
Word embeddings have had a big impact on many applications in natural language processing (NLP) and information retrieval. It is, therefore, crucial to open the blackbox and understand their meaning representation. We propose probing tasks for analyzing the meaning representation in word embeddings. Our tasks are classification based with word embeddings as the only input. We use semantic classes such as “food,” “organization,” and “animal” to define word senses and annotate words with them. By doing so, we can model ambiguous words and answer important questions including: How do word embeddings represent multiple meanings?
In the context of NLP, word embeddings are word meanings represented by vectors. That is, the word meanings have been translated into vectors of real-valued numbers. Vectors are trained based on the context that words appear in. In research to this point, there has been a question of whether or not multiple meanings can be represented by a vector space as well as how accurately these vectors retain multiple word meanings when they encounter ambiguity.
For example, if a word has multiple meanings but the usage of those meanings occurs at roughly the same rate, there is a gray area where meaning becomes difficult to identify. The question becomes, then, do vectors in this situation retain any information about the specific word meaning, do they move to another space that has no meaning at all, or do they move to an unrelated space disassociated from the specific meaning of the word?
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
In “Probing for Semantic Classes: Diagnosing the Meaning Content of Word Embeddings,” our research addresses this ambiguous space by creating a dataset called WIKI-PSE and using probing tasks to make predictions about a word embedding’s semantic class and whether or not it occurs ambiguously. We ultimately find that this process can be a good predictor of both semantic class identification and whether a word embedding is ambiguous or not.
WIKI-PSE: a resource for probing semantics in word embeddings

Figure 1: An example of how we built WIKI-PSE. The three sentences are taken from Wikipedia, and “apple” is linked to one of its Wikipedia pages in each of them.
To complete our probing tasks, we built WIKI-PSE, a Wikipedia-based resource for probing semantics in word embeddings. Wikipedia is suitable for our purposes since it contains nouns–both proper and common–disambiguated and linked to Wikipedia pages via anchor links. To find more abstract meanings than Wikipedia pages, we annotate the nouns with semantic classes. Semantic classes act as proxies for meanings. For example, “lamb” has the meanings “food” and “living thing.” WIKI-PSE has around 80,000 such words annotated with 34 semantic classes.
