In February, we announced DeepSpeed, an open-source deep learning training optimization library, and ZeRO (Zero Redundancy Optimizer), a novel memory optimization technology in the library, which vastly advances large model training by improving scale, speed, cost, and usability. DeepSpeed has enabled researchers to create Turing Natural Language Generation (Turing-NLG), the largest language model with 17 billion parameters and state-of-the-art accuracy at the time of its release. In May, we released ZeRO-2—supporting model training of 200 billion parameters up to 10x faster compared to state of the art—along with a list of compute, I/O, and convergence optimizations powering the fastest BERT training. From there, we have been continuing to innovate at a fast rate, pushing the boundaries of speed and scale for deep learning training.
Today, we are happy to share our new advancements that not only push deep learning training to the extreme, but also democratize it for more people—from data scientists training on massive supercomputers to those training on low-end clusters or even on a single GPU. More specifically, DeepSpeed adds four new system technologies that further the AI at Scale initiative to innovate across Microsoft’s AI products and platforms. These offer extreme compute, memory, and communication efficiency, and they power model training with billions to trillions of parameters. The technologies also allow for extremely long input sequences and power on hardware systems with a single GPU, high-end clusters with thousands of GPUs, or low-end clusters with very slow ethernet networks.
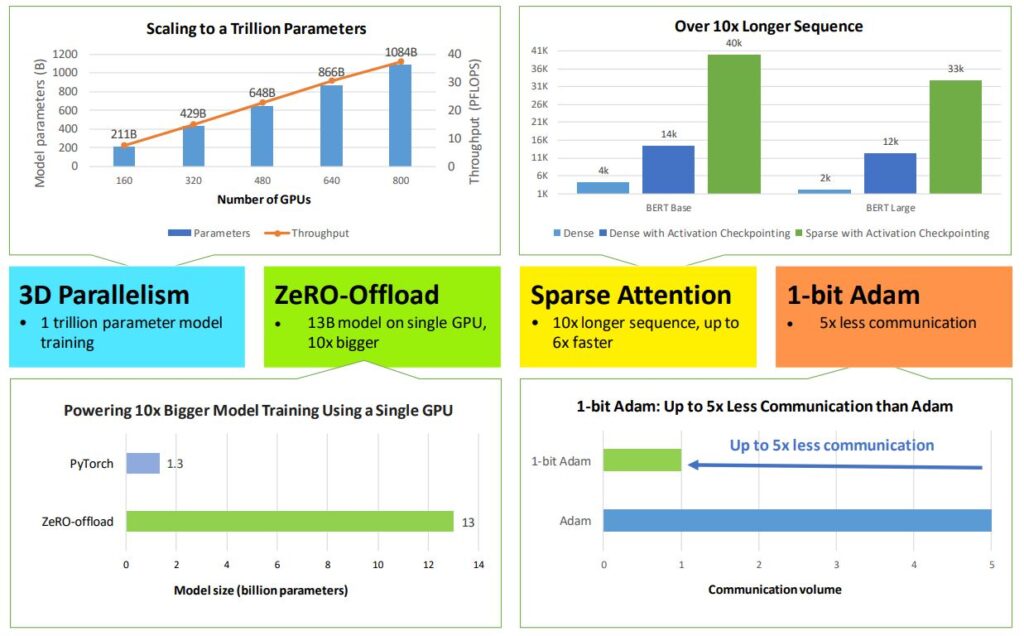
- Trillion parameter model training with 3D parallelism: DeepSpeed enables a flexible combination of three parallelism approaches—ZeRO-powered data parallelism, pipeline parallelism, and tensor-slicing model parallelism. 3D parallelism adapts to the varying needs of workload requirements to power extremely large models with over a trillion parameters while achieving near-perfect memory-scaling and throughput-scaling efficiency. In addition, its improved communication efficiency allows users to train multi-billion-parameter models 2–7x faster on regular clusters with limited network bandwidth.
- 10x bigger model training on a single GPU with ZeRO-Offload: We extend ZeRO-2 to leverage both CPU and GPU memory for training large models. Using a machine with a single NVIDIA V100 GPU, our users can run models of up to 13 billion parameters without running out of memory, 10x bigger than the existing approaches, while obtaining competitive throughput. This feature democratizes multi-billion-parameter model training and opens the window for many deep learning practitioners to explore bigger and better models. Read the paper: https://www.microsoft.com/en-us/research/publication/zero-offload-democratizing-billion-scale-model-training/
- Powering 10x longer sequences and 6x faster execution through DeepSpeed Sparse Attention: DeepSpeed offers sparse attention kernels—an instrumental technology to support long sequences of model inputs, whether for text, image, or sound. Compared with the classic dense Transformers, it powers an order-of-magnitude longer input sequence and obtains up to 6x faster execution with comparable accuracy. It also outperforms state-of-the-art sparse implementations with 1.5–3x faster execution. Furthermore, our sparse kernels support efficient execution of flexible sparse format and empower users to innovate on their custom sparse structures.
- 1-bit Adam with up to 5x communication volume reduction: Adam is an effective and (probably the most well-utilized) optimizer for training many large-scale deep learning models. However, Adam is generally not compatible with communication-efficient optimization algorithms. Therefore, the communication cost could become a bottleneck while scaling across distributed devices. We introduce a new algorithm, 1-bit Adam with efficient implementation, which reduces communication volume by up to 5x while achieving similar convergence efficiency to Adam. We observe up to 3.5x faster distributed training in communication-constrained scenarios, allowing for scaling to different types of GPU clusters and networks. Read the paper: https://www.microsoft.com/en-us/research/publication/1-bit-adam-communication-efficient-large-scale-training-with-adams-convergence-speed/
This blog post explores these four lines of technology in greater depth. We have been making all of these exciting new optimizations available in open-source library, DeepSpeed (opens in new tab).

About Microsoft Research
Advancing science and technology to benefit humanity
3D parallelism: Scaling to trillion-parameter models
With the rapid growth of compute available on modern GPU clusters, training a powerful trillion-parameter model with incredible capabilities is no longer a far-fetched dream but rather a near-future reality. DeepSpeed has combined three powerful technologies to enable training trillion-scale models and to scale to thousands of GPUs: data parallel training, model parallel training, and pipeline parallel training. This symbiosis scales deep learning training far beyond what each of the strategies can offer in isolation. 3D parallelism simultaneously addresses the two fundamental challenges toward training trillion-parameter models: memory efficiency and compute efficiency. As a result, DeepSpeed can scale to fit the most massive models in memory without sacrificing speed.
