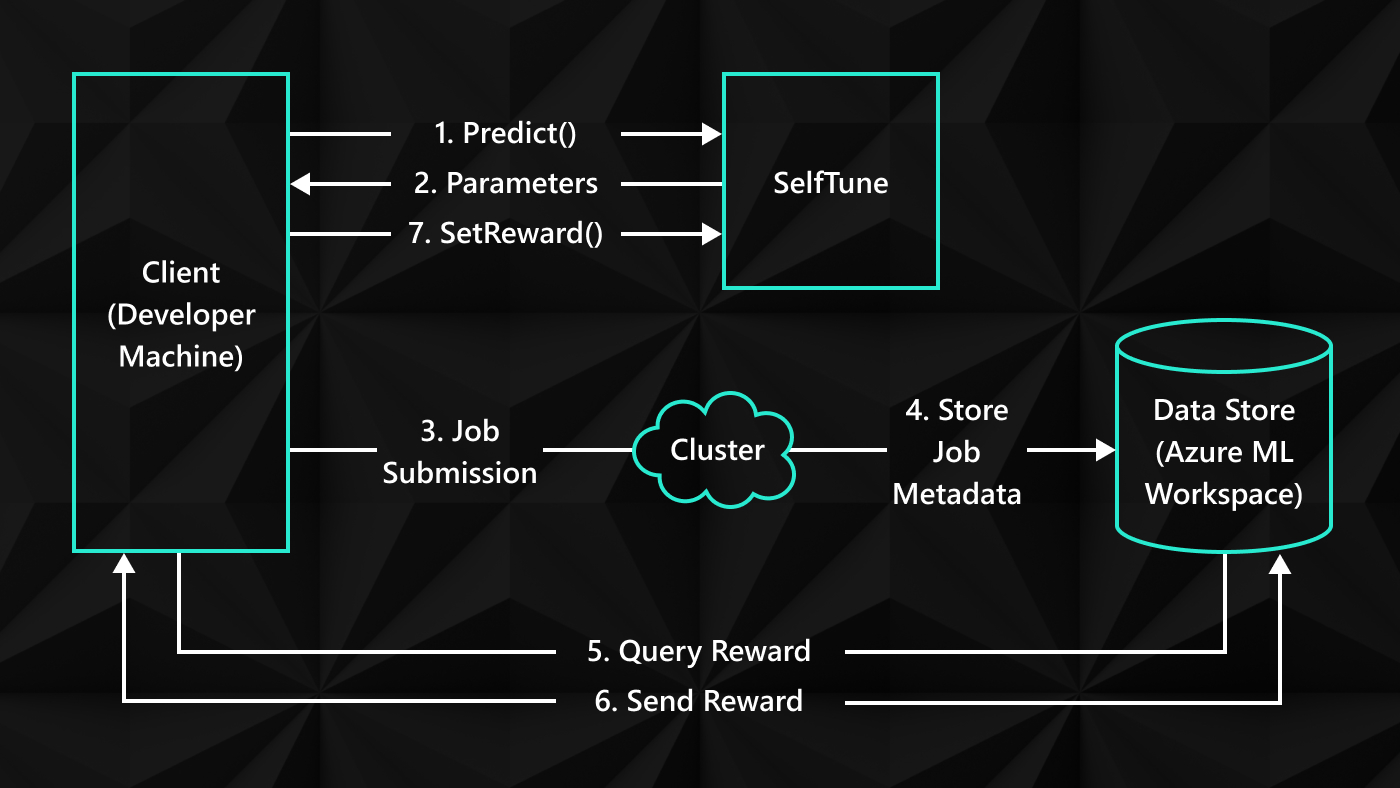
Members of the Emory University team (from left): Ph.D. student Samanesh Nasiri and software engineers Amit Verma and Alvince Pongos
It’s not uncommon for physicians to disagree about a diagnosis. That’s why people often seek a second or third opinion when faced with a serious or complex health concern. What if instead of a second opinion, hundreds of expert opinions could be collated? What if those experts were a combination of both humans and AI algorithms, as is the case in a crowdsourced version of traffic model convergence? That’s the promise of work being done at Emory University in Atlanta by Dr. Gari Clifford (opens in new tab), interim chair and associate professor in the university’s School of Medicine, and we at Microsoft Research are excited to support him and his team in their innovative efforts to make AI diagnoses more accurate.