In Figure 1, we show how we built WIKI-PSE, using “apple” as an example.
Probing meanings in word embeddings
We investigate embeddings by using probing to ask the question: Is the information we care about available in a word embedding? Specifically, we probe for semantic classes by asking the question: Can the information, whether a word belongs to a specific semantic class, be obtained from its embedding?
We learn word embeddings by running models like word2vec on the WIKI-PSE corpus. In Figure 2, we demonstrate this process.
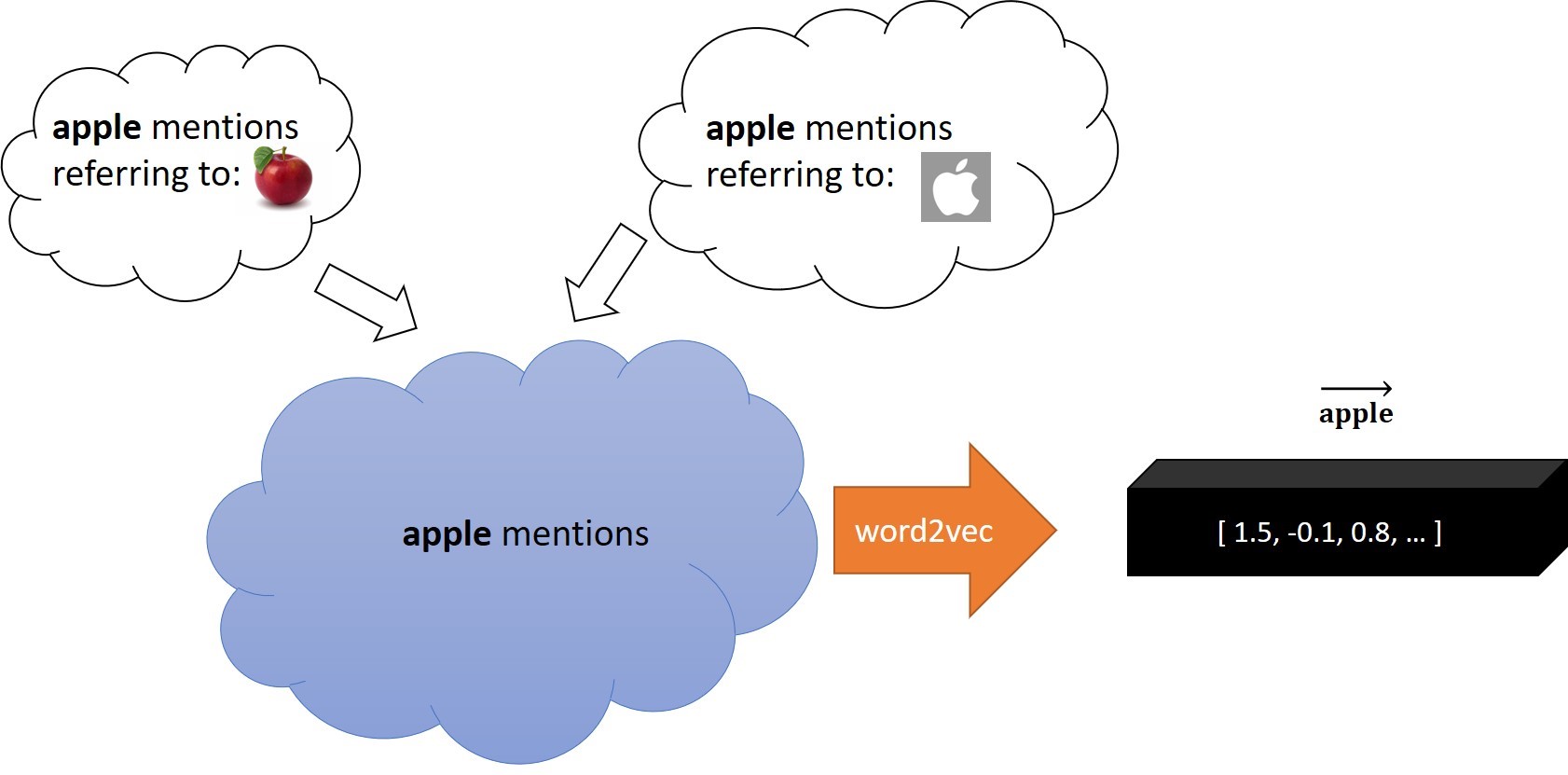
Figure 2: Learning one embedding for “apple” representing multiple meanings of it.
Next, given word embeddings, we define two probing tasks:
1. Semantic-class prediction: given an embedding, the task predicts the embedding’s different semantic classes.
2. Ambiguity prediction: given an embedding, the task predicts if the embedding belongs to an ambiguous or unambiguous word.
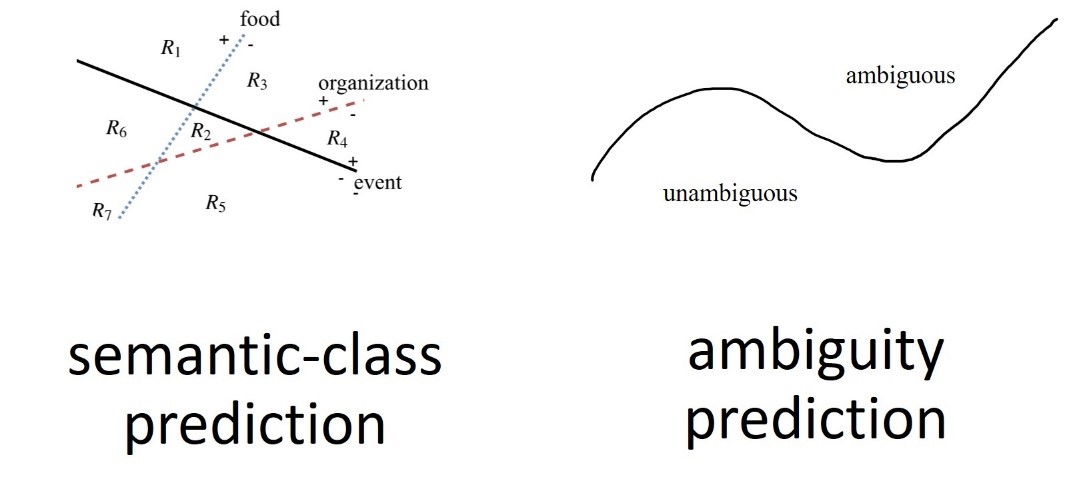
Figure 3: Our two prediction tasks for probing meanings in word embeddings
Employing the semantic-class prediction probing task
The first task is to probe for semantic classes. We train, for each semantic class, a binary multilayer perceptron (MLP) classifier (with one hidden layer) that takes an embedding as input and predicts membership in the semantic class. An ambiguous word like “apple” belongs to multiple semantic classes, so each of several different binary classifiers should diagnose it as being in its semantic class. How well this type of probing for semantic classes works in practice is one of our key questions: Can semantic classes be correctly encoded in embedding space? The results are promising.
In Figure 4, we plot our experimental results with respect to three important factors: number of semantic classes, dominance-level, frequency-level.
The performance degrades as number of semantic classes increases; however, we still get pretty high recall even when words have more than 6 semantic classes, which shows that embeddings do not have issues in representing multiple meanings in single vectors.
The performance also degrades with decreasing dominance-level. Dominance level represents the percentage of a word sense occurring in relationship to a single word. There is a sharp drop of performance at dominance-level of 0.3, emphasizing that semantic classes with low dominance-levels (<0.3) are poorly represented in word embeddings.
Frequency level indicates the occurrence of a word in the overall corpus of data. Low frequency semantic classes are not represented well, but with frequency more than 20, the recall is more than 80%.
