“Here’s my conference paper—what do you think?” After hours of agonizing over words and illustrations, sharing a draft document is a moment of great pride. All too often, this is shortly followed by embarrassment when your colleague gets back to you with reams of edits. Many of them may be simple grammar or style fixes or requests for citations—minor suggestions that aren’t as fulfilling or valuable for either author or editor as feedback regarding the substance of the content. The most basic form of feedback—pointing out misspelled words—is already ubiquitously automated, but … are there other, more complex classes of editorial tasks that can be learned and automated?
One domain particularly well-suited for exploring this question is source code editing. With advanced version control tools and refactoring utilities, source code repositories provide a wealth of data for training and testing deep learning models to investigate how to represent, discover, and apply edits. In our paper “Learning to Represent Edits,” (opens in new tab) being presented at the 2019 International Conference on Learning Representations (ICLR) (opens in new tab), we’ve used these resources to build unsupervised deep learning models that have shown promise in producing useful classification and application of edits in both code and natural language.
Learning edit representations
Microsoft research podcast

Collaborators: Silica in space with Richard Black and Dexter Greene
College freshman Dexter Greene and Microsoft research manager Richard Black discuss how technology that stores data in glass is supporting students as they expand earlier efforts to communicate what it means to be human to extraterrestrials.
Deep learning has a strong track record in yielding impressive results for generating and understanding natural language and source code. The major challenge in this work is to devise a method that specifically encodes edits so they can be processed and automated by deep learning techniques. To understand our approach, imagine the following analogy:
