
The natural association between visual observations and their corresponding sounds has exhibited powerful self-supervision signals for learning video representations (opens in new tab), which makes the ever-growing amount of online video an attractive data source for self-supervised learning. However, online videos often provide imperfectly aligned audio-visual signals because of overdubbed audio; models trained on uncurated videos have been shown to learn suboptimal representations (opens in new tab) due to the misalignment issues. Therefore, existing approaches rely almost exclusively on manually curated datasets (opens in new tab) with a predetermined taxonomy of semantic concepts (opens in new tab), where there is a high chance of audio-visual correspondence. This severely limits the utility of online videos for self-supervised learning, which begs the question: How can we fully leverage online videos without extensive human effort?

Today, in collaboration with Seoul National University and NVIDIA Research, we are thrilled to release an automatic dataset curation pipeline and the largest video dataset for self-supervised audio-visual learning, dubbed ACAV100M (/ˈärˌkīv/; automatically curated audio-visual dataset). Our dataset is constructed from uncurated online videos at an unprecedented scale: We processed 140 million full-length videos (total duration 1,030 years, consuming 2 petabytes of storage) and reduced it to 100 million clips (10 seconds each, 31 years in total) that exhibit the highest audio-visual correspondence. This is the largest video dataset in the current literature and is orders of magnitude larger than existing datasets for audio-visual learning. We are also releasing the code, so that the community can build upon our pipeline to create other datasets for self-supervised learning. We provide full details of the automatic dataset curation pipeline in our ICCV 2021 paper “ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning.”
Posing dataset creation as subset selection with maximum mutual information
We formulate a constrained optimization problem where the objective is to find a subset that maximizes the total mutual information between audio and visual channels in the videos. Mutual information (MI) tells us how much the knowledge of one variable reduces uncertainty about the other. A subset with the maximum MI is therefore likely to have a high portion of videos with audio-visual correspondence, which is necessary for self-supervised learning.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
One could estimate audio-visual MI per video, independently of each other, and create a subset that provides the maximum MI. This can be done, for example, via contrastive learning (opens in new tab) using co-occurring audio-visual signals as positive pairs. Unfortunately, we encounter the “chicken-and-egg” problem: contrastive learning requires a dataset from which we can reliably construct the positive pairs, but that is exactly what we set out to find in the first place! The literature already suggests that models trained on uncurated videos suffer from suboptimal representations due to misaligned audio-visual signals (opens in new tab).
In this work, rather than estimating MI at the instance level, we turn to set-based MI estimation by Banerjee et al. (2005) (opens in new tab) that quantifies the information shared by two clustering assignments of a dataset. Given a candidate subset, we cluster the videos with respect to audio and visual signals, respectively, and measure the MI from a contingency table that encodes the overlap between audio and visual clusters. We found this set-based approach to be more robust to real-world noise, which helps it create datasets with a higher audio-visual correspondence than instance-based MI estimation.
Finding a global solution to our constrained optimization problem is NP-hard; we implement a greedy solution widely used in the submodular optimization literature. Specifically, we use the batch greedy algorithm of Chen and Krause (2013) that randomly samples a batch from the remaining pool of candidates and searches for the next element to be added to the solution only within that batch. This batch trick reduces the complexity from quadratic to linear in terms of the population size. We implemented several other techniques to make our whole pipeline scalable to hundreds of millions of video clips. We provide the full details of the pipeline in our paper.
Evaluating the utility of datasets for self-supervised audio-visual learning
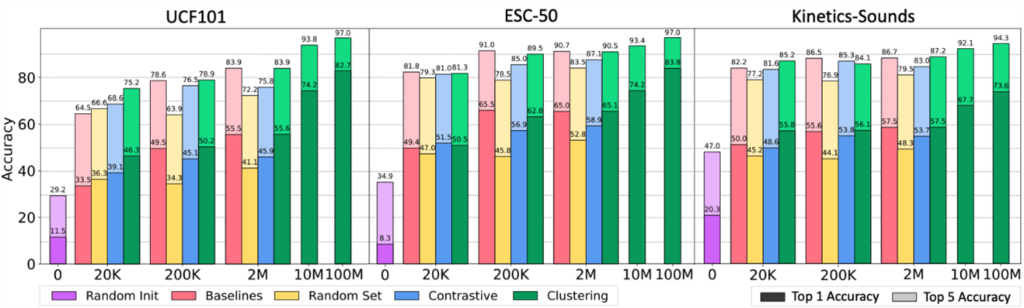
To evaluate the utility of our dataset in self-supervised audio-visual learning, we compare our dataset with popular video datasets widely used in the self-supervised learning literature. We pretrain identical models on different datasets via contrastive learning (opens in new tab) and perform linear evaluation on standard benchmarks. The figure above shows that models pretrained on our datasets (“clustering”, green bars) perform as well as, and sometimes even outperform, the models pretrained on existing datasets (“baselines”, pink bars) that involve human annotation or manual verification. This shows that datasets created by our approach indeed provide audio-visual correspondence necessary for self-supervised approaches. We provide in-depth analyses of the results in our paper (opens in new tab).
Looking forward
Large-scale datasets are the cornerstone of self-supervised representation learning. We hope that the video understanding community will find value in our ACAV100M (opens in new tab) dataset, which we release in the form of public URLs so anyone can access the data as long as the videos are still available online. We are open sourcing the dataset creation pipeline (opens in new tab), which can be applied to other scenarios involving different modalities such as vision and language. We look forward to seeing rapid development in learning from unlabeled videos with our new dataset and tools.