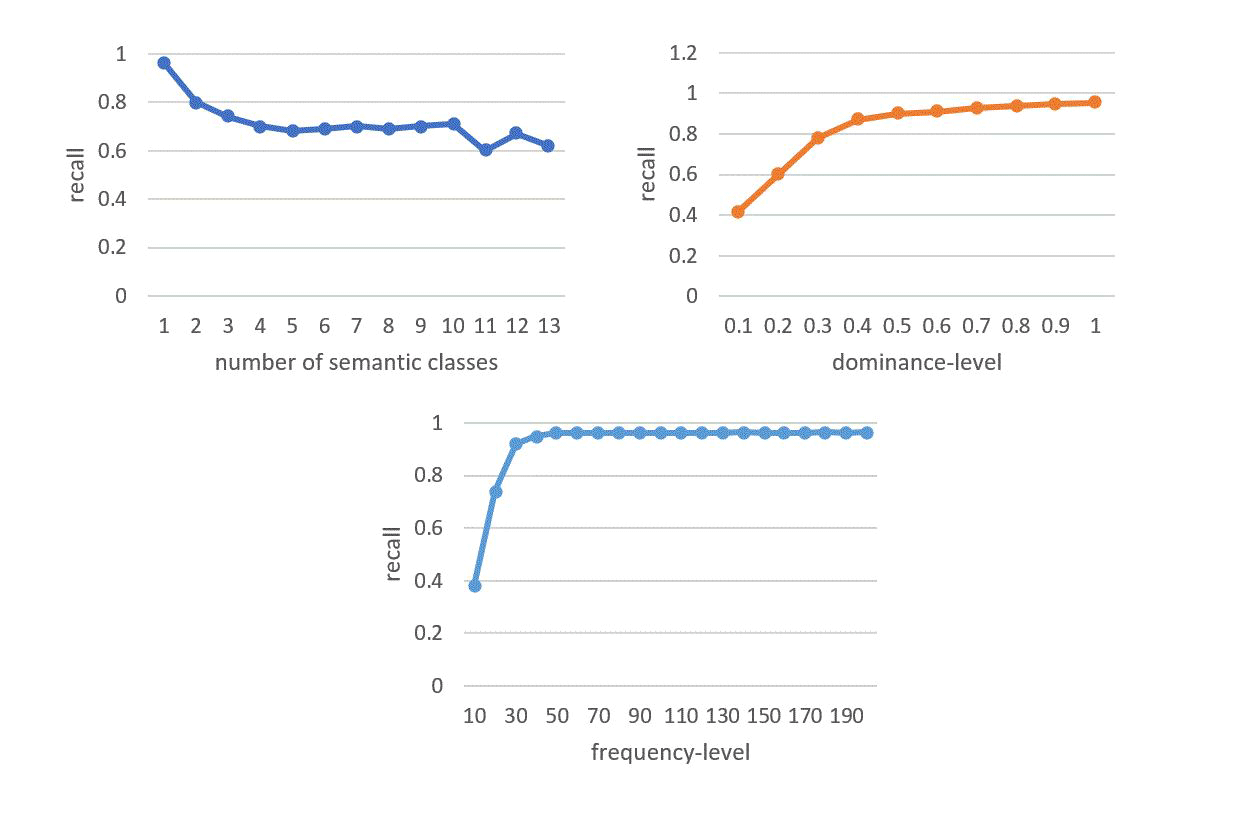
Figure 4: Results of semantic class prediction as a function of three important factors: number of semantic classes in the word, dominance-level of the semantic class in the word, and frequency-level of the word/ semantic-class.
Employing the ambiguity prediction probing task
The second probing task predicts whether an embedding represents an unambiguous (one semantic class) or an ambiguous (multiple semantic classes) word. Here, we do not look for any specific meaning in an embedding but assess whether it is an encoding of multiple different meanings or not. High accuracy of this classifier would imply that ambiguous and unambiguous words are distinguishable in the embedding space.
We train an MLP classifier to predict whether an embedding belongs to an ambiguous word or not.
The results are shown in Table 1. The MLP classifier using word embedding as input achieves very high accuracy of 81.2%. We added the result of a classifier using word frequency as input as well to make it clear that frequency is not the main distinguishing feature which might be captured by word embeddings.

Table 1: Accuracy of an MLP classifier for ambiguity prediction
In our paper, we also designed alternative ways for representation of word embeddings. In those alternatives, we first learn different embeddings for different meanings of words and then aggregate then using uniform and weighted sum. They are used as baselines to contrast the results of word embeddings learned by the typical approach.
We also evaluated our embeddings in five common NLP datasets and showed contradictory results compared to the results of probing tasks.
We aim to increase the NLP community’s understanding of how word embeddings represent meanings. By looking closely at the space in vectors where multiple meanings occur in an ambiguous way, we have learned that we can predict, with high accuracy using probing tasks, whether a word embedding represents an ambiguous or unambiguous word. We have also learned that if word meanings are frequent enough, word embedding models can capture multiple meanings in a single vector well, an idea that is reiterated through our work with both the semantic class prediction probing task and the ambiguity probing task. Further information regarding occurrences of rare senses of words can be found in our research paper.