Consider a photocopier with a large number of settings. For example, there may be switches for black-and-white versus color, enlarging or shrinking a document, and selecting a paper size. We could represent the combination of these settings as a vector—which, for brevity, we’ll refer to as Δ here—that describes the configuration of all the various knobs and switches on the photocopier. Photocopying an original document x– with settings Δ produces a new document x+, which has edits, such as the conversion from color to black-and-white, applied to it. The edits themselves are applied by the photocopier, and Δ is just a high-level representation of those edits. That is, Δ encodes the sentiment “produce a black-and-white copy,” and it is up to the photocopier to interpret this encoding and produce low-level instructions to fine-tune the internal engine for a given input x–.
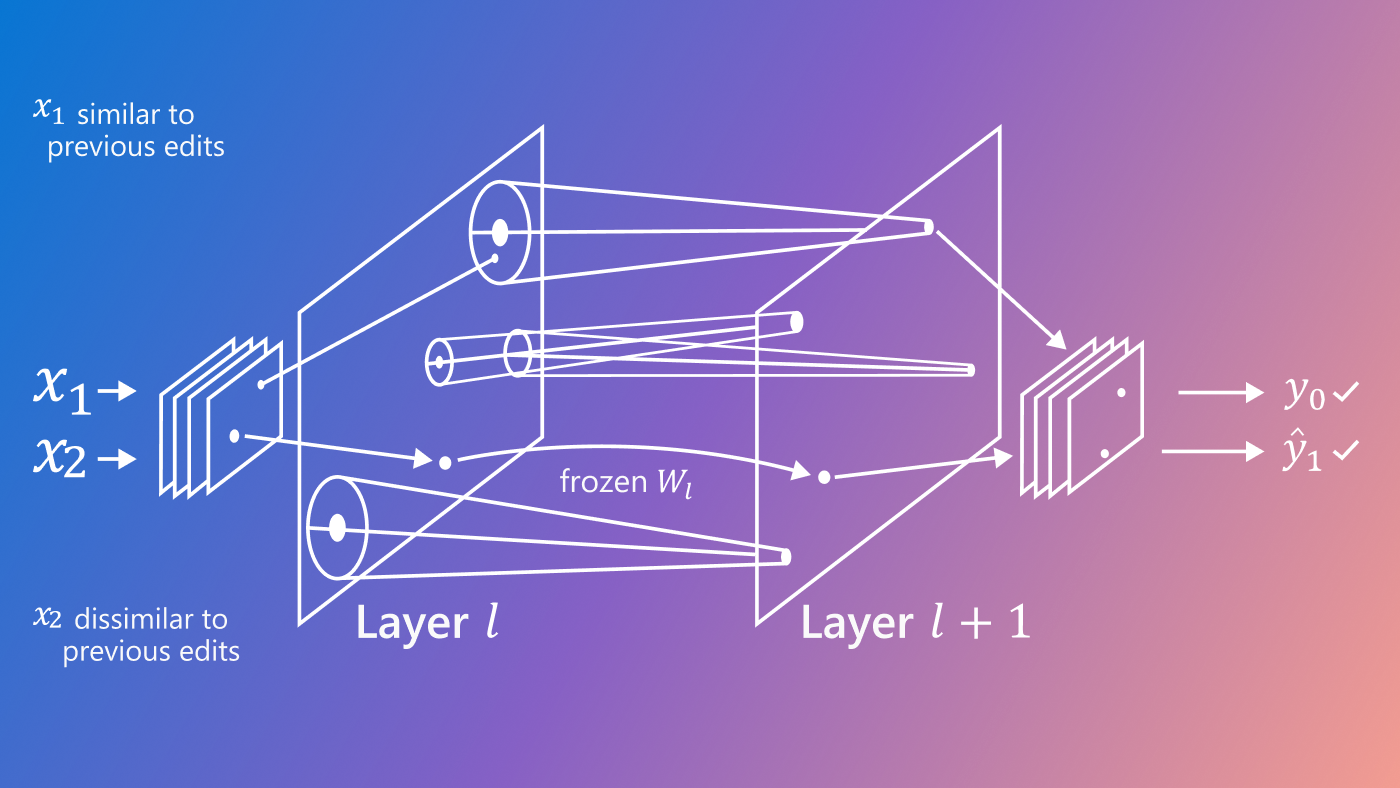
Translating this to our application of source code or natural language editing, the photocopier in the analogy is replaced with a neural network, and the edit representation Δ is a low-dimensional vector provided to that network. We restrict the capacity of this vector to encourage the system to learn to encode only high-level semantics of the edit—for example, “convert output to black-and-white”—rather than low-level semantics such as “make pixel (0,0) white, make pixel (0,1) black, … .” This means that given two different input documents x– and x–‘, Δ should perform the same edit, as shown below for the example source code.
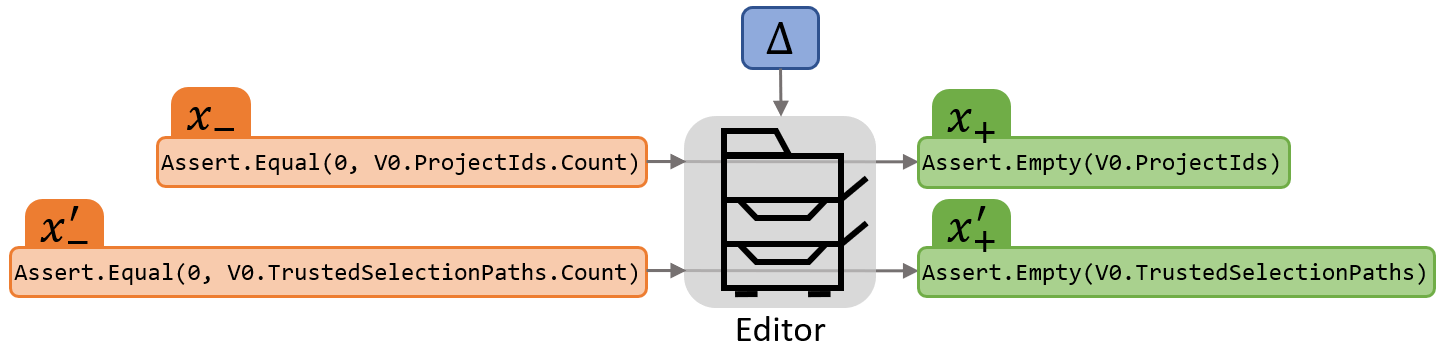
(opens in new tab) The capacity of a low-dimensional vector, represented here by Δ, is restricted to encourage the editor, or neural network, to learn to encode only high-level semantics of an edit. This means that given two different input documents x– and x–‘, Δ should perform the same edit.
In this case, the semantic edit represented by Δ is “assertion of zero count is replaced with assertion of emptiness.”
So far, we’ve described an editor network that implements an edit given an edit representation vector Δ. But how do we learn to turn an observed edit into a high-level representation Δ?
This is similar to learning what the myriad switches and knobs on a photocopier do without a manual or any labels on the switches. To do this, we collected a repository of edits that contain original (x–) and edited (x+) versions. For source code editing, we created a new dataset from commits on open-source code on GitHub (opens in new tab); for natural language editing, we used a preexisting dataset of Wikipedia edits (opens in new tab). From there, we computed the edit representation Δ from x– and x+ using a second neural network called the edit encoder.