-
Memory Efficiency: The memory requirements to train a trillion-parameter model are far beyond what is available in a single GPU device. Training using the Adam optimizer in mixed precision requires approximately 16 terabytes (TB) of memory just to store the model states (parameters, gradients, and optimizer states). For comparison, the state-of-the-art NVIDIA A100 GPUs have just 40 gigabytes (GB) of memory. It would require the collective memory of 400 such GPUs just to store the model states.
Activations consume additional memory that increases with the batch size. A trillion-parameter model trained with only unit batch size produces over 1 TB of activation memory. Activation checkpointing reduces this memory to approximately 20 GB by trading for additional compute, but the memory requirements remain prohibitively large for training.
The model states and activations must be efficiently partitioned across the available multiple GPU devices to enable such a model to even begin training without running out of memory.
Compute Efficiency: Training a trillion-parameter model end-to-end requires approximately 5,000 zettaflops (that’s 5 with 24 zeros after it; based on the laws of scaling (opens in new tab) work from OpenAI). It would take 4,000 NVIDIA A100 GPUS running at 50% compute efficiency about 100 days to train such a model.
While large super-computing GPU clusters can have well over 4,000 GPUs, achieving high compute efficiency at this scale is challenging due to the batch size constraints. Compute efficiency increases as the computation time increases over the communication time. This ratio is proportional to the batch size. However, the batch size that a model can be trained with has an upper bound—beyond that the convergence efficiency deteriorates rapidly.
One of the largest models in the world, GPT-3 (opens in new tab), was trained using a batch size of about 1,500. With 4,000 GPUs, even a liberal batch size of 4,000 would only allow for a batch size of 1 per GPU and limit scalability.
-
Data parallelism is a ubiquitous technique in deep learning in which each input batch of training data is split among the data parallel workers. Gradients must be communicated and aggregated after backward propagation to ensure that consistent steps are taken by the optimizer. Data parallelism has several distinct advantages, including compute efficiency and minimal implementation effort. However, data parallelism relies on scaling the batch size with the number of data parallel workers, which cannot be done indefinitely without affecting convergence.
- Memory efficiency: Data parallelism replicates the model and optimizer across all workers, and therefore is not memory efficient. DeepSpeed developed ZeRO, a collection of optimizations that improve the memory efficiency of data parallelism. This work relies on ZeRO stage 1, which partitions the optimizer states among data parallel workers to reduce redundancy.
- Compute efficiency: The amount of computation performed by each worker is constant as we increase the degree of parallelism. Data parallelism can achieve near-perfect scaling at small scales. However, the communication cost of aggregating gradients among data parallel workers scales with the model size and limits compute efficiency on large models or systems with low communication bandwidth. Gradient accumulation is a common strategy for amortizing this communication cost by further increasing the batch size and performing multiple forward and backward propagations on micro-batches while locally accumulating gradients before aggregating and taking an optimizer step.
Model Parallelism is a broad class of techniques that partitions the individual layers of the model across workers. By its nature, the computations and communications of model parallelism are specific to a model architecture and therefore can have large initial implementation effort. DeepSpeed leverages NVIDIA’s Megatron-LM (opens in new tab) in this work for massive model-parallel Transformer-based language models. Model parallelism reduces the memory proportional to the number of workers. Model parallelism is the most memory efficient among the three types of parallelism at the cost of the lowest compute efficiency.
- Memory efficiency: Model parallelism reduces the memory footprint proportional to the number of workers. Crucially, it is the only approach that reduces the activation memory for individual network layers. DeepSpeed further improves memory efficiency by partitioning the activation memory among model-parallel workers.
- Compute efficiency: Model parallelism has poor computational efficiency due to additional communication of activations in each forward and backward propagation. Model parallelism requires high communication bandwidth to be efficient and does not scale well beyond a single node where the communication bandwidth is limited. Furthermore, each model-parallel worker decreases the amount of computation performed between each communication stage, impacting compute efficiency. Model parallelism is often used in conjunction with data parallelism to trade between memory and compute efficiency.
Pipeline parallelism training engine is included in this release of DeepSpeed! Pipeline parallelism divides the layers of the model into stages that can be processed in parallel. As one stage completes the forward pass for a micro-batch, the activation memory is communicated to the next stage in the pipeline. Similarly, as the next stage completes its backward propagation, gradients are communicated backwards through the pipeline. Multiple micro-batches must be kept in flight to ensure pipeline stages compute in parallel. Several approaches, such as PipeDream, have been developed to trade off memory and compute efficiency as well as convergence behavior. The DeepSpeed approach extracts parallelism through gradient accumulation to maintain the same convergence behavior as traditional data- and model-parallel training with the same total batch size.
- Memory efficiency: Pipeline parallelism reduces memory proportional to the number of pipeline stages, allowing model size to scale linearly with the number of workers. However, pipeline parallelism does not reduce the memory footprint for the activations of each layer. Additionally, each worker must store the activations for all micro-batches in flight. In effect, the activation memory on the first stage of the pipeline is approximately the same as the total activation memory for a single micro-batch. A trillion-parameter model would need approximately 19 GB of memory for the activations of a micro-batch, consuming almost half the available memory of the new NVIDIA A100 GPU.
- Compute efficiency: Pipeline parallelism has the lowest communication volume since it only communicates data proportional to the activation size of the layers between stage boundaries. However, it cannot scale indefinitely. Like model parallelism, increasing the pipeline size decreases the computation per pipeline stage, which also decreases the compute-to-communication ratio. Pipeline parallelism also requires each of its stages to be perfectly load balanced to achieve good efficiency.
Furthermore, pipeline parallelism incurs a bubble overhead from filling and emptying the pipeline at the beginning and end of each training batch. Training with gradient accumulation steps (and thus batch size) that is 4x or 8x the number of pipeline stages achieves 81% and 90% scaling efficiency from one pipeline stage, respectively.
- Memory efficiency: Data parallelism replicates the model and optimizer across all workers, and therefore is not memory efficient. DeepSpeed developed ZeRO, a collection of optimizations that improve the memory efficiency of data parallelism. This work relies on ZeRO stage 1, which partitions the optimizer states among data parallel workers to reduce redundancy.
Achieving both memory and compute efficiency with 3D parallelism
Data, model, and pipeline parallelism each perform a specific role in improving memory and compute efficiency. Figure 1 illustrates our 3D strategy.
Memory Efficiency: The layers of the model are divided into pipeline stages, and the layers of each stage are further divided via model parallelism. This 2D combination simultaneously reduces the memory consumed by the model, optimizer, and activations. However, we cannot partition the model indefinitely without succumbing to communication overheads which limits compute efficiency.
