
Imagine an AI model that can seamlessly generate high-quality content across text, images, video, and audio, all at once. Such a model would more accurately capture the multimodal nature of the world and human comprehension, seamlessly consolidate information from a wide range of sources, and enable strong immersion in human-AI interactions. This could transform the way humans interact with computers on various tasks, including assistive technology, custom learning tools, ambient computing, and content generation.
- Publication Any-to-Any Generation via Composable Diffusion
In a recent paper: Any-to-Any Generation via Composable Diffusion (opens in new tab), Microsoft Azure Cognitive Service Research (opens in new tab) and UNC NLP (opens in new tab) present CoDi, a novel generative model capable of processing and simultaneously generating content across multiple modalities. CoDi allows for the synergistic generation of high-quality and coherent outputs spanning various modalities, from assorted combinations of input modalities. CoDi is the latest work of Microsoft’s Project i-Code (opens in new tab), which aims to develop integrative and composable multimodal AI. Through extensive experiments, the researchers demonstrate CoDi’s remarkable capabilities.
The challenge of multimodal generative AI
The powerful cross-modal models that have emerged in recent years are mostly capable of generating or processing just one single modality. These models often face limitations in real-world applications where multiple modalities coexist and interact. Chaining modality-specific generative models together in a multi-step generation setting can be cumbersome and slow.
Moreover, independently generated unimodal streams may not be consistent and aligned when stitched together in a post-processing way, such as synchronized video and audio.
To address these challenges, the researchers propose Composable Diffusion (CoDi), the first model capable of simultaneously processing and generating arbitrary combinations of modalities. CoDi employs a novel composable generation strategy that involves building a shared multimodal space by bridging alignment in the diffusion process, enabling the synchronized generation of intertwined modalities, such as temporally aligned video and audio.
Microsoft Research Blog

Microsoft Research Forum Episode 3: Globally inclusive and equitable AI, new use cases for AI, and more
In the latest episode of Microsoft Research Forum, researchers explored the importance of globally inclusive and equitable AI, shared updates on AutoGen and MatterGen, presented novel use cases for AI, including industrial applications and the potential of multimodal models to improve assistive technologies.
