

Microsoft Editor provides AI-powered writing assistance to millions of users around the world. One of its features that writers of all levels and domains rely on is the grammar checker, which detects grammar errors in a user’s writing and offers suggested corrections and explanations of the detected errors.
The technology behind grammar checker has evolved significantly since the 1970s, when the first-generation tool was based on simple pattern matching. A major breakthrough occurred in 1997, when Microsoft Word 97 introduced a grammar checker that relied on a full-fledged natural language processing system (Heidorn, 2000), enabling more sophisticated and accurate error detection and correction. Another major breakthrough occurred in 2020, when Microsoft launched a neural grammar checker that leveraged deep neural networks with a novel fluency boost learning and inference mechanism, achieving state-of-the-art results on both CoNLL-2014 and JFLEG benchmark datasets[1,2]. In 2022, Microsoft released a highly optimized version of the Microsoft Editor neural grammar checker on expanded endpoints in Word Win32, Word Online, Outlook Online, and the Editor Browser Extension.
In this blog post, we will describe how we have optimized the Editor neural grammar checker model using the Aggressive Decoding algorithm pioneered by Microsoft Research (MSR) and accelerated with high performance ONNX Runtime (ORT). With the Aggressive Decoding algorithm and ORT optimizations, the server model has achieved ~200% increase in inference speed while saving two-thirds of the cost, with no loss of model prediction quality compared to the previous production model.
Microsoft Research Blog

Microsoft Research Forum Episode 3: Globally inclusive and equitable AI, new use cases for AI, and more
In the latest episode of Microsoft Research Forum, researchers explored the importance of globally inclusive and equitable AI, shared updates on AutoGen and MatterGen, presented novel use cases for AI, including industrial applications and the potential of multimodal models to improve assistive technologies.
But we did not stop there. We also implemented EdgeFormer, MSR’s cutting-edge on-device seq2seq modeling technology, to obtain a lightweight generative language model with competitive performance that can be run on a user’s device, allowing us to achieve the ultimate zero-cost-of-goods-sold (COGS) goal.
Shipping a client model offers three other key benefits in addition to achieving zero-COGS:
- Increased privacy. A client model that runs locally on the user’s device does not need to send any personal data to a remote server.
- Increased availability. A client model operates offline without relying on network connectivity, bandwidth, or server capacity.
- Reduced cost and increased scalability. Shipping a client model to a user’s device removes all the computation that a server would be required to execute, which allows us to ship to more customers.
Additionally, we leveraged GPT-3.5 (the most advanced AI model at the time) to generate high-quality training data and identify and remove low-quality training examples, leading to a boost of model performance.
Innovation: Aggressive Decoding
Behind the AI-powered grammar checker in Microsoft Editor is the transformer model, enhanced by cutting-edge research innovations[1,2,3] from MSR for grammar correction. As with most seq2seq tasks, we used autoregressive decoding for high-quality grammar correction. However, conventional autoregressive decoding is very inefficient as it cannot fully utilize modern computing devices (CPUs, GPUs) due to its low computational parallelism, which results in high model serving costs and prevents us from scaling quickly to more (web/desktop) endpoints.
To address the challenge for serving cost reduction, we adopt the latest decoding innovation, Aggressive Decoding,[3] published by MSR researchers Tao Ge and Furu Wei at ACL 2021. Unlike the previous methods that speed up inference at the cost of prediction quality drop, Aggressive Decoding is the first efficient decoding algorithm for lossless speedup of seq2seq tasks, such as grammar checking and sentence rewriting. Aggressive Decoding works for tasks whose inputs and targeted outputs are highly similar. It uses inputs as the targeted outputs and verifies them in parallel instead of decoding sequentially, one-by-one, as in conventional autoregressive decoding. As a result, it can substantially speed up the decoding process, handling trillions of requests per year, without sacrificing quality by better utilizing the powerful parallel computing capabilities of modern computing devices, such PCs with graphics processing units (GPUs).