The editor and edit encoder networks were trained jointly. We asked the full system to compute an edit representation Δ from x– and x+ informative enough so the editor could use Δ and x– to construct a \(\tilde{x}_+\) identical to the original x+. Therefore, the edit encoder and editor adapt to each other to communicate meaningful edit information through Δ.
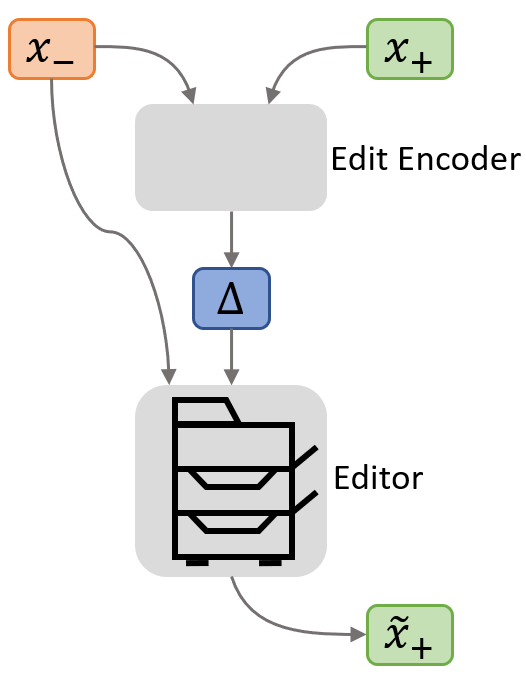
(opens in new tab) To turn an observed edit into a high-level representation Δ, two neural networks—an editor network and an edit encoder network—are trained jointly to compute an edit representation Δ from x– and x+ informative enough so the editor can use Δ and x– to construct a x ̃+ identical to the original x+.
Exploring the learned representations
Now that we can represent edits in a low-dimensional vector space, we can start to address our initial question: Which classes of more complex editorial tasks can be automated?
The first step in answering this is to investigate whether our system can learn to distinguish between different classes of edits. For this, we trained our system on 90,000 C# code edits, and then we used the trained edit encoder to encode 3,000 specially labeled edits. In the labeled set, each edit was generated by one of 16 handcrafted refactoring rules called Roslyn fixers (opens in new tab). An example fixer is RCS1089 (opens in new tab), which has the description “use ++/– operator instead of assignment.” When applied, it replaces statements such as “x = x + 1” with “x++.” We collected the edit representation Δ generated by the edit encoder for each labeled edit and visualized these vectors in 2D using a t-SNE projection; in the below figure, the color of a point indicates from which fixer it was generated.
We observed most of the edits were clustered correctly according to the refactoring rule applied, indicating the edit encoder did a good job of assigning similar representations Δ to similar semantic edits and separating different kinds of edits.

(opens in new tab) A t-SNE visualization of edits generated by the edit encoder using 16 handcrafted refactoring rules called Roslyn fixers showed the encoder was able to assign similar representations to similar semantic edits. The color of a point indicates from which fixer it was generated.
We observed similar results on edits of natural language. Our system clustered semantically meaningful edits together. For example, when the system was trained on Wikipedia edits, one of the edit clusters represented the addition of prepositional phrases such as “on the moon” and “in the market” to sentences and another the addition of middle names to people’s names.
Applying learned edits
We believed when a large corpus of edits had been analyzed and edit clusters identified, canonical edit vectors could be extracted from the cluster centroids and applied to new documents to generate suggestions that automated the editing process. To investigate whether this could work, we again turned to our dataset of edits generated by Roslyn fixers.
To evaluate how well transferring edit representations to a new context would work, we considered two pairs of edits, x– and x+ and y– and y+. We computed an edit representation Δ from the first pair and asked our editor to apply it to y–. For example, we considered an edit that replaced “x = x + 1” with “x++” and then tried to apply the resulting edit representation to “foo = foo + 1.” In our experiments, we found that in about 50 percent of our examples, the editor result would match the expected edit result. However, this varied wildly depending on the complexity of the edit: In examples generated by the RCS1089 fixer, the accuracy was 96 percent, whereas RCS1197 (opens in new tab)—which has the description “optimize StringBuilder.Append/AppendLine call” and rewrites long sequences of code—yielded only 5 percent accuracy.
While our ICLR paper has explored the problem of representing edits in text and code, our presented method is just an early exploration of this interesting data. We see many research opportunities for improving the precision of the method and applying it to other settings. The potential applications are truly exciting: automated improvements of texts, code, or images learned from the work of tens of thousands of expert editors, software developers, and designers. It may mean holding on to that moment of pride even after asking your colleague to edit your next conference paper. Happy writing!