Compute Efficiency: To allow the number of workers to scale beyond model and pipeline parallelism without sacrificing compute efficiency, we use ZeRO-powered data parallelism (ZeRO-DP). ZeRO-DP not only improves memory efficiency further via optimizer state partition, but also allows scaling to arbitrarily large number of GPUs with minimal communication overhead by exploiting topology aware mapping.
Topology aware 3D mapping (Figure 2): Each dimension in 3D parallelism is carefully mapped onto the workers to achieve maximum compute efficiency by exploiting two key architectural properties.
- Optimizing for intra- and inter-node communication bandwidth: Model parallelism has the largest communication overhead of the three strategies, and so we prioritize placing model parallel groups within a node to utilize the larger intra-node bandwidth. Here we apply NVIDIA Megatron-LM for tensor-slicing style of model parallelism. Data parallel groups are placed within a node when model parallelism does not span all the workers in a node. Otherwise, they are placed across nodes. Pipeline parallelism has the lowest communication volume, and so we can schedule pipeline stages across nodes without being limited by the communication bandwidth.
- Bandwidth amplification via parallelism in communication: The size of the gradients communicated by each data parallel group decreases linearly via both pipeline and model parallelism, and thus the total communication volume is decreased from pure data parallelism. Furthermore, each data parallel group performs its communication independently and in parallel among a subset of localized workers. As a result, the effective bandwidth for data parallel communication is amplified by a combination of reduced communication volume and increased locality and parallelism.


-
A trillion-parameter model could be scaled across 4,096 NVIDIA A100 GPUs using 8-way model parallelism, 64-way pipeline parallelism, and 8-way data parallelism.
By combining model parallelism and pipeline parallelism, 3D parallelism achieves excellent memory efficiency and compute efficiency across multiple nodes. Model parallelism brings memory efficiency for the activations and model states within a node, while pipeline parallelism allows for memory efficiency of model states across nodes without sacrificing compute efficiency compared to using model parallelism alone. In our trillion-parameter example with a micro-batch size of 1, our model would consume 30 GB of memory for model states and 2.5 GB for partitioned activations after activation checkpointing with the aforementioned 3D parallelism. This results in a total memory footprint of 32.5 GB. With such a configuration, NVIDIA A100 GPUs with 40 GB of memory have more than enough space to fit and train such a model.
Combining model parallelism with pipeline parallelism also allows pipeline parallelism to achieve high compute efficiency with minimal bubble overhead even at very small batch sizes. With 8-way model parallelism, using a micro-batch of 1 per model would result in an effective micro-batch of 1/8 per GPU. Therefore, pipeline parallelism can achieve a 90% compute efficiency using a gradient accumulation step of 8x the pipeline parallelism degree and with an aggregate per-GPU batch size of only 1. When combined with data parallelism, this results in an effective batch size of 4,096 on 4,096 GPUs, which can still achieve 90% pipeline efficiency.
But what compute efficiency results from data parallelism? Doesn’t data parallelism require large batch per GPU to remain efficient?
Model parallelism can reduce the effective batch size to be less than 1 per GPU. This allows pipeline parallelism to hide the pipeline bubble overhead even with small batch sizes. Note that by using pipeline parallelism across nodes, we are effectively allowing communication between data parallel nodes at each stage of the pipeline to happen independently and in parallel with the other pipeline stages. In fact, in a fully connected network topology common in high-end GPU clusters, this has a significant implication on the effective communication bandwidth available for data parallel training. Since each node at a pipeline stage can communicate in parallel with its corresponding data parallel nodes, the effective communication bandwidth is directly proportional to the number of pipeline stages. With 64 pipeline-parallel stages, the effective bandwidth is 64x the bandwidth to and from a single node. With such large effective bandwidth pipeline parallelism enables data parallelism to scale effectively, even at small batch sizes where the compute-to-communication ratio is very low.
Powering trillion-parameter model training with linear efficiency scaling
DeepSpeed can train a language model with one trillion parameters using as few as 800 NVIDIA V100 GPUs (Figure 3). We demonstrate simultaneous memory and compute efficiency by scaling the size of the model and observing linear growth, both in terms of the size of the model and the throughput of the training. In every configuration, we can train approximately 1.4 billion parameters per GPU, which is the largest model size that a single GPU can support without running out of memory, indicating perfect memory scaling. We also obtain close to perfect-linear compute efficiency scaling and a throughput of 47 teraflops per V100 GPU. This is impressive scaling and throughput for the given hardware.

-

Figure 4: System performance using 800 GPUs to train a GPT-3 scale model with 180 billion parameters using 2D and 3D parallelism. The model has 100 Transformer layers with hidden dimension 12,288 and 96 attention heads. The model is trained with batch size 2,048 and sequence length 2,048. ZeRO-1 is enabled alongside data parallelism. P, M, and D denote the pipeline, model, and data parallel dimensions, respectively. In Figure 4, we use the recent GPT-3 (opens in new tab) model architecture, with over 175 billion parameters, as a benchmark for 3D parallelism:
- We first evaluate the 2D configurations (C1-C3). Configurations C1 and C2 use only pipeline and model parallelism—they can train the model but achieve low throughput due to over-decomposing the problem and having low GPU utilization. C3 attempts to use only pipeline and data parallelism but is unable to fit the problem in memory without reducing the size of activations via Megatron’s model parallelism.
- The 3D configurations (C4-C10) are arranged by increasing degree of pipeline parallelism; the best performance is achieved by the middle configurations that balance the parallelism in order to be memory-, computation-, and communication-efficient.
- The best 3D approaches achieve 49 teraflops per GPU, over 40% of the theoretical hardware peak.
-
We demonstrate the communication benefits of hybrid parallelism in Figure 5 while training a 1.5-billion-parameter GPT-2 model. We train on four nodes of a cluster with low inter-node bandwidth in order to emphasize the communication stages of training:
- Model parallelism is not advantageous in this case due to the low intra-node bandwidth and smaller model size.
- Pipeline parallelism communicates over an order of magnitude less volume than the data and model parallel configurations and is 7x faster at small batch sizes.
- Data parallelism uses gradient accumulation to amortize communication overhead as the batch size increases, but pipeline parallel configurations still achieve over twice the performance of data parallelism at larger batch sizes.
- The hybrid pipeline and data parallel configuration avoids the gradient communication bottleneck by restricting data parallel groups to GPUs within a node, so gradient communications benefit from the faster intra-node bandwidth.