The figure above shows how Aggressive Decoding works. If we find a bifurcation during Aggressive Decoding, we discard all the predictions after the bifurcation and re-decode them using conventional one-by-one autoregressive decoding. If we find a suffix match (i.e., some advice highlighted with the blue dotted lines) between the output and the input during one-by-one re-decoding, we switch back to Aggressive Decoding by copying the tokens (highlighted with the orange dashed lines) and following the matched tokens in the input to the decoder input by assuming they will be the same. In this way, Aggressive Decoding can guarantee that the generated tokens are identical to autoregressive greedy decoding but with much fewer decoding steps, significantly improving the decoding efficiency.
Offline evaluations
We test Aggressive Decoding in grammar correction and other text rewriting tasks, such as text simplification, with a 6+6 standard transformer as well as a transformer with deep encoder and shallow decoder. All results confirm that Aggressive Decoding can introduce a significant speedup without quality loss.
| CoNLL14 | NLCC-18 | Wikilarge | |||||
| F0.5 | speedup | F0.5 | speedup | SARI | BLEU | speedup | |
| 6+6 Transformer (beam=1) | 61.3 | 1 | 29.4 | 1 | 36.1 | 90.7 | 1 |
| 6+6 Transformer (AD) | 61.3 | 6.8 | 29.4 | 7.7 | 36.1 | 90.7 | 8 |
| CoNLL14 | ||
| F0.5 | speedup | |
| 12+2 Transformer (beam=1) | 66.4 | 1 |
| 12+2 Transformer (AD) | 66.4 | 4.2 |
And it can work even better on more powerful computing devices that excel at parallel computing (e.g., A100):
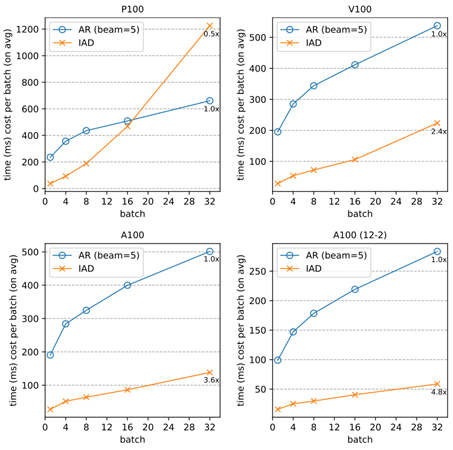
Online evaluation
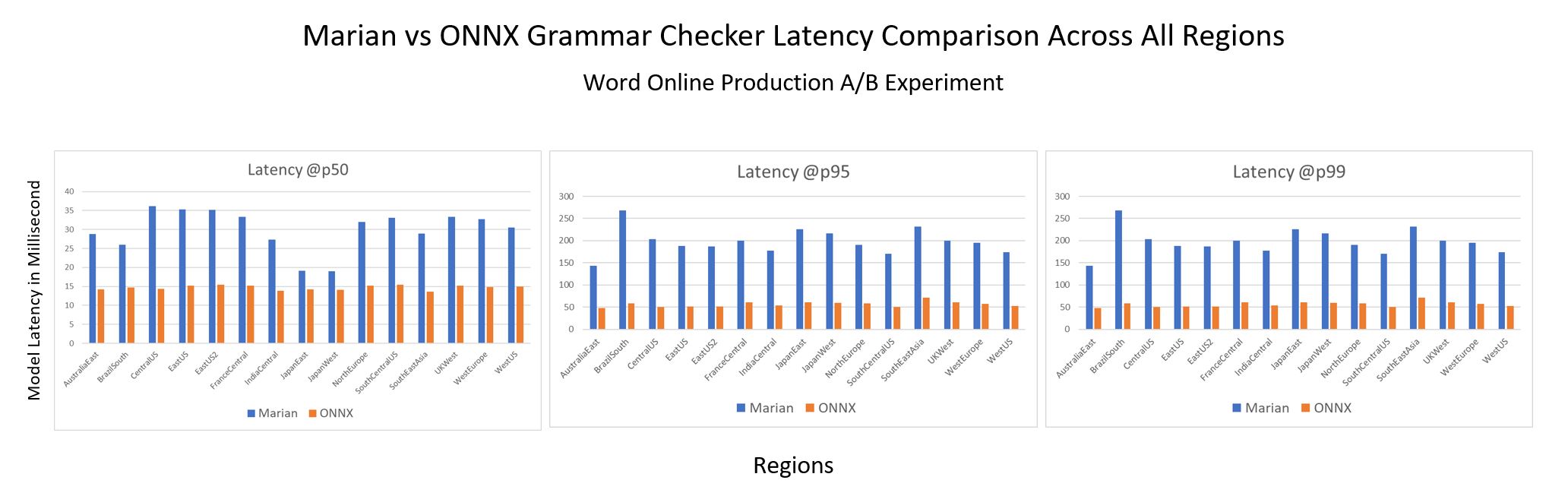
We ran an A/B experiment between a Marian server model and an equal size server model with Aggressive Decoding using ONNX Runtime. The latter shows 2x+ improvement @p50 and 3x+ improvement @p95 and @p99 over the Marian runtime, with conventional autoregressive decoding in CPU as shown in the graph below. Moreover, it offers better efficiency stability than the previous autoregressive decoding, which varies drastically in latency (approximately proportional to the sentence length), as Aggressive Decoding substantially reduces the decoding cost with only a few steps of parallel computing regardless of the sentence length. This substantial inference time speedup resulted in a two-thirds COGS reduction in the production endpoints.
