
Florence v1.0—along with recent milestones in Neural Text-to-Speech and question answering—is part of a larger Azure AI mission to provide relevant, meaningful AI solutions and services that work better for people because they better capture how people learn and work—with improved vision, knowledge understanding, and speech capabilities. At the center of these efforts is XYZ-code, a joint representation of three cognitive attributes: monolingual text (X), audio or visual sensory signals (Y), and multilingual (Z). For more information about these efforts, read the XYZ-code blog post.
Project Florence was launched by Microsoft Azure Cognitive Services in May 2020 to advance its large-scale multitask, multimodal computer vision services. Today, we’re thrilled to announce an important milestone: Florence v1.0, a computer vision foundation model that successfully scales a large variety of vision and vision-language tasks.
on-demand event

Microsoft Research Forum Episode 4
Learn about the latest multimodal AI models, advanced benchmarks for AI evaluation and model self-improvement, and an entirely new kind of computer for AI inference and hard optimization.
Florence v1.0 demonstrates superior performance on challenging tasks such as zero-shot image classification, image/text retrieval, open-set object detection, and visual question answering. We’ve achieved new state of the art with large margins on a wide range of benchmarks. Supported by Florence v1.0, we’ve also achieved the new state of the art on multiple popular vision and vision-language leaderboards, including TextCaps Challenge 2021 and Kinetics-400/Kinetics-600 action classification. Florence v1.0 is currently being deployed in Azure Cognitive Services, helping to enhance its computer vision offerings.
A holistic, people-centered approach to AI
Project Florence is part of ongoing efforts to develop AI that operates more like people do, a journey that has been challenging but exciting. We take a holistic and people-centered approach to learning and understanding by using multimodality. Our approach examines the relationship between three attributes of human cognition—monolingual text (X), audio or visual sensory cues (Y), and multilingual (Z)—and brings them together under XYZ-code, a common representation to enable AI that can speak, hear, see, and understand better. The goal is to create pretrained basic AI models that learn common representations of different modalities and support a wide range of downstream AI tasks with the ability to leverage additional external domain knowledge to underpin AI systems that interpret and interact in the world more like people do.
In helping to advance the ambitious goal of XYZ-code, the Project Florence team achieved its first milestone last year, attaining state-of-the-art (opens in new tab) performance on the nocaps benchmark (opens in new tab). Compared with image descriptions provided by people, captions for the same images generated by the AI system were more detailed and precise. This capability is a key component to the Microsoft mission of inclusive and accessible technology (opens in new tab).
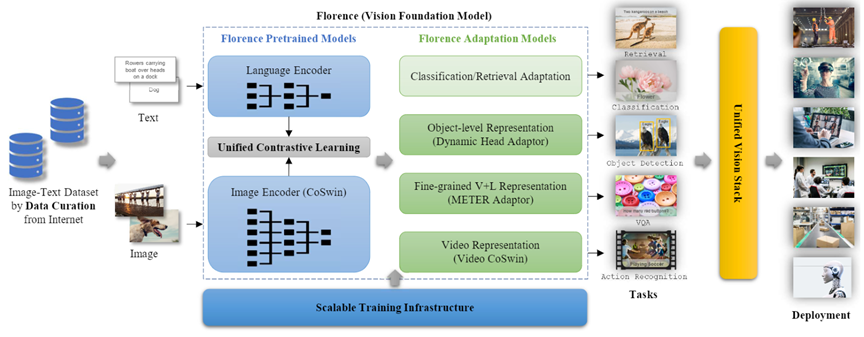
Florence v1.0: From research to application
Project Florence’s mission is to take the advancements being made in areas such as feature representation learning, transfer learning, and model architecture search and turn them into applications that can empower our partners and customers to achieve more with Azure Cognitive Services. Florence v1.0 and other AI breakthroughs achieved so far are being transferred to the cloud platform, helping to improve model quality for image captioning, tagging, and customized object detection.
The Florence image captioning model is available to customers via the computer vision offering of Azure Cognitive Services, which is part of Azure AI, and can enable developers to incorporate alt text more easily, helping them improve accessibility of their own products and services. The Florence image captioning model is also being incorporated into Seeing AI, an app that identifies text, objects, and people in a user’s surroundings, and Microsoft Word, Outlook, and PowerPoint on various platforms.
The Florence image tagging model is also available through the Azure Cognitive Services computer vision offering. It’s being incorporated into OneDrive to empower the photo search and recommendation experience for millions of users.
The Florence models can be further adapted with additional customer data through model fine-tuning. This moves us closer to our ambition of “custom vision for all”—that is, providing developers and customers with tools to build and improve models customized to meet their unique needs—where new vision objects can be recognized by the Florence model with few-shot fine-tuning.
The achievements here helped pave our way toward having AI models themselves being supplied as a service in production and contribute to many ongoing projects—from Intelligent Photo for Microsoft 365 to planogram compliance for Microsoft industry clouds to Spatial Analysis (opens in new tab) for Microsoft Dynamics 365.
We’ll have more updates in the coming months. Please check out our project page to learn more about our technology and latest advancements.
Note on Responsible AI
Microsoft is committed to the advancement and use of AI grounded in principles that put people first and benefit society. We are putting these Microsoft AI principles (opens in new tab) into practice throughout the company and strongly encourage developers to do the same. For guidance on deploying AI responsibly, visit Responsible use of AI with Cognitive Services (opens in new tab).
Acknowledgment
This research was conducted by the Project Florence team under Azure Cognitive Services, in close collaboration with the Microsoft Research Deep Learning Group. Thanks to the Office of the Chief Technology Officer, Integrated Training Platform, ONNX Runtime, and DeepSpeed teams for making this great accomplishment possible. Thanks to Luis Vargas for coordination and Microsoft Research Asia for its help and collaboration. Thanks also to Jianfeng Gao, Baining Guo, Michael Zeng, Yumao Lu, Zicheng Liu, Ce Liu, and Xuedong Huang for their leadership and support.
Related blogs and publications
- A holistic representation toward integrative AI (opens in new tab)
- Novel object captioning surpasses human performance on benchmarks (opens in new tab)
- VinVL: Advancing the state of the art for vision-language models (opens in new tab)
- VIVO: Surpassing Human Performance in Novel Object Captioning with Visual Vocabulary Pre-Training (opens in new tab)
- Apps can now narrate what they see in the world as well as people do (opens in new tab)