Figure 5: Throughput as a function of batch size while training GPT-2 (1.5B parameters) with sequence length 1,024. Training uses four nodes, each with four NVIDIA V100 GPUs with 16 GB of memory. The GPUs are connected with 50 Gigabits-per-second (Gbps) intra-node bandwidth and 4 Gbps inter-node bandwidth. DP denotes data parallelism with ZeRO-1 enabled. All methods scale batch size via increasing steps of gradient accumulation. - Model parallelism is not advantageous in this case due to the low intra-node bandwidth and smaller model size.
ZeRO-Offload: 10x bigger model training using a single GPU
ZeRO-Offload pushes the boundary of the maximum model size that can be trained efficiently using minimal GPU resources, by exploiting computational and memory resources on both GPUs and their host CPUs. It allows training up to 13-billion-parameter models on a single NVIDIA V100 GPU, 10x larger than the state-of-the-art while retaining high training throughput of over 30 teraflops per GPU.
By enabling multi-billion-parameter model training on a single GPU, ZeRO-Offload democratizes large model training, making it accessible to deep learning practitioners with limited resources.
The key technology behind ZeRO-Offload is our new capability to offload optimizer states and gradients onto CPU memory, building on top of ZeRO-2. This approach allows ZeRO-Offload to minimize the compute efficiency loss from CPU offloading while also achieving the same, and sometimes even better, efficiency of the original ZeRO-2. The figure below shows the architecture of ZeRO-Offload.

-
Training multi-billion-parameter models like GPT and T5 require many GPUs to fit the model and its states in GPU memory. Large model training has been mostly carried out with model parallelism across multiple GPU devices to solve the memory limitation problem. Recently, we released ZeRO, a memory efficient optimizer that partitions model states (optimizer states, gradients, and model weights) across data parallel GPUs, allowing multi-billion-parameter models to be trained without requiring model parallelism. However, ZeRO still requires a large number of data parallel GPUs to hold the partitioned model states, limiting the access of large model training to a few with access to such resources.
ZeRO-Offload democratizes large model training by making it possible even on a single GPU. To allow training multi-billion-parameter models without using multiple GPUs, ZeRO-Offload inherits the optimizer state and gradient partitioning from ZeRO-2. Unlike ZeRO-2, instead of having each GPU keep a partition of the optimizer state and gradients, ZeRO-Offload offloads both to host CPU memory. Optimizer states are kept in CPU memory for the entire training. Gradients, on the other hand, are computed and averaged using reduce-scatter on the GPUs during the backward pass, and each data-parallel process then offloads the averaged gradients belonging to its partition to the CPU memory (g offload in Figure 7) while discarding the rest.
Once the gradients are available on the CPU, optimizer state partitions are updated in parallel by each data parallel process directly on the CPU (p update in Figure 7). After the update, parameter partitions are moved back to GPU followed by an all-gather operation on the GPU to gather all the updated parameters (g swap in Figure 7). ZeRO-Offload also exploits overlapping between communication (such as g offload and g swap) and computation (such as the backward pass and p update) using separate CUDA streams to maximize training efficiency.
-
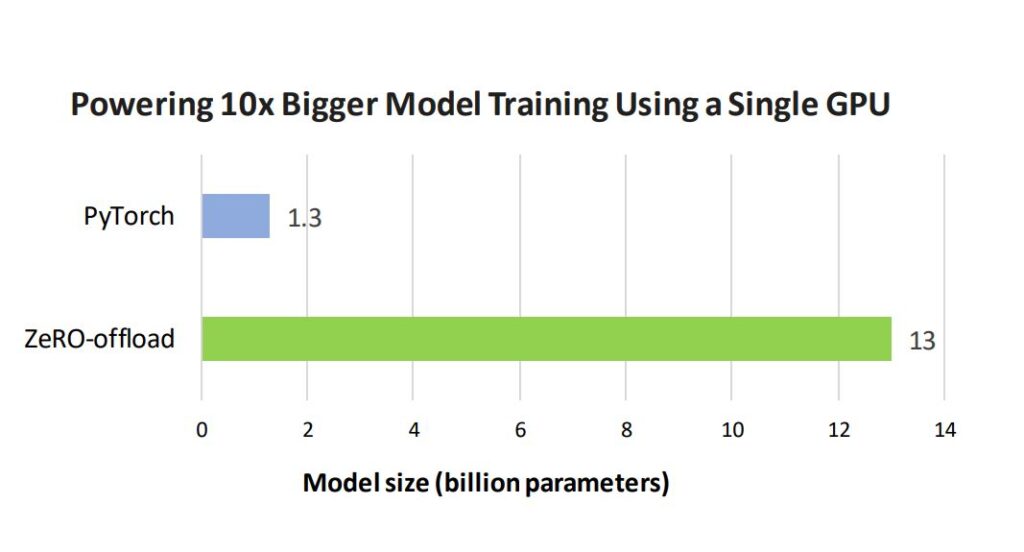
10x model scale: On a single 32 GB V100 GPU, Figure 6 shows that the biggest model that can be trained by PyTorch has 1.3 billion parameters, while ZeRO-Offload allows for training models of 13 billion parameters, which is 10 times bigger. This is because ZeRO-Offload keeps the optimizer states (which consume a large portion of GPU memory) in host memory during the entire training process while also offloading gradients to CPU as they are computed in the backward pass. As a result, the saved GPU memory can be used in hosting bigger models for training.
Efficient training throughput: Figure 8 shows that when training a 10-billion-parameter model, ZeRO-Offload provides over 30 teraflops throughput per GPU even when training with only a single GPU, and its throughput increases close to perfect linearly with the increasing number of GPUs.
ZeRO-Offload complements ZeRO-2 well, supporting efficient training of large models on a small number of GPUs. From 1 to 16 GPUs, ZeRO-Offload turns the model training from infeasible to feasible by leveraging CPU memory, reducing GPU memory required for the model. On 32 GPUs, ZeRO-Offload slightly outperforms ZeRO-2; the improvement comes from additional memory savings on GPU from ZeRO-Offload, which allows training with larger batch sizes and increases the GPU computation efficiency despite the overhead of CPU offloading. With more GPUs (such as 64 and 128), ZeRO-2 outperforms ZeRO-Offload since both can now run similar batch sizes. On one hand, though, ZeRO-2 does not have the overhead of moving data to CPU, while on the other hand, the optimizer step calculation on GPU is much faster than on CPU. In summary, ZeRO-Offload complements ZeRO-2 and extends ZeRO family of optimizations to cover the full spectrum of large model training from a single device to thousands of devices.

Figure 8: The training throughput is compared for ZeRO-Offload and ZeRO-2 using 128 GPUs to train a 10-billion parameter GPT-2 model.