Both offline/online evaluations confirm that Aggressive Decoding allows us to achieve significant COGS reduction without any loss of model prediction quality. Based on this intuition, we generalize[4] Aggressive Decoding to more general seq2seq tasks. Its high efficiency with lossless quality makes Aggressive Decoding likely to become the de facto decoding standard for seq2seq tasks and to play a vital role in the cost reduction of seq2seq model deployment.
Accelerate Grammar Checker with ONNX Runtime
ONNX Runtime (opens in new tab) is a high-performance engine, developed by Microsoft, that runs AI models across various hardware targets. A wide range of ML-powered Microsoft products leverage ONNX Runtime for inferencing performance acceleration. To further reduce the inferencing latency, the PyTorch Grammar Checker with Aggressive Decoding was exported to ONNX format using PyTorch-ONNX exporter, then inferenced with ONNX Runtime, which enables transformer optimizations and quantitation for CPU performance acceleration as well as model size reduction. A number of techniques are enabled in this end-to-end solution to run the advanced grammar checker model efficiently.
PyTorch provides a built-in function to export the PyTorch model to ONNX (opens in new tab) format with ease. To support the unique architecture of the grammar checker model, we enabled export of complex nested control flows to ONNX in the exporter. During this effort, we also extended the official ONNX specification on sequence type and operators to represent more complex scenarios (i.e., the autoregressive search algorithm). This eliminates the need to separately export model encoder and decoder components and stitch them together later with additional sequence generation implementation for production. With sequence type and operators support in PyTorch-ONNX exporter and ONNX Runtime, we were able to export one single ONNX graph, including encoder and decoder and sequence generation, which brings in both efficient computation and simpler inference logic. Furthermore, the shape type inference component of PyTorch ONNX exporter is enhanced to produce a valid ONNX model under stricter ONNX shape type constraints.
The innovative Aggressive Decoding algorithm introduced in the grammar checker model was originally implemented in Fairseq. To make it ONNX compatible, we reimplemented this Aggressive Decoding algorithm in HuggingFace for easy exporting. When diving into the implementation, we identified certain components that are not directly supported in the ONNX standard operator set (e.g., bifurcation detector). There are two approaches for exporting unsupported operators to ONNX and running with ONNX Runtime. We can either create a graph composing several standard ONNX operators that have equivalent semantics or implement a custom operator in ONNX Runtime with more efficient implementation. ONNX Runtime custom operator capability (opens in new tab) allows users to implement their own operators to run within ONNX Runtime with more flexibility. This is a tradeoff between implementation cost and performance. Considering the complexity of these components, the composition of standard ONNX operators might become a performance bottleneck. Hence, we introduced custom operators in ONNX Runtime to represent these components.
ONNX Runtime enables transformer optimizations (opens in new tab) and quantization, (opens in new tab) showing very promising performance gain on both CPU and GPU. We further enhanced encoder attention fusion and decoder reshape fusion for the grammar checker model. Another big challenge of supporting this model is multiple model subgraphs. We implemented subgraphs fusion in ONNX Runtime transformers optimizer and quantization tool. ONNX Runtime Quantization was applied to the whole model, further improving throughput and latency.
