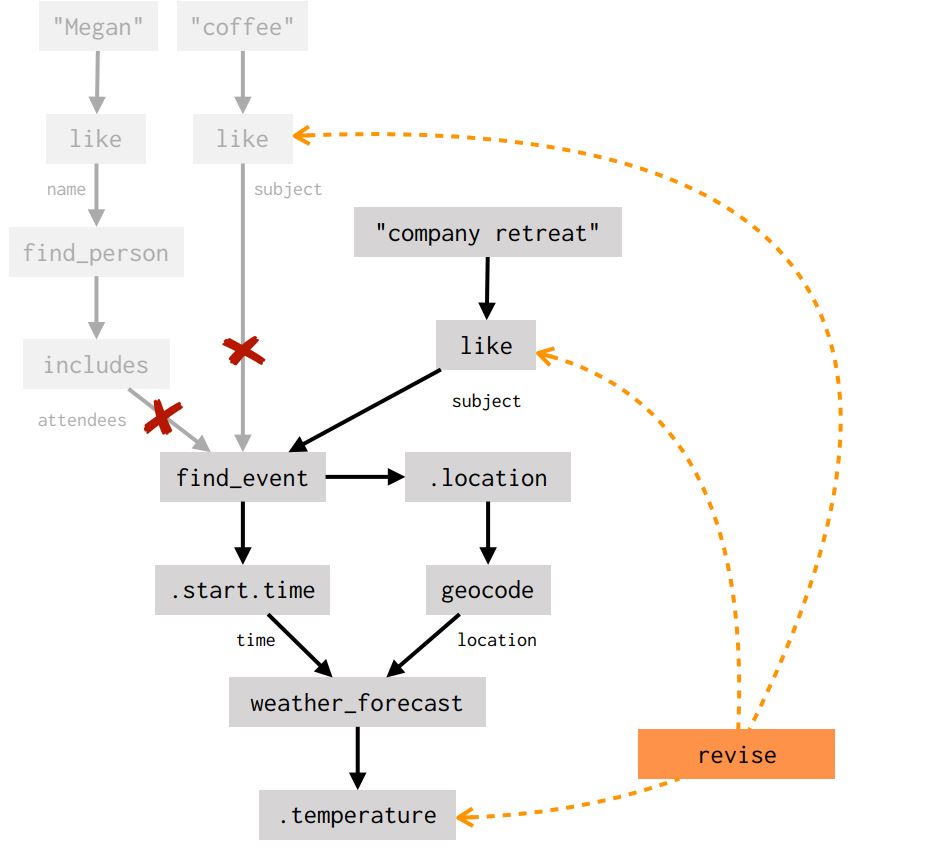
Here, the constraints on the first event search (for an event called coffee that includes Megan) are replaced with a new constraint (specifying an event called company retreat). See the paper for more details.
4. Things will go wrong.
In any complicated dialogue, there are many ways for unexpected events to occur. A request to book a meeting with Megan might fail because no one in the user’s contact list is named Megan; because multiple people are named Megan; because there’s no free time for a meeting; or even because the internet is out and the dialogue agent can’t contact the server. Each of these circumstances requires a different response, and existing dialogue systems often use complicated, hard-coded logic to recover from errors.
We handle all these failures by throwing an exception from some node of the dataflow graph. Our dialogue agent reacts to this unfortunate “result” by generating an appropriate warning or question for the user. The user can respond freely, perhaps by correcting the problem; for example, I meant Megan Bowen would be interpreted in this context as a revision that refines the original request. This approach lets the system and the user deal with errors as they show up—flexibly, contextually, modularly, and collaboratively.
5. Language generation depends on dialogue context.
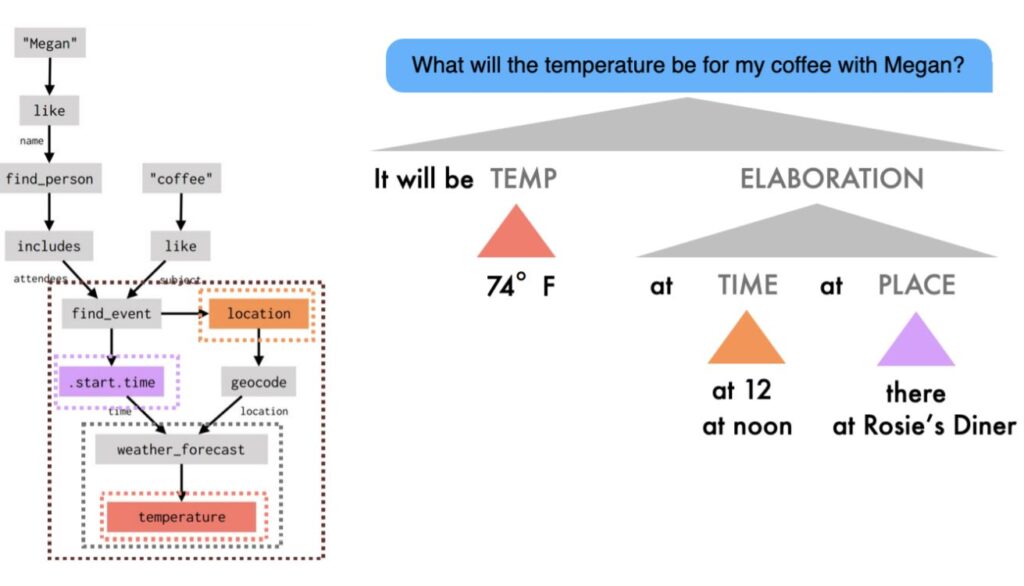
To be an effective teammate, a conversational AI system needs to be able to generate language, not just interpret it. Most existing approaches to dialogue either hard-code generation rules (leading to robotic-sounding outputs that don’t change in response to different contexts) or unstructured neural language models (which sometimes fail to tell the truth!). In our approach, language generation is modeled as a neurally guided process of compositional program transformation, in which the agent takes its turn to extend the dataflow graph. The agent can talk about anything that’s shown up in the graph, not just the last result it computed. It can even add new computations and results to the graph, which the user is free to refer to in subsequent turns:
Resources for researchers: code, data, and a new competition
We believe that this approach is the first step toward a new generation of automated dialogue agents that can interact with people the way people interact with each other. However, solving the problem will require the whole community. To facilitate open research on dataflow-based dialogue agents, we’re releasing the largest and most complex task-oriented dialogue dataset to date: a new dataset called SMCalFlow, featuring 41,517 conversations annotated with dataflow programs. This dataset resulted from open-ended conversations among humans about calendars, weather, people, and places. In contrast to existing dialogue datasets, our dialogue collection was not based on pre-specified scripts, and participants were not restricted in terms of what they could ask for and how they should accomplish their tasks. As a result, SMCalFlow is qualitatively different from existing dialogue datasets, featuring explicit discussion about agent capabilities, multi-turn error recovery, and complex goals.
The dataset, code, and leaderboard are available at our GitHub page (opens in new tab). We look forward to seeing what the natural language processing community does with this new resource.
At Semantic Machines, we’re continuing to push the boundaries of conversational AI. Come work with us!



