Mixed reality (MR) applications and devices are seeing increased adoption, integrating computation into the fabric of our daily lives. This requires realistic rendering of virtual audio-visual content to deliver sensory immersion to MR users. Producing renderings indistinguishable from reality within tight computational budgets is both a tantalizing and challenging goal. A key component is spatial sound rendering, which provides important auditory cues about the locations of various virtual events within 3D environments.
Microsoft Research is devoted to improving the acoustic estimation and rendering technology for the full range of physical environments in which humans live, work, and play. The Audio and Acoustics Research Group at Microsoft Research has been collaborating across groups throughout the company to advance all major components of the mixed reality audio rendering pipeline. Research from these collaborations is already shipping in Microsoft products and tools, for example Windows Sonic, which provides improved HRTF-based spatialization within Windows and HoloLens, and Project Acoustics, which provides a complete auralization system by combining this HRTF technology with the Project Triton sound propagation engine being researched in the Interactive Media Research Group.
Microsoft Research Blog

Microsoft Research Forum Episode 3: Globally inclusive and equitable AI, new use cases for AI, and more
In the latest episode of Microsoft Research Forum, researchers explored the importance of globally inclusive and equitable AI, shared updates on AutoGen and MatterGen, presented novel use cases for AI, including industrial applications and the potential of multimodal models to improve assistive technologies.
“Our goal is to create audio experiences that seamlessly blend virtual content and reality, and to develop tools that empower artists and content creators to do the same.” – Hannes Gamper, Researcher, Audio and Acoustics Group Microsoft Research
A key unifying research theme evident across all these efforts is the utilizing of existing knowledge about auditory perception quantified as acoustic parameters, which result in systems that are both flexible and efficient.
The IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) is the world’s largest and most comprehensive technical conference focused on signal processing and its applications. This month at ICASSP 2019 in Brighton, United Kingdom, Microsoft Research’s Audio and Acoustics and Interactive Media Research Groups, partnering with product and system designers across Microsoft, and with researchers from New York University, Aalto University, Technische Universität Berlin, and École Polytechnique Fédérale de Lausanne, together present a series of papers advancing three crucial aspects of this research agenda – parameter extraction, efficient binaural rendering, and parameterizing outdoors.
Parameter extraction
In “Blind Room Volume Estimation from Single-Channel Noisy Speech” Hannes Gamper, Nikunj Raghuvanshi, and Ivan J. Tashev of Microsoft Research Redmond, along with Andrea F. Genovese of New York University and Ville Pulkki of Aalto University, propose a method for estimating the physical size of a room directly from speech signals captured by a microphone. Knowledge of room characteristics in terms of geometric and acoustic parameters is important for rendering virtual audio objects that seamlessly blend into the real environment and can also be used to model or design audio filters for various applications. In addition to using such knowledge to enhance the plausibility of immersive audio in MR applications that aim at blending real and virtual sound sources into a cohesive auditory scene, there are numerous applications – speech processing and audio forensics – that can benefit significantly from dynamic and blind estimation on the fly of the acoustic parameters of the local space of a listener. “Our augmented reality audio systems today render virtual objects in generic rooms,” said Keith Godin, Senior Scientist with Microsoft Cloud+AI. “These results will help us build systems that can ground virtual objects in the physical environment of the user, despite the computational limitations of head-worn devices.”
Efficient binaural rendering
In «Improving Binaural Ambisonics Decoding by Spherical Harmonics Domain Tapering and Coloration Compensation» Hannes Gamper, Nikunj Raghuvanshi, and Ivan J. Tashev of Microsoft Research Redmond, along with Christoph Hold of Technical University of Berlin and Ville Pulkki of Aalto University address the issue of rendering complex sound scenes over headphones with spherical harmonics or Ambisonics. While using spherical harmonics allows encoding hundreds of sound sources into a fixed number of channels with fixed rendering and storage costs, the application of head-related transfer functions in the spherical harmonics domain can introduce undesired spectral artifacts. This paper studies the effect of tapering the spherical harmonics representation of a binaurally rendered sound field and proposes a simple spectral equalization technique to reduce coloration and improve perceived audio quality.
Parameterizing outdoors
In “A Sparsity Measure for Echo Density Growth in General Environments” Nikunj Raghuvanshi, Hannes Gamper, and Ivan J. Tashev of Microsoft Research Redmond, along with Helena Peić Tukuljac of École Polytechnique Fédérale de Lausanne (EPFL), Keith Godin of Microsoft Cloud+AI, and Ville Pulkki of Aalto University ask the question: What makes outdoor reverberation, such as in a courtyard, fundamentally different from indoors, say a conference room? It is commonly observed that outdoor spaces are less densely reflecting than indoors, but techniques to quantify this important difference do not exist. The researchers propose a novel technique for analyzing this time-evolving echo density in acoustic responses, and show that there is a marked, measurable difference in the growth rate of echo density between indoor and outdoor spaces. This growth rate is a promising new acoustic parameter for producing convincing acoustical renderings in mixed and outdoor spaces in the future.