The power of composable diffusion
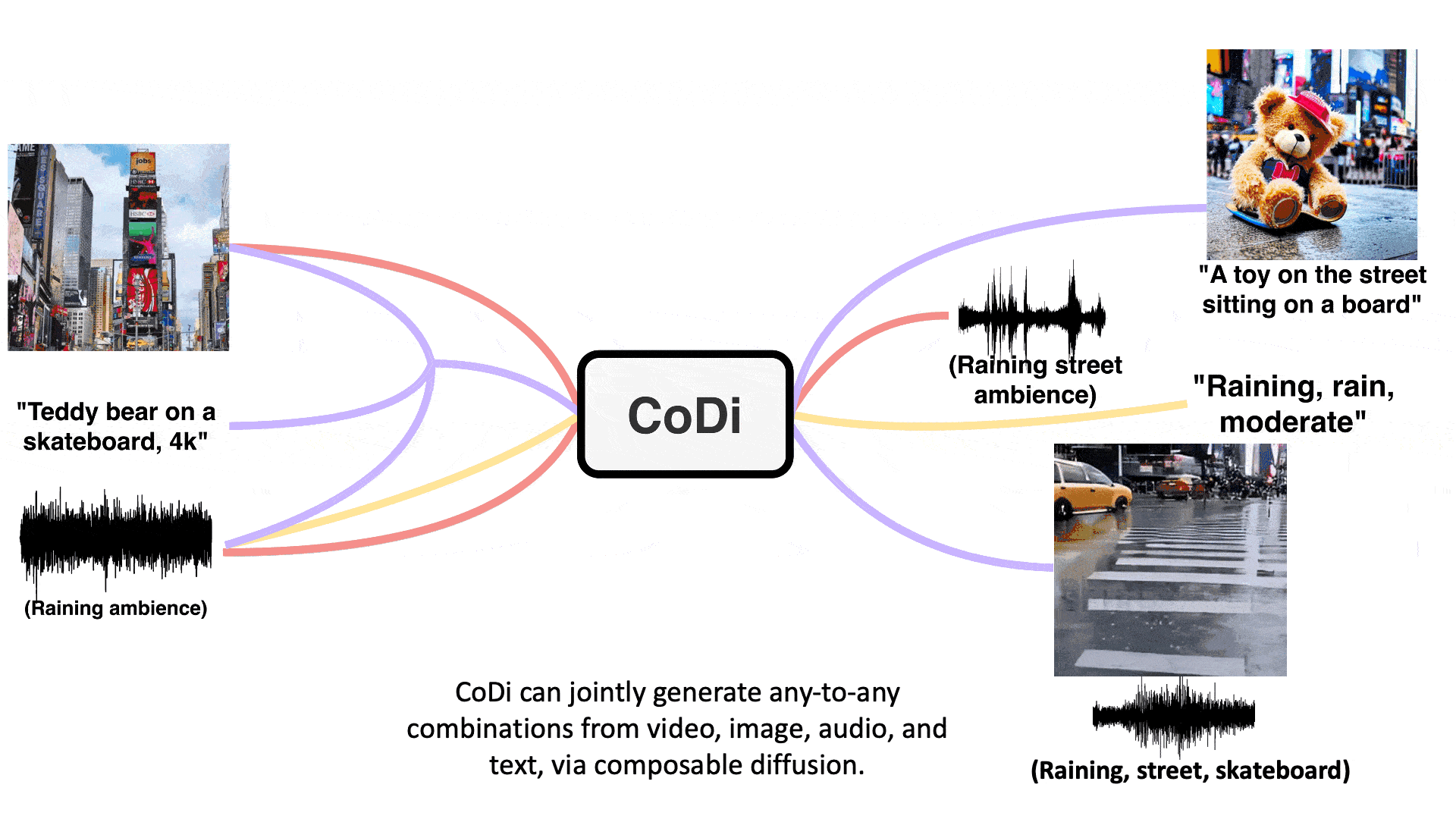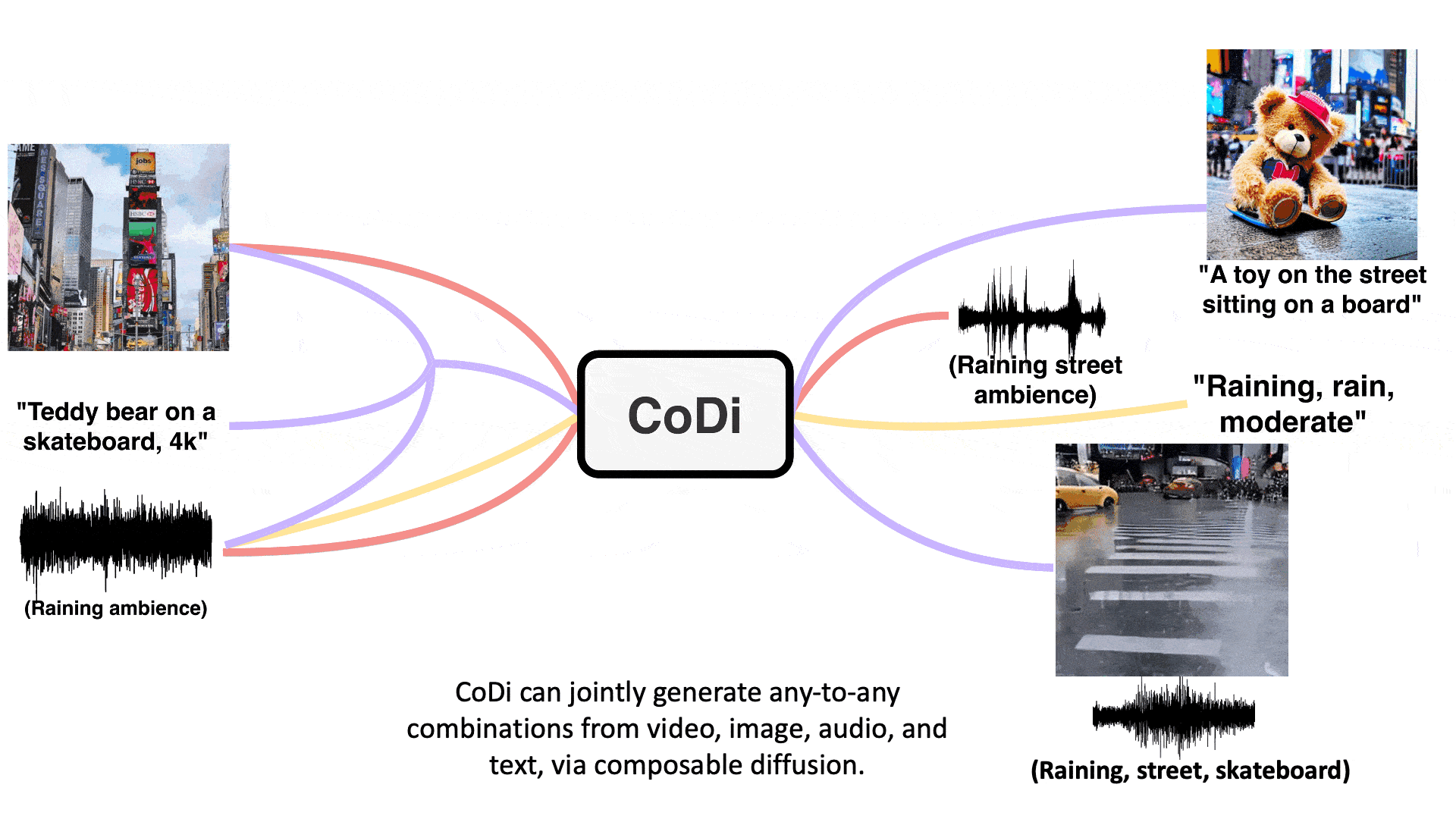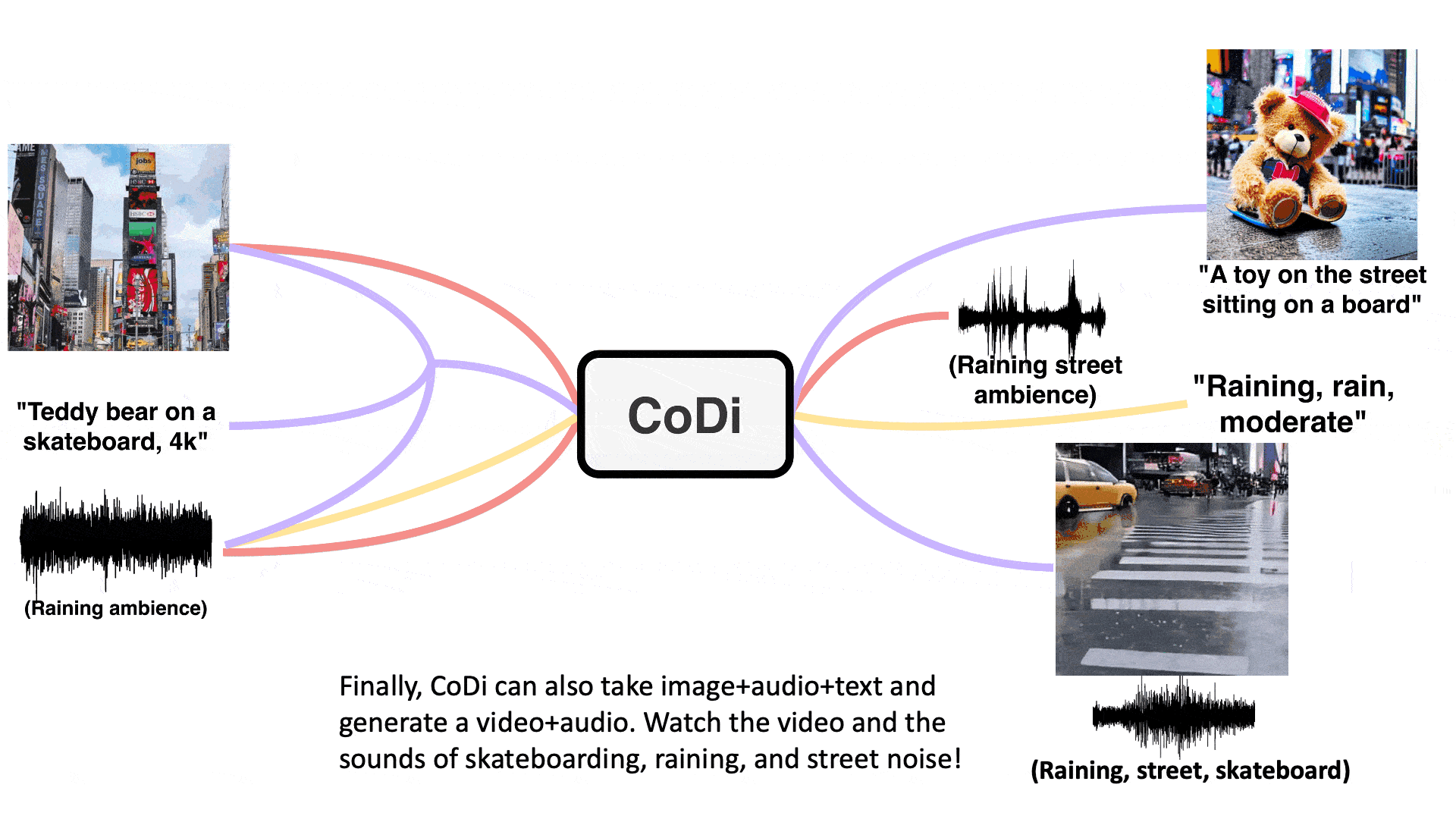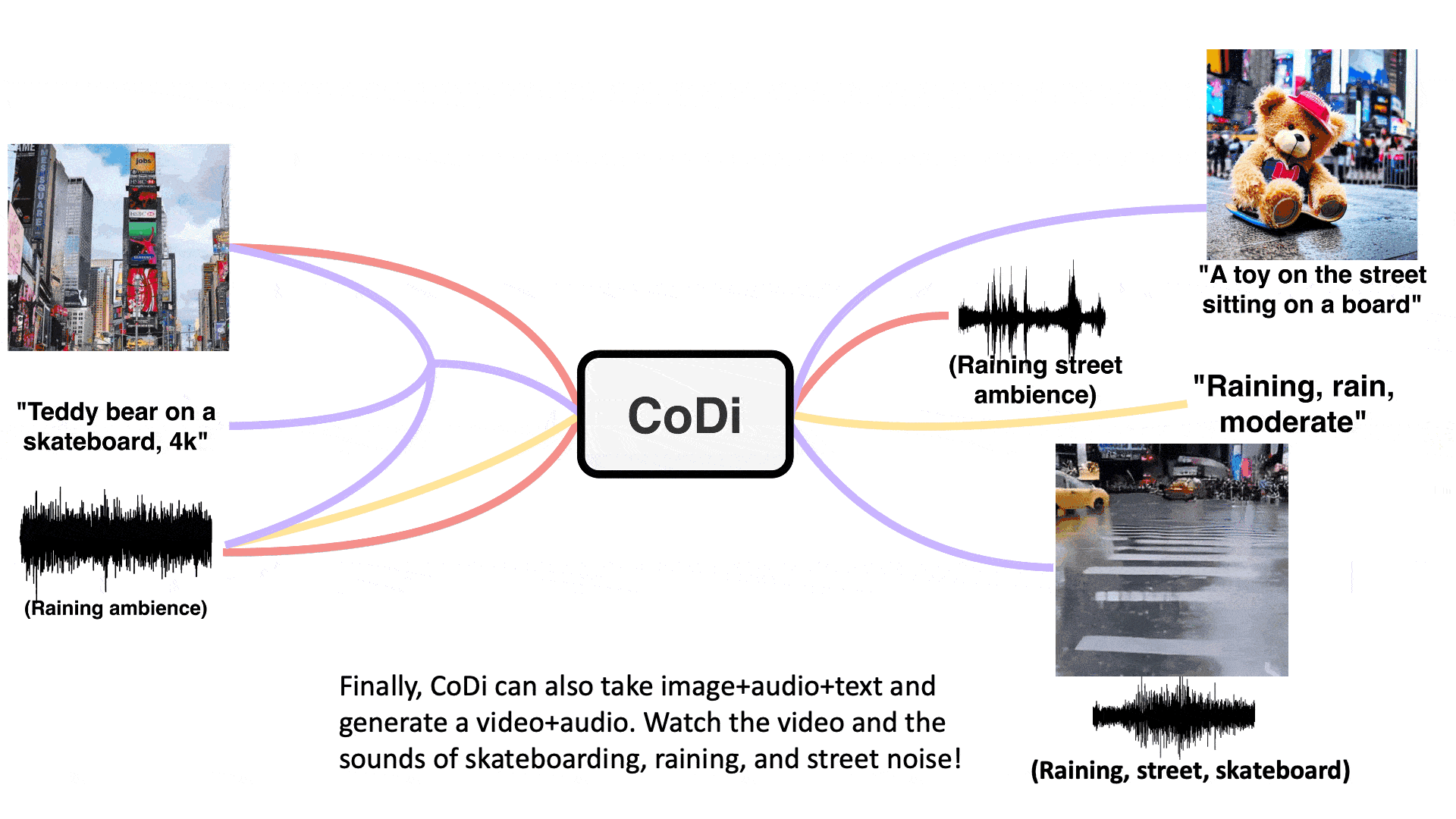
Training a model to take any mixture of input modalities and flexibly generate any mixture of outputs presents significant computational and data requirements, as the number of combinations for the input and output modalities scales exponentially. And the scarcity of aligned training data for many groups of modalities makes it infeasible to train with all possible input-output combinations. To address these challenges, the researchers propose to build CoDi in a composable and integrative manner.
They start by training each individual modality-specific latent diffusion model (LDM) independently (these LDMs will be smoothly integrated later for joint generation). This approach ensures exceptional single-modality generation quality using widely available modality-specific training data. To allow CoDi to handle any mixture of inputs, input modalities like images, video, audio, and language are projected into the same semantic space. Consequently, the LDM of each modality can flexibly