DeepSpeed Sparse Attention: Powering 10x longer sequences with 6x faster execution
Attention-based deep learning models, such as Transformers, are highly effective in capturing relationships between tokens in an input sequence, even across long distances. As a result, they are used with text, image, and sound-based inputs, where the sequence length can be in thousands of tokens. However, despite the effectiveness of attention modules to capture long term dependencies, in practice their application to long sequence input is limited by compute and memory requirements of the attention computation that grow quadratically, \(O(n^2 )\), with the sequence length \(n\).
To address this limitation, DeepSpeed offers a suite of sparse attention kernels—an instrumental technology that can reduce the compute and memory requirement of attention computation by orders of magnitude via block-sparse computation. The suite not only alleviates the memory bottleneck of attention calculation, but also performs sparse computation efficiently. Its APIs allow convenient integration with any transformer-based models. Along with providing a wide spectrum of sparsity structures, it has the flexibility of handling any user-defined block-sparse structures.
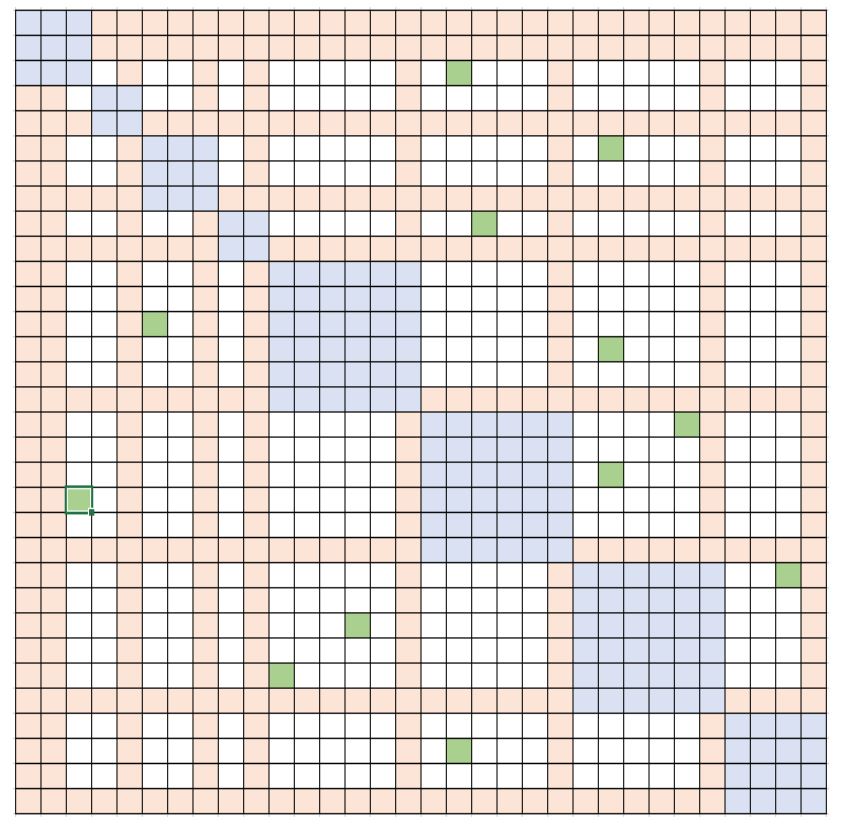
More specifically, sparse attention (SA) can be designed to compute local attention between nearby tokens, or global attention via summary tokens computed with local attention. Moreover, SA can also allow random attention or any combination of local, global, and random attention as shown in Figure 10 with blue, orange, and green blocks, respectively. As a result, SA decreases the memory footprint to \(O (wn)\), in which 1\(<w ≤ n\) is a parameter, whose value depends on the attention structure.
Efficient implementation on GPUs: While a basic implementation of sparse attention may show a benefit of memory savings, computationally it can be even worse than full computation. This is mainly due to the divergence and un-coalesced memory access that sparse data adds to the full picture. In general, developing efficient sparse kernels, particularly on GPUs, is challenging. DeepSpeed offers efficient sparse attention kernels developed in Triton (opens in new tab). These kernels are structured in block-sparse paradigm that enables aligned memory access, alleviates thread divergence, and balances workloads on processors.
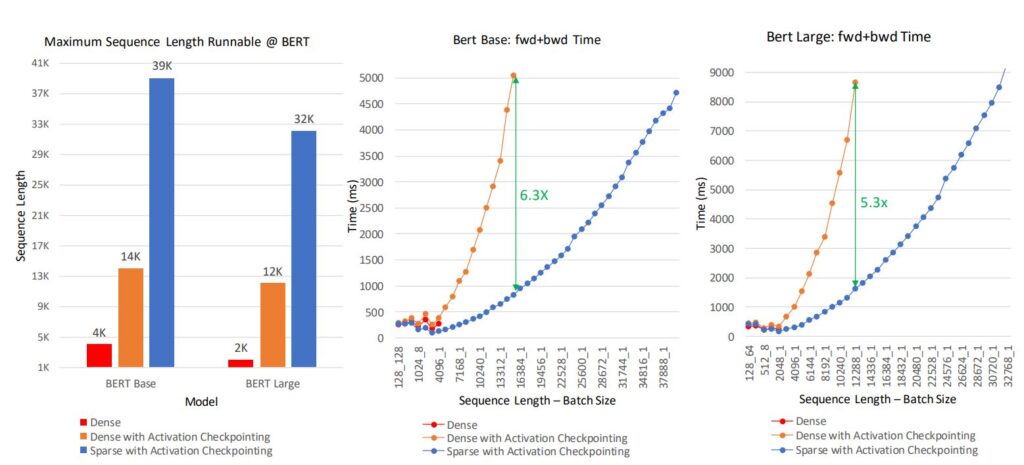
System performance: SA powers over 10x longer sequences and up to 6.3x faster computation as shown in Figure 11. The left figure shows the longest sequence length runnable in BERT-Base and BERT-Large models under three settings: dense, dense with activation checkpoint, and sparse (SA) with activation checkpoint. SA empowers 10x and 16x longer sequences when compared with dense for BERT-Base and BERT-Large, respectively. Furthermore, SA reduces total computation compared with dense and improves training speed: the boost is higher with increased sequence length, and it is up to 6.3x faster for BERT-Base and 5.3x for BERT-Large.
-
Related works along the line of sparse attention (Sparse Transformer (opens in new tab), Longformer (opens in new tab), BigBird (opens in new tab)) have shown comparable or higher accuracy than full attention. Our experience is well aligned. In addition to lower memory overhead and faster computation, we also observe cases in production models where SA reaches higher accuracy and faster convergence. The following chart illustrates the accuracy of training a production model based on BERT for long document comprehension (2,048 sequence length). The experiment is performed in three settings: dense starting from scratch, SA starting from scratch, and SA continued training from a checkpoint of using dense with a sequence length of 512. We have observed that, for pretraining from scratch, SA converges faster with higher accuracy compared with dense. Furthermore, continuing training from a pretrained checkpoint with SA performs even better, with respect to both time and accuracy.
