
KEAR (Knowledgeable External Attention for commonsense Reasoning)—along with recent milestones in computer vision and neural text-to-speech—is part of a larger Azure AI mission to provide relevant, meaningful AI solutions and services that work better for people because they better capture how people learn and work—with improved vision, knowledge understanding, and speech capabilities. At the center of these efforts is XYZ-code, a joint representation of three cognitive attributes: monolingual text (X), audio or visual sensory signals (Y), and multilingual (Z). For more information about these efforts, read the XYZ-code blog post.
Last month, our Azure Cognitive Services (opens in new tab) team, comprising researchers and engineers with expertise in AI, achieved a groundbreaking milestone by advancing commonsense language understanding. When given a question that requires drawing on prior knowledge and five answer choices, our latest model— KEAR, Knowledgeable External Attention for commonsense Reasoning (opens in new tab)—performs better than people answering the same question, calculated as the majority vote among five individuals. KEAR reaches an accuracy of 89.4 percent on the CommonsenseQA (opens in new tab) leaderboard compared with 88.9 percent human accuracy. While the CommonsenseQA benchmark is in English, we follow a similar technique for multilingual commonsense reasoning and topped the X-CSR (opens in new tab) leaderboard.
Although recent large deep learning models trained with big data have made significant breakthroughs in natural language understanding, they still struggle with commonsense knowledge about the world, information that we, as people, have gathered in our day-to-day lives over time. Commonsense knowledge is often absent from task input but is crucial for language understanding. For example, take the question “What is a treat that your dog will enjoy?” To select an answer from the choices salad, petted, affection, bone, and lots of attention, we need to know that dogs generally enjoy food such as bones for a treat. Thus, the best answer would be “bone.” Without this external knowledge, even large-scale models may generate incorrect answers. For example, the DeBERTa language model selects “lots of attention,” which is not as good an answer as “bone.”
Spotlight: Blog post

Research Focus: Week of September 9, 2024
Investigating vulnerabilities in LLMs; A novel total-duration-aware (TDA) duration model for text-to-speech (TTS); Generative expert metric system through iterative prompt priming; Integrity protection in 5G fronthaul networks.
On the other hand, expert systems with lots of rules and domain knowledge and little data have failed to deliver their promise of AI that understands and reasons more like people do. We revisit the rules and knowledge approach and find that deep learning models and knowledge can be organically combined via an external attention mechanism to achieve breakthroughs in AI. With KEAR, we specifically equip language models with commonsense knowledge from a knowledge graph, dictionary, and publicly available machine learning data.
Given a question and five candidate answers, for the CommonsenseQA task, the KEAR model first retrieves related knowledge from a knowledge graph via entity linking, from a dictionary via word matching, and from related QA datasets via text retrieval. Then, the retrieved knowledge is concatenated with the input question and candidate answer and fed into a language model to produce a score. The candidate answer with the highest score is chosen as the output. The final submission is generated by an ensemble of 39 language models, such as DeBERTa and ELECTRA (opens in new tab), with majority voting. In this way, the KEAR model can attend to related external knowledge for effective commonsense understanding.
For example, for the aforementioned question—“What is a treat that your dog will enjoy?”—KEAR retrieves “Dog — desires — petted, affection, bone, lots of attention” from the knowledge graph ConceptNet (note that the choice “salad,” offered as one of the five options, doesn’t appear in the retrieved results); “Bone: a composite material making up the skeleton of most vertebrates” from the dictionary Wiktionary; and “What do dogs like to eat? bones” from the training data in the CommonsenseQA dataset. After concatenating the retrieved knowledge with the input, KEAR feeds it into the DeBERTa model, which selects the answer “bone.”
In applying external attention to multilingual commonsense reasoning, we translate a non-English question into English, retrieve the knowledge from various sources, and translate the knowledge text into the source language for external attention. The proposed model, Translate-Retrieve-Translate (TRT), achieved first place on both the X-CODAH and X-CSQA datasets on the X-CSR benchmark.
External attention: The benefits of looking outward
External attention is complementary to self-attention, which has been widely adopted by many of today’s AI systems, such as those using Transformers (opens in new tab). These systems rely on a large amount of diverse data to achieve impressive AI performance with huge-size models. This has prompted the recent boom of super large Transformer models, ranging from BERT (opens in new tab) with 110 million parameters to GPT-3 (opens in new tab) with 175 billion parameters. Nevertheless, numerous studies (opens in new tab) have shown that the corresponding general understanding and generation capabilities of these models are lower than that of people, especially on tasks requiring external knowledge. Moreover, the sheer size of these models poses a challenge for much of the AI community to use, study, and deploy, not to mention the significant carbon footprint created during computation.
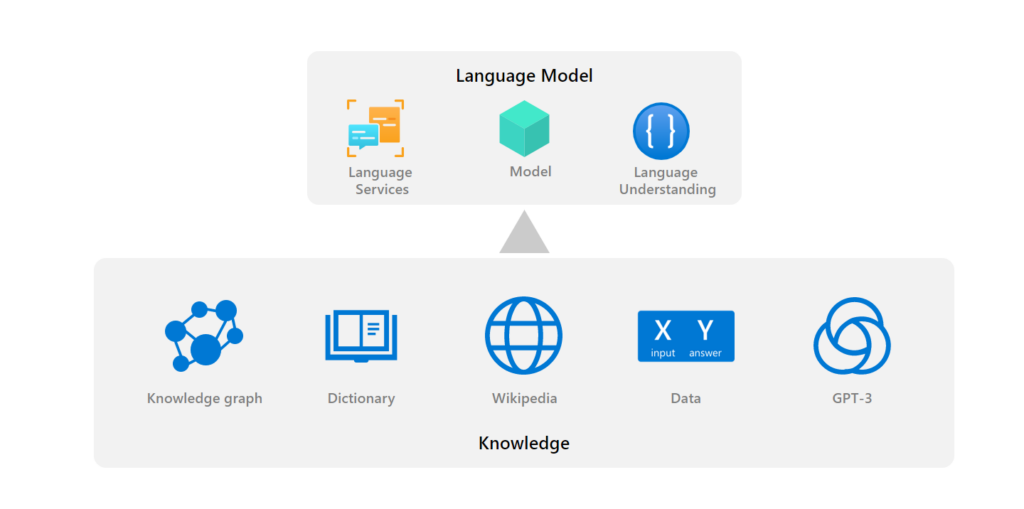
While Transformer models process input by looking inward via self-attention, external attention makes a model look outward by providing it with related context and knowledge from various sources, including knowledge graphs, dictionaries, corpora, and other language models’ output, and then letting the model conduct both self-attention to the input and external attention to the knowledge. The external information is stored in a symbolic way (for example, in plain text or knowledge graph entries) and thus enables a moderately sized Transformer model to excel in language understanding. Moreover, the text-level concatenation of input and knowledge used by KEAR incurs no change to the Transformer model architecture, enabling existing systems to be easily adapted to external attention.
Another benefit of external attention is that one could easily update the knowledge source to change the model behavior. The latest world knowledge can be fed into the model by updating the knowledge graph using recent online sources. By incorporating explicit world knowledge, the decision process of the model also becomes more transparent and explainable. These benefits can greatly facilitate the application of external attention technology to various natural language processing research projects and products. This opens the door for us to better understand the meaning of text, associate it with related knowledge, and generate more accurate output.
For more information on KEAR, check out this Tech Minutes video and our GitHub page, and for our team’s latest advancements, visit the Knowledge and Language Team page.



