Microsoft senior researcher Miro Dudík.
News portals that simultaneously personalize every part of the landing page for every visitor and mobile health apps that adaptively tweak every part of an exercise regimen to maximize the benefit of every user are becoming plausible due to an advance in a type of interactive machine learning that my team will describe at the Annual Conference on Neural Information Processing Systems running December 4-9 in Long Beach, California.
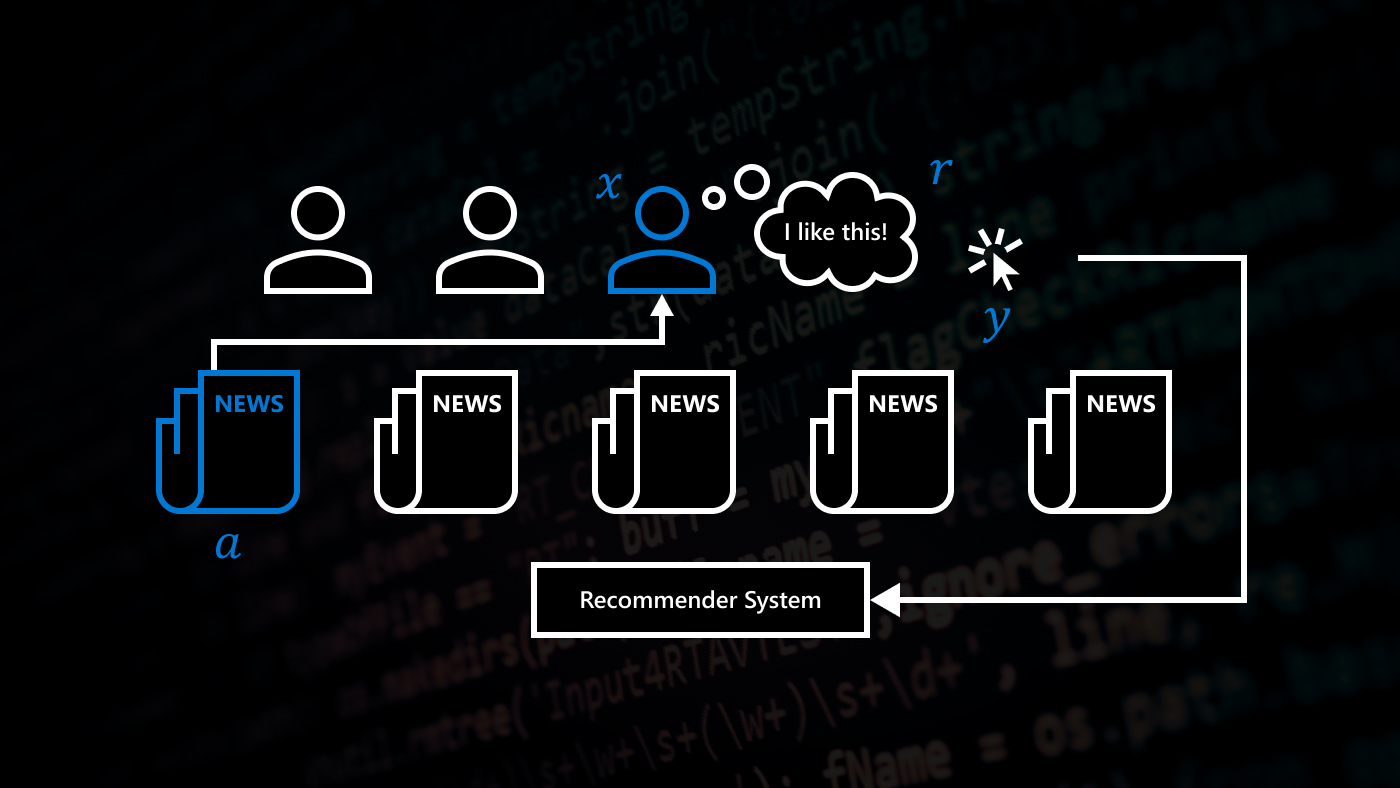
Our research falls in an important area of interactive machine learning known as contextual bandits. The area encompasses applications such as news recommendation, advertising, mobile health and digital personal assistants. These applications are implemented by computer systems that repeatedly present content to the user, detect whether the presented content is successful and over time learn to pick the best content. The fact that algorithms can optimize the content in a context-dependent manner, based on user characteristics, gives rise to the name «contextual bandits.”