process any mixture of multimodal inputs. The multi-conditioning generation process is done by letting diffusers be conditioned on these inputs via a weighted sum of each input modality’s representation.
One of CoDi’s most significant innovations is its ability to handle many-to-many generation strategies, simultaneously generating any mixture of output modalities. To achieve this, CoDi adds a cross-attention module to each diffuser, and an environment encoder to project the latent variable of different LDMs into a shared latent space.
By freezing the parameters of the LDM and training only the cross-attention parameters and the environment encoder, CoDi can seamlessly generate any group of modalities without training on all possible generation modality combinations, reducing the training objectives to a more manageable number.
Showcasing CoDi’s capabilities
The research demonstrates the novel capacity of joint generation of multiple modalities, such as synchronized video and audio, given separate text, audio, and image prompts. Specifically, in the example shown below, the input text prompt is “teddy bear on a skateboard, 4k, high resolution”, the input image prompt is a picture of Times Square, and the input audio prompt is rain. The generated video, shown in Figure 2, is a teddy bear skateboarding in the rain at Times Square. The generated audio contains the sounds of rain, skateboarding, and street noise, which are synchronized with the video. This shows that CoDi can consolidate information from multiple input modalities and generate coherent and aligned outputs.
In addition to its strong joint-modality generation quality, CoDi is also capable of single-to-single modality generation and multi-conditioning generation. It outperforms or matches the unimodal state of the art for single-modality synthesis.
Potential real-world applications and looking forward
CoDi’s development unlocks numerous possibilities for real-world applications requiring multimodal integration. For example, in education, CoDi can generate dynamic, engaging materials catering to diverse learning styles, allowing learners to access information tailored to their preferences, while enhancing understanding and knowledge retention. CoDi can support some accessible experiences for people with disabilities, such as providing audio descriptions and visual cues for deaf or low-hearing individuals.
Composable Diffusion marks a significant step towards more engaging and holistic human-computer interactions, establishing a solid foundation for future investigations in generative artificial intelligence.