Through our partnership with the National Science Foundation (opens in new tab), we have been able to provide them with cloud computing resources to better manage the growing number of algorithms and datasets they employ in tackling this goal.
The work: Creating a super algorithm
Microsoft Research Blog

Microsoft Research Forum Episode 3: Globally inclusive and equitable AI, new use cases for AI, and more
In the latest episode of Microsoft Research Forum, researchers explored the importance of globally inclusive and equitable AI, shared updates on AutoGen and MatterGen, presented novel use cases for AI, including industrial applications and the potential of multimodal models to improve assistive technologies.
Dr. Clifford and his team target a variety of medical scenarios, including heart arrhythmias, which we’ll use as a case study here to explore the two-step approach they take to their work. First, they have cardiologists help train algorithms by labeling electrocardiograms, or recordings of the heart, as normal, noisy, or abnormal in rhythm. They then use a mathematical process to determine which of the doctors are most accurate and assign weights to their labels proportionally. In the second step, the team conducts an international challenge in which the labeled data is made available to the larger research community (opens in new tab), resulting in a collection of independent algorithms that can learn from the labels to be almost as accurate as the doctors when labeling new data. The leading algorithms are then used to “vote” on the labels, creating a super algorithm that is more accurate than any single one. The eventual result, it is hoped, will be an AI system that can identify heartbeat abnormalities with precision.
This approach is particularly useful in cases where experts disagree. Said Dr. Clifford, “In normal machine training exercises, if a subset of the data can’t be labeled (because the experts disagree), the computer scientists may just throw out that data. But when you’re dealing with people, with real diagnoses that experts disagree on, that’s where the most important data resides. Solving the currently unsolvable problems is what this project is trying to do.”
When the researchers commercialize this labeling system, it could ultimately be able to review the data from wearables, such as the latest smart watches and fitness trackers, to alert consumers if or when they have an abnormal heartbeat. Today, a prototype cloud-based system facilitates the upload of medical data and algorithms to create an ever-growing database of arrhythmia events.
Said Dr. Clifford, “We have shown that this system can identify the minimum number of experts needed to provide accurate labels on the electrocardiogram.” This research has additional applications to other health scenarios, including critical care monitoring, sleep analysis, epilepsy seizure prediction, and perinatal monitoring.
Improving scalability with cloud computing
As the algorithms and datasets began to grow, more computing resources became necessary to respond rapidly to the many users contributing. When competing in the international challenges, teams wanted to run their algorithms on the same datasets at the same time and receive an answer within minutes or hours, so scalability was an important design consideration.
Dr. Clifford applied for and received $62,000 worth of Microsoft Azure resources (opens in new tab) via a grant from the National Science Foundation’s Big Data Regional Innovation Hubs program (opens in new tab), which facilitates collaboration among the government, research community, and private sector in using data science to address societal needs and to which we committed $3 million in Azure credits in June 2016 (opens in new tab).
Dr. Clifford finds Azure is both fast and scalable and that with Azure Kubernetes Service (opens in new tab), formerly Azure Container Service, fewer resources are required than with virtual machines and the runtime components, libraries, and operating system are portable from machine to machine.
Curating these datasets using machine learning running on container-based Azure resources helps reduce the uncertainty in labeling to facilitate more efficient and effective human-AI collaboration. Dr. Clifford and his team have demonstrated a novel approach through this ensemble of cloud-enabled machine learning, competition, and expert labeling.
While the proliferation of data relevant to health opens enormous opportunities for individuals, health care providers, and researchers, addressing data labeling and other such challenges is an important step in leveraging this data for better health care outcomes, and Azure is here to help.