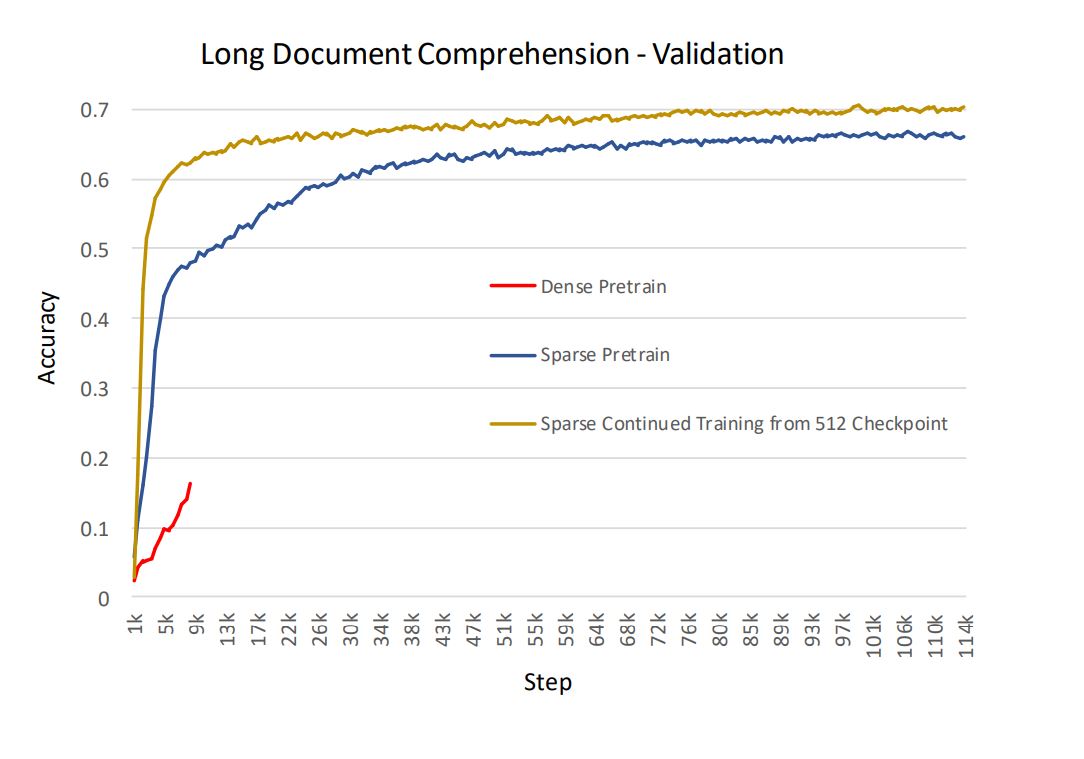
Figure 12: Accuracy of long document comprehension application -
We compared SA with Longformer, a state-of-the-art sparse structure and implementation. In our experiment, SA uses “Fixed (opens in new tab)” sparsity, and two implementations have comparable accuracy. On system performance, SA outperforms Longformer both in training and inference:
- 1.5x faster execution pretraining MLM on Wikitext103
- 3x faster execution inference on BERT-Base (batch size 1, sequence length 2,048)
Flexibility to handle any block-sparse structure: DeepSpeed sparse attention suite does not target any specific sparse structure but enables model scientists to explore any block sparse structure with efficient system support. Currently, we have added popular sparse structures, like Fixed (opens in new tab)(from OpenAI Sparse Transformer), BigBird (opens in new tab)(from Google), and BSLongformer (Block-Sparse implementation of AI2 Longformer (opens in new tab)). We also define a template to have “variable” structure, shown in Figure 10, which can be used to simply customize any block-sparse random, local, or global attention pattern.
1-bit Adam: 5x less communication and 3.4x faster training
Scalable training of large models (like BERT and GPT-3) requires careful optimization rooted in model design, architecture, and system capabilities. From a system standpoint, communication has become a major bottleneck, especially on commodity systems with standard TCP interconnects that offer limited network bandwidth.
Communication compression is an important technique to reduce training time on such systems. One of the most effective ways to compress communication is via error compensation compression, which offers robust convergence speed, even under 1-bit compression. However, state-of-the-art error compensation techniques only work with basic optimizers like Stochastic Gradient Descent (SGD) and momentum SGD, which are linearly dependent on the gradients. They do not work with non-linear gradient-based optimizers like Adam, which offers state-of-the-art convergence efficiency and accuracy for many tasks, including training of BERT-like models.
For a powerful optimizer like Adam, the non-linear dependency on gradient (in the variance term) makes it challenging to develop error compensation-based compression techniques, limiting the practical value of the state-of-the-art communication compression techniques.
-
One way of communication compression is 1-bit compression, which can be expressed as:

With this compression, we could achieve a 32x reduction of memory size by representing each number using one bit. The problem is that using this straightforward method would significantly degrade the convergence speed, which makes this method inapplicable. To solve this problem, recent studies show that by using error compensation compression, we could expect almost the same convergence rate with communication compression.
The idea of error compensation can be summarized as: 1) doing compression, 2) memorizing the compression error, and then 3) adding the compression error back in during the next iteration. For SGD, doing error compression leads to:
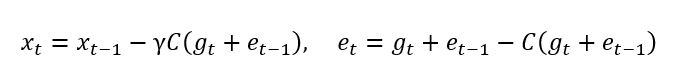
Where \(C(⋅)\) is the 1-bit compression operator. The good thing about doing this error compensation is that the history compression error \(e_t\) and \(e_t-1\) would be canceled by itself eventually, which can be seen by:
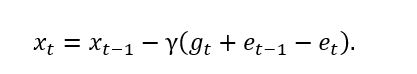
This strategy has been proven to work for all optimization algorithms that are linearly dependent on the gradient, such as SGD and Momentum SGD.
-
We provide an overview of the Adam algorithm below. The update rules are as follows.

As shown in the equations above, the variance term \(v_t\) is nonlinearly dependent on the gradient \(g_t\). If we apply basic error compensation compression to Adam, we observe that Adam will not converge as shown in Figure 13.