“Immersive virtual reality systems are a delicate balance between accuracy and computational cost, between convincing audio and real-time speed,” said Keith Godin. “We have efficient systems that bring life to indoor scenes and these results will help us improve our systems for outdoor scenes,” he said. “After a decade of research, our auralization systems today can render indoor spaces convincingly in real-time,” added Nikunj Raghuvanshi. “Yet outdoor scenes are challenging and existing scientific knowledge is limited. We aimed to expand understanding to enable realistic rendering of outdoor acoustics in the future.”
In addition to the ICASSP papers, the Audio and Acoustics Group is advancing work in several other acoustic estimation and sound rendering spheres. Here we present just a few of these advances.
“If we want to take the mixed reality devices from the lab to the hallway, the street, or on the manufacturing floor, we have to meet much higher requirements for the sound capturing and speech enhancement system.” – Ivan Tashev, Partner Software Architect, Audio and Acoustics Group, Microsoft Research
Suppression of directional acoustic interference (I’ve only got ears for you)
More and more devices these days can be controlled by voice command. Personal mobile devices, such as head-mounted displays, smart watches, smartphones, and so on, can be used in any kind of acoustic environment, for example, in noisy places, such as busy streets, bars or restaurants, public transit stations, inside vehicles, in the vicinity of loud machines, or just in the midst of a gaggle of conversation. While such noisy environments severely impact the ability of speech recognizers to recognize the user’s speech correctly, there is another major problem with personal mobile devices—a device’s personal assistant should react exclusively to the user’s speech, and not to other talkers in its vicinity.
In “Directional interference suppression using a spatial relative transfer function feature”, the researchers demonstrated their spatial suppressor on the five-microphone array of Microsoft’s Hololens 2: not only the number of missed and falsely detected words (that is, word deletions and substitutions) can be reduced by 26% relative to the beamformer, but also the number of recognized words leaking in from other talkers (word insertions) can be reduced by 83% relative to the beamformer. (See Figure 1.)

Figure 1: Perceptual quality of speech (PESQ), C-weighted signal-to-noise ratio (SNRC), and word error rate (WER) of the unprocessed reference microphone, the MVDR beamformer and MVDR beamformer with proposed spatial suppressor.
Perceptual speech quality estimation using neural networks
Telephony and voice-over-IP services require capturing a user’s voice using a microphone, processing and transmitting the signal over a communication channel, and converting it back to sound at the receiving end. This process can introduce various distortions stemming from room reverberation, background noise, and audio processing artifacts. Quantifying the perceptual effect of these artifacts is crucial for monitoring and improving the perceived quality of a telecommunication service. A typical approach for determining perceptual quality is via listening tests. However, due to the cost and complexity of running subjective experiments, various metrics have been proposed as computational proxies for human listeners.
Johannes Gehrke, Ross Cutler, and Chandan Reddy from Microsoft Teams collaborated with Microsoft Research’s Audio and Acoustics Research Group, as well as with Anderson Avila of Institut national de la recherche scientifique (INRS) to develop machine-learning based models for assessing subjective speech quality. Part of the appeal of data-driven and machine-learning based approaches is that they can be re-trained to address new scenarios and applications—an important factor given the rapid advances in communication technology. In “Non-Intrusive Speech Quality Assessment Using Neural Networks” they propose deep neural network architectures to predict the Mean Opinion Score (MOS) of noisy, reverberant speech samples. The MOS is derived as the average subjective rating of each sample by human judges. The proposed models operate non-intrusively, that is, without access to a clean reference signal, to estimate how various types of signal distortions and artifacts affect the perceived speech quality. The best-performing model achieves a Pearson correlation coefficient of 0.87 and a mean-squared error of 0.15 between true and estimated MOS. These results are shown to outperform existing speech quality metrics.
«A goal in Skype/Teams is to replace our Call Quality Feedback user survey with an accurate objective audio quality estimator,” said Ross Cutler, Partner Data and Applied Scientist in Microsoft Teams. “This research gets us much closer to that goal.»
Multi-modal sensing
Audiovisual sensing modalities are essential for a variety of scenarios ranging from mixed reality to smart homes and clinical environments. Depending on the application, some modalities may be more suitable than others when considering tradeoffs between cost and resolution or between privacy and robustness. Changes in the environment, including background noise or lighting conditions, or even the proximity of objects of interest may compromise sensor data and negatively impact the performance of inference models. The combination of multiple sensor modalities allows the studying of corner cases – cases outside of normal operating parameters – including operation in direct sunlight or complete darkness, in the presence of noise, or in scenarios with strict interference or privacy requirements.
The Audio and Acoustics Research Group, led by Partner Software Architect Ivan Tashev, together with the Microsoft Research Hardware Lab, led by Principal Mechanical Engineer Patrick Therien, developed a prototype device that features four different imaging modalities: depth, RGB, heat, and ultrasound. (See Figure 2.) Depth and RGB images are obtained using Kinect for Azure. A forward-looking infrared (FLIR) sensor serves as a passive heat camera. Becky Gagnon from the Microsoft Research Hardware Lab developed custom circuitry for driving an ultrasound transducer and 8-element microphone array used for ultrasound capture. Lex Story and John Romualdez from the Microsoft Research Hardware Lab created the early version of the prototype and the initial electronics.