Quality Enhancement by GPT-3.5 LLMs
To further improve the precision and recall of the models in production, we employ the powerful GPT-3.5 as the teacher model. Specifically, the GPT-3.5 model works in the following two ways to help improve the result:
- Training data augmentation: We fine-tune the GPT-3.5 model and use it to generate labels for massive unannotated texts. The annotations obtained are verified to be of high quality and can be used as augmented training data to enhance the performance of our model.
- Training data cleaning: We leverage the powerful zero/few-shot capability of GPT-3.5 to distinguish between high-quality and low-quality training examples. The annotations of the identified low-quality examples are then regenerated by the GPT-3.5 model, resulting in a cleaner and higher-quality training set, which directly enhances the performance of our model.
EdgeFormer: Cost-effective parameterization for on-device seq2seq modeling
In recent years, the computational power of client devices has greatly increased, allowing for the use of deep neural networks to achieve the ultimate zero-COGS goal. However, running generative language models on these devices still poses a significant challenge, as the memory efficiency of these models must be strictly controlled. The traditional methods of compression used for neural networks in natural language understanding are often not applicable when it comes to generative language models.
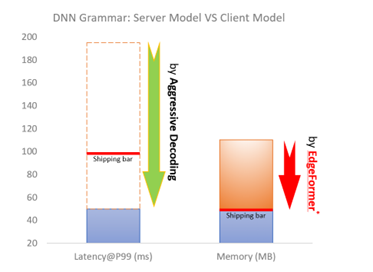
To ship a client grammar model, the model should be highly efficient (e.g., within 100ms latency), which has already been solved by Aggressive Decoding, mentioned earlier. Moreover, the client model must be memory-efficient (e.g., within a 50MB RAM footprint), which is the main bottleneck for a powerful (generative) transformer model (usually over 50 million parameters) to run on a client device.
To address this challenge, we introduce EdgeFormer[6], a cutting-edge on-device seq2seq modeling technology for obtaining lightweight generative language models with competitive performance that can be easily run on a user’s computer.
The main idea of EdgeFormer is two principles, which we proposed for cost-effective parameterization:
- Encoder-favored parameterization
- Load-balanced parameterization
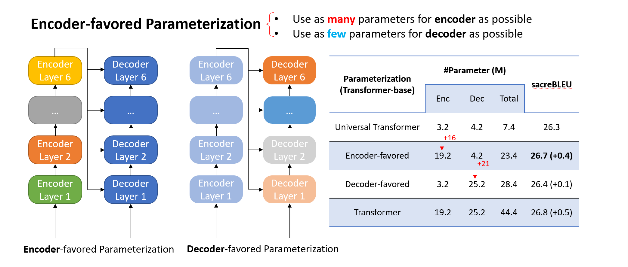
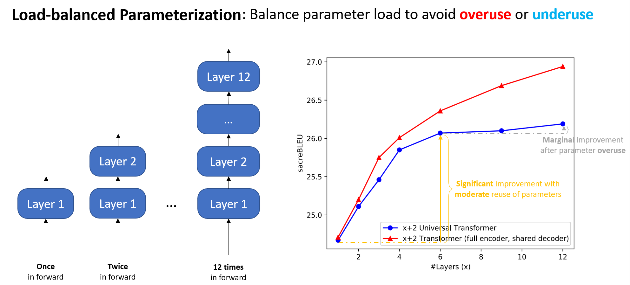
We designed EdgeFormer with the above principles of cost-effective parameterization, allowing each parameter to be utilized to its maximum potential, which achieves competitive results despite the stringent computational and memory constraints of client devices.
Based on EdgeFormer, we further propose EdgeLM (opens in new tab) – the pretrained version of EdgeFormer, which is the first publicly available pretrained on-device seq2seq model that can be easily fine-tuned for seq2seq tasks with strong results. EdgeLM serves as the foundation model of the grammar client model to realize the zero-COGS goal, which achieves over 5x model size compression with minimal quality loss compared to the server model.