Figure 13: Inapplicability of Error-compensation Compression for Adam due to non-linear dependence on the gradient
Compressing communication with 1-bit Adam
To compress communication while using the Adam optimizer, we develop 1-bit Adam, which addresses the non-linearity in gradients via preconditioning. We observe that the magnitude of changes on the non-linear term, variance (\(v_t\)), decrease significantly after a few epochs of training and setting \(v_t\) constant afterwards will not change the convergence speed. The proposed 1-bit Adam optimizer, as shown in Figure 14, consists of two parts: the warmup stage, which is essentially the vanilla Adam algorithm; and the compression stage, which keeps the variance term constant and compresses the remaining linear term, that is the momentum, into 1-bit representation.
The compression stage of the algorithm is controlled by a threshold parameter (as shown in Figure 14). When we detect that the change in “variance” falls below a certain threshold, we switch to the compression stage. Our study shows that only 15-20% of the overall training steps are needed for the warmup stage.
-
The weight update rule for 1-bit Adam is governed by the following equations. For the i
th worker, in the compression stage:

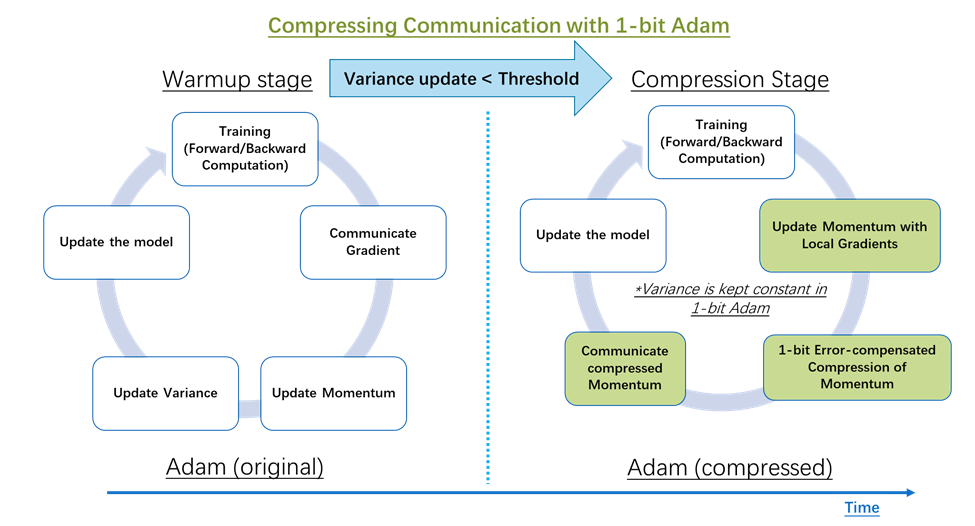
Addressing system challenges for 1-bit Adam
Besides the algorithmic challenge, there are two system challenges in applying 1-bit Adam in training systems. First, we need efficient kernels that convert the momentum to 1-bit representations. Second, we need efficient communication schemes to exchange this compressed momentum across different GPUs. The goal of compression is to reduce the overall training time so that commodity systems with bandwidth-limited interconnects can be used to train large models. We address these challenges in DeepSpeed and introduce a fully optimized 1-bit Adam implementation for training on communication-constrained systems.
Benefits of 1-bit Adam on communication-constrained systems
1-bit Adam offers the same convergence as Adam, incurs up to 5x less communication that enables up to 3.5x higher throughput for BERT-Large pretraining and up to 2.7x higher throughput for SQuAD fine-tuning. This end-to-end throughput improvement is enabled by the 6.6x (Figure 15 left) and 6.2x (Figure 15 right) speedup observed during the compression stage. It is worth mentioning that our 1-bit Adam optimizer scales so well on a 40 Gigabit Ethernet system that its performance is comparable to Adam’s scalability on a 40 Gigabit InfiniBand QDR system. We note that the effective bandwidth on 40 Gigabit Ethernet is 4.1 Gbps based on iPerf benchmarks, whereas InfiniBand provides near-peak bandwidth of 32 Gbps based on InfiniBand perftest microbenchmarks.

-
Same convergence as Adam: One major question for using 1-bit Adam is the convergence speed, and we find that 1-bit Adam can achieve the same convergence speed and comparable testing performance using the same number of training samples as shown in Figure 16.
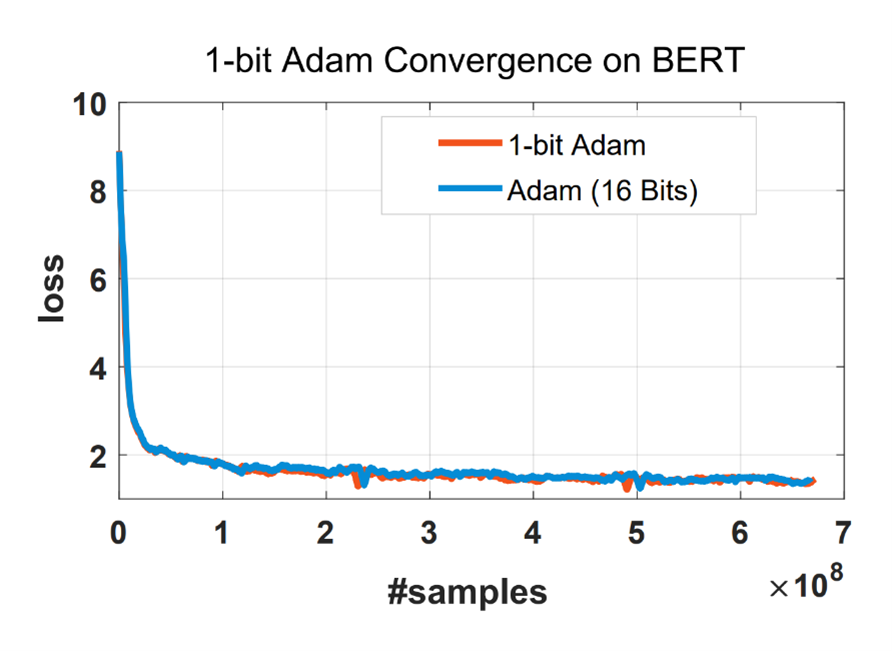
Figure 16: 1-bit Adam converges like Adam using the same number of training samples. Detailed BERT-Base and BERT-Large results are shown in Table 1. We see that the scores are on par with or better than the original model for both the uncompressed and compressed cases.