“The problem we address with the multimodal gesture recognition is not accuracy but robustness – each of the input modalities can be blinded in given conditions, but it is unlikely all of them to be blinded simultaneously,” said Ivan Tashev. The custom ultrasonic imaging array serves as an alternative to visual modalities to study close-proximity or privacy-sensitive scenarios, and applications where power consumption may be more critical than spatial resolution. Researcher Shuayb Zarar and Post-Doc Researcher Sebastian Braun are investigating various array designs for this purpose.
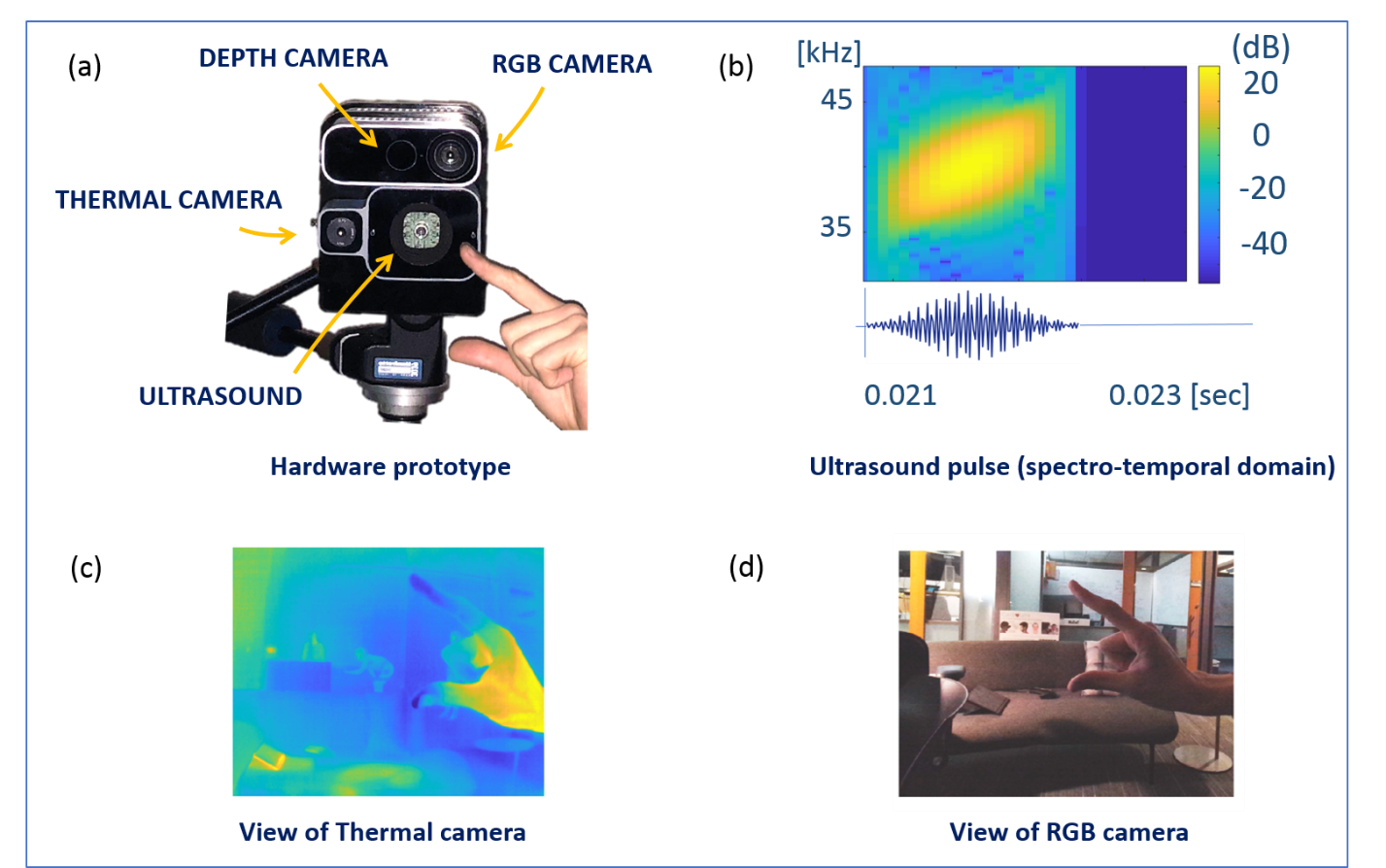
Figure 2: Multi-modal sensing.
When it comes to building a robust framework for audiovisual scene inference in practice, the availability of training data may be an important factor. Hannes Gamper studies the differences between sensing modalities in terms of their training requirements. Together with Principal Research SDE David Johnston and Researcher Dimitra Emmanouilidou, they demonstrate the nature of these challenges in the context of an interactive gesture-based game. Stop by the Microsoft booth at ICASSP and try it for yourself!