Inference cost reduction to empower client-device deployment
Model deployment on client devices has strict requirements on hardware usage, such as memory and disk size, to avoid interference with other user applications. ONNX Runtime shows advantages for on-device deployment along with its lightweight engine and comprehensive client-inference focused solutions, such as ONNX Runtime quantization and ONNX Runtime extensions. In addition, to maintain service quality while meeting shipping requirements, MSR introduced a series of optimization techniques, including system-aware model optimization, model metadata simplification, and deferred parameter loading as well as customized quantization strategy. Based on the EdgeFormer modeling, these system optimizations can further reduce the memory cost by 2.7x, without sacrificing model performance.
We will elaborate on each one in the following sections:
System-aware model optimization. As the model is represented as a dataflow graph, the major memory cost for this model is from the many subgraphs generated. As shown in the figure below, a branch in the PyTorch code is mapped as a subgraph. Therefore, we optimize the model implementation to reduce the usage of branch instructions. Particularly, we leverage greedy search as the decoder search algorithm, as beam search contains more branch instructions. The usage of this method can reduce memory cost by 38%.
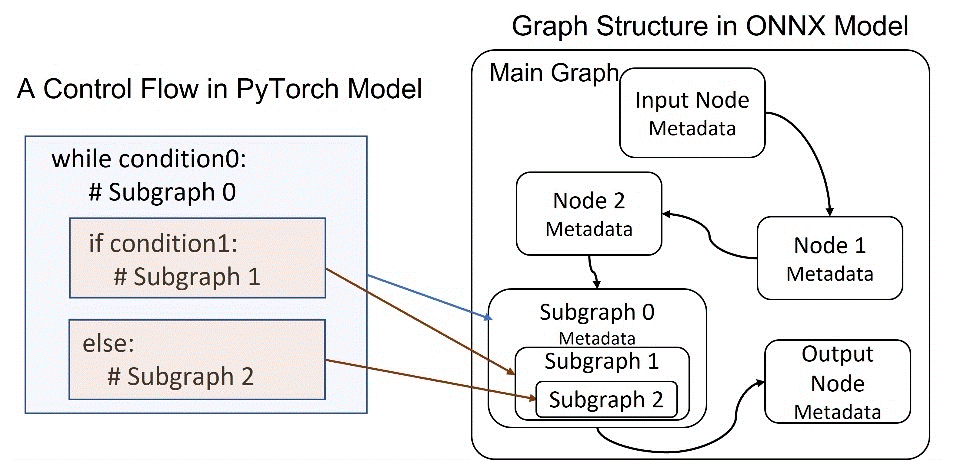
Model metadata simplification. Also shown in the figure above, the model contains a lot of metadata that consumes memory, such as the node name and type, input and output, and parameters. To reduce the cost, we simplify the metadata to keep only the basic required information for inference. For example, the node name is simplified from a long string to an index. Besides that, we optimize the model graph implementation in ONNX Runtime to keep just one copy of the metadata, rather than duplicating all the available metadata each time a subgraph is generated.
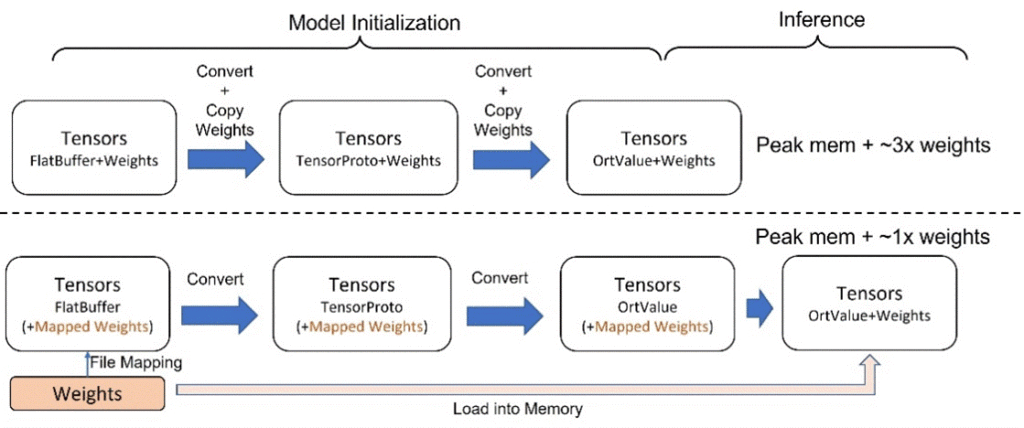
Deferred weight loading in ONNX Runtime. Current model files include both the model graphs and weights, which are then loaded into memory together during model initialization. However, this increases memory usage as shown in the figure below, because the weights will be copied repeatedly during model graph parsing and conversion. To avoid this, we save model graphs and weights separately. During initialization in ONNX Runtime, only the graphs are loaded into memory for actual parsing and conversion. The weights, on the other hand, still reside on disk with only the pointer kept in memory, through file mapping. The actual weight loading to memory will be deferred until the model inference. This technique can reduce the peak memory cost by 50%.