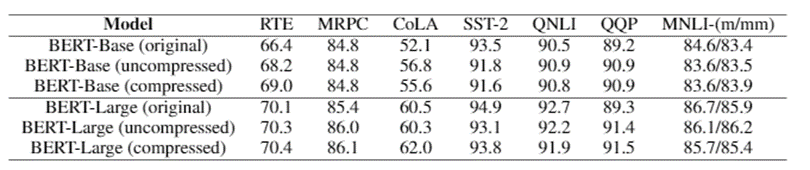
Table 1: Verifying correctness of 1-bit Adam on various testing tasks Up to 5x less communication: 1-bit Adam provides the same convergence as Adam and reduces the communication volume by 16x during the compression stage for 16-bit (FP16) training. For BERT pretraining, this leads to an overall communication reduction of 5x as we observed the warmup stage to be just 15% of the end-to-end training time.
The formula to calculate the communication volume ratio of the original versus 1-bit Adam is as follows:
1 / (warmup + (1 – warmup)/16)
1-bit Adam is 3.5x faster for training BERT-Large: We present two main results for training BERT-Large on systems with two different bandwidth-limited interconnects: 1) 40 Gbps Ethernet (Figure 17 left) and 2) 40 Gbps InfiniBand QDR (Figure 17 right). During the compression phase, we observe up to 6.6x higher throughput on the system with Ethernet and up to 2x higher throughput on the system with InfiniBand, resulting in end-to-end speed up (including both warmup and compression stages) of 3.5x and 2.7x, respectively. The major benefit of 1-bit Adam comes from the communication volume reduction—enabled by our compressed momentum exchange—and from our custom allreduce operation that implements efficient 1-bit communication using non-blocking gather operations followed by an allgather operation.
It is important to note that one can also increase total batch size to reduce communication using optimizers like LAMB instead of Adam for BERT pretraining. However, 1-bit Adam avoids the need for rigorous hyperparameter tuning, which is often more difficult for large batches from our experience. Furthermore, 1-bit Adam also works very well for workloads that have small critical batch size (cannot converge well with large batch size) like many fine-tuning tasks.
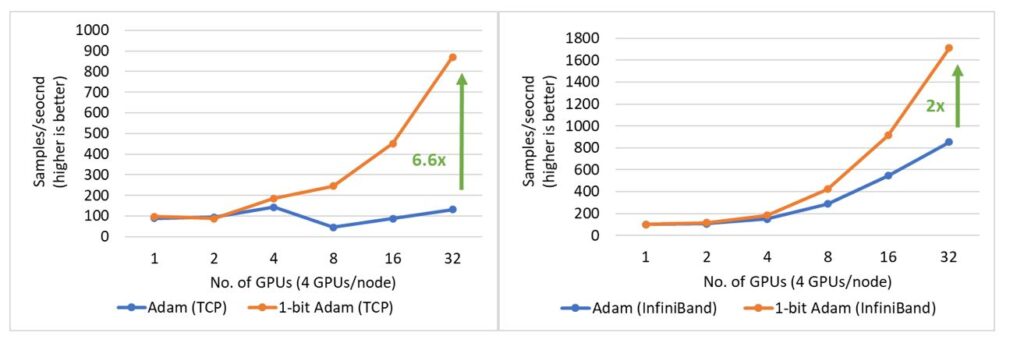
Figure 17: Performance of 1-bit Adam for BERT-Large training on 40 Gbps Ethernet (left) and InfiniBand (right) interconnect during the compression stage. 1-bit Adam is 2.7x faster for SQuAD fine-tuning: 1-bit Adam offers scalability not only on large-scale training tasks but also on tasks like SQuAD fine-tuning. As shown in Figure 18, 1-bit Adam scales well on both Ethernet- and InfiniBand-based systems and offers up to 6.2x higher throughput (during the compression stage) on the Ethernet-based system, resulting in 2.7x end-to-end speedup (25% warmup plus 75% compression stage). For SQuAD fine-tuning, we observed that a total batch size of 96 offers the best F1 score. Batch sizes larger than this value lower the convergence rate and require additional hyperparameter tuning. Therefore, in order to scale to 32 GPUs, we can only apply a small batch size of 3-4 per GPU. This makes fine-tuning tasks communication intensive and hard to scale. 1-bit Adam addresses the scaling challenge well, obtaining 3.4x communication reduction without enlarging batch size, and it results in a 2.7x end-to-end speedup.
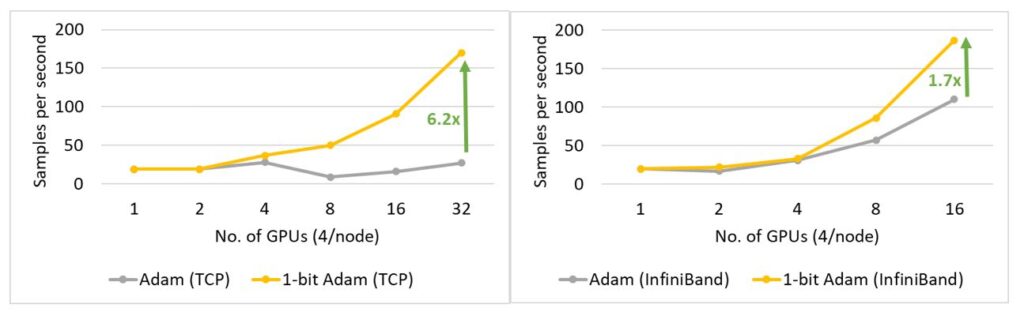
Figure 18: Performance of 1-bit Adam for SQuAD fine-tuning on 40 Gbps Ethernet (left) and InfiniBand (right) interconnect during the compression stage.
Please visit DeepSpeed website (opens in new tab) and Github repository (opens in new tab) for the codes, tutorials and documentations about these new technologies! We are also integrating some of these techniques into ONNX Runtime (opens in new tab).
About our great collaborators:
- We would like to acknowledge our academic collaborator, Philippe Tillet from Harvard University, for helping us co-develop sparse attention kernels through Triton (opens in new tab) compiler.
- ZeRO-Offload was co-developed with our intern Jie Ren from UC Merced. We would also like to thank Dong Li from UC Merced, as well as Bharadwaj Pudipeddi and Maral Mesmakhouroshahi from Microsoft L2L work (opens in new tab), for their discussions on the topic.
- 1-bit Adam was co-developed with our intern Hanlin Tang from University of Rochester.
- We would like to thank the great collaboration from NVIDIA, especially the Megatron-LM team.
About the DeepSpeed Team:
We are a group of system researchers and engineers—Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Reza Yazdani Aminabadi, Elton Zheng, Arash Ashari, Jing Zhao, Minjia Zhang, Niranjan Uma Naresh, Shaden Smith, Ammar Ahmad Awan, Conglong Li, Yuxiong He (team lead) — who are enthusiastic about performance optimization of large-scale systems. We have recently focused on deep learning systems, optimizing deep learning’s speed to train, speed to convergence, and speed to develop!