
If you were asked to draw a picture of several people in ski gear, standing in the snow, chances are you’d start with an outline of three or four people reasonably positioned in the center of the canvas, then sketch in the skis under their feet. Though it was not specified, you might decide to add a backpack to each of the skiers to jibe with expectations of what skiers would be sporting. Finally, you’d carefully fill in the details, perhaps painting their clothes blue, scarves pink, all against a white background, rendering these people more realistic and ensuring that their surroundings match the description. Finally, to make the scene more vivid, you might even sketch in some brown stones protruding through the snow to suggest that these skiers are in the mountains.
Now there’s a bot that can do all that.
Spotlight: On-demand video

AI Explainer: Foundation models and the next era of AI
Explore how the transformer architecture, larger models and more data, and in-context learning have helped advance AI from perception to creation.