ONNX Runtime quantization and ONNX Runtime extensions. Quantization is a well-known model compression technique that brings in both performance acceleration and model size reduction while sacrificing model accuracy. ONNX Runtime Quantization offers diverse tuning knobs to allow us to apply customized quantization strategy. Specifically, we customize the strategy as post-training, dynamic, UINT8, per-channel and all-operator quantization, for this model for minimum accuracy impact. Onnxruntime-extensions (opens in new tab) provides a set of ONNX Runtime custom operators to support the common pre- and post-processing operators for vision, text, and natural language processing models. With it, the pre- and post-processing for this model, including tokenization, string manipulation, and so on, can be integrated into one self-contained ONNX model file, leading to improved performance, simplified deployment, reduced memory usage, and better portability.
Conclusion
In this blog post, we have presented how we leveraged the cutting-edge research innovations from MSR and ONNX Runtime to optimize the server grammar checker model and achieve the ultimate zero-COGS goal with the client grammar checker model. The server model has achieved ~200% increase in inference speed while saving two-thirds of the cost, with no loss of model prediction quality. The client model has achieved over 5x model size compression with minimal quality loss compared to the server model. These optimizations have enabled us to scale quickly to more web and desktop endpoints and provide AI-powered writing assistance to millions of users around the world.
The innovation shared in this blog post is just the first milestone in our long-term continuous effort of COGS reduction for generative AI models. Our proposed approach is not limited to accelerating the neural grammar checker; it can be easily generalized and applied more broadly to scenarios such as abstractive summarization, translation, or search engines to accelerate large language models for COGS reduction[5,8], which is critical not only for Microsoft but also for the entire industry in the artificial general intelligence (AGI) era.
Reference
[1] Tao Ge, Furu Wei, Ming Zhou: Fluency Boost Learning and Inference for Neural Grammatical Error Correction. In ACL 2018.
[2] Tao Ge, Furu Wei, Ming Zhou: Reaching Human-level Performance in Automatic Grammatical Error Correction: An Empirical Study. https://arxiv.org/abs/1807.01270 (opens in new tab)
[3] Xin Sun, Tao Ge, Shuming Ma, Jingjing Li, Furu Wei, Houfeng Wang: A Unified Strategy for Multilingual Grammatical Error Correction with Pre-trained Cross-lingual Language Model. In IJCAI 2022.
[4] Xin Sun, Tao Ge, Furu Wei, Houfeng Wang: Instantaneous Grammatical Error Correction with Shallow Aggressive Decoding. In ACL 2021.
[5] Tao Ge, Heming Xia, Xin Sun, Si-Qing Chen, Furu Wei: Lossless Acceleration for Seq2seq Generation with Aggressive Decoding. https://arxiv.org/pdf/2205.10350.pdf (opens in new tab)
[6] Tao Ge, Si-Qing Chen, Furu Wei: EdgeFormer: A Parameter-efficient Transformer for On-device Seq2seq Generation. In EMNLP 2022.
[7] Heidorn, George. “Intelligent Writing Assistance.” Handbook of Natural Language Processing. Robert Dale, Hermann L. Moisl, and H. L. Somers, editors. New York: Marcel Dekker, 2000: 181-207.
[8] Nan Yang, Tao Ge, Liang Wang, Binxing Jiao, Daxin Jiang, Linjun Yang, Rangan Majumder, Furu Wei: Inference with Reference: Lossless Acceleration of Large Language Models. https://arxiv.org/abs/2304.04487 (opens in new tab)