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
At NIPS 2017 , Adith Swaminathan from Microsoft Research AI will give a talk that outlines our team’s solution to an unresolved challenge in the field: How to learn when the number of content choices, called actions, is very large – say larger than 100. We make a modest structural assumption that allows us to attack this challenge and substantially enlarge the set of applications of contextual bandits. For instance, we can now optimize not only the top article on a news portal, but the whole page. In mobile health, we can dramatically enlarge the set of possible interventions and thus improve their efficacy.

Microsoft researcher Adith Swaminathan.
The challenge with large action spaces is that to learn the right action for each user requires either a lot of domain knowledge or a lot of user interaction data.
The domain knowledge comes in the form of a user model, which is a functional description of the user behavior, and against which we can optimize the computer system. Unfortunately, such user models are notoriously imperfect, and so require an expensive trial-and-error cycle of A/B tests for system optimization. In my research with several collaborators at Microsoft Research New York, I have been studying how to avoid the need for this expensive trial-and-error cycle. Contextual bandits provide an elegant alternative by taking advantage of already logged interaction data. If the past data is collected carefully, the computer system can be optimized against this data directly, without the need for a user model or for a follow-up A/B test.
The data sizes needed by previous contextual bandit approaches scale linearly with the number of actions. This cannot be improved in the worst case, but most real-world applications have a favorable structure. Their actions are composed of multiple simpler decision items and the quality of an action can be approximately modeled as the sum of intrinsic item qualities. For instance, the quality of a news webpage is the sum of qualities of the presented news articles. The paper that we are presenting at NIPS exploits this structure to decrease the data requirements exponentially: we only need the data sizes that scale linearly with the number of items rather than actions. So instead of 100 possible actions, we can consider 10100 possible actions, which is more than the number of atoms in the universe! In practical terms, this means that we can optimize suggestions with many moving parts, such as landing pages or exercise regimens.
We achieve this improvement thanks to a new estimator called the pseudo-inverse estimator, which exploits the decomposability of actions. The estimator uses the logged data to accurately estimate the quality of any content-serving policy, and in fact can be used to find the best policy. The decomposability assumption is quite flexible. While the success metric of an action must equal the sum of intrinsic qualities of presented items, the intrinsic quality of an item is not required to be directly observed and can be different for each user. User modeling approaches attempt to fit the quality of an item, such as a news article, from descriptive features of the item and the user, such as the article topic and the user’s past frequency of reading articles with the same topic. The somewhat surprising finding of our work is that we do not need to fit the item qualities from such features. As long as we observe the success metric of the action as a whole, for instance, the time a user spends on a news portal, the pseudo-inverse estimator can invert this feedback into unbiased estimates of item qualities. This allows us to partially predict how other actions with the same items would fare, so we are using our data substantially more efficiently. Ultimately, we require much less data to find the optimal content-serving policy.
In our paper, which is based on research that Adith Swaminathan performed during a PhD internship, we mathematically prove the exponential savings when our assumption holds. In practice, the success metric might only be an approximate sum of item qualities. To see how this impacts our method, we collaborated with Bing scientists on search data to check how our method works with product metrics such as time-to-success and utility rate, which is a measure of utility the user derives from using a service. Even though these two metrics do not decompose across items, our estimator still requires substantially less data than other baselines.
Altogether, this is an example of a research project that is uniquely possible at Microsoft. The research began with an important theoretical question leading to a mathematically appealing solution, which we were able to try out on real-world data and measure its impact.
In addition to Adith Swaminathan from Microsoft Research AI, the team of authors includes researchers Alekh Agarwal, Miroslav Dudik, John Langford and former postdoc Akshay Krishnamurthy from Microsoft Research New York, Imed Zitouni from Microsoft’s AI Core, and Damien Jose from Bing.
Related:
- Debugging data: Microsoft researchers look at ways to train AI systems to reflect the real world
- Microsoft Research at NIPS 2017
- Off-Policy Evaluation For Slate Recommendation
- ICML 2017 Tutorial on Real World Interactive Learning
- Multiworld Testing
- Real world interactive learning at cusp of enabling new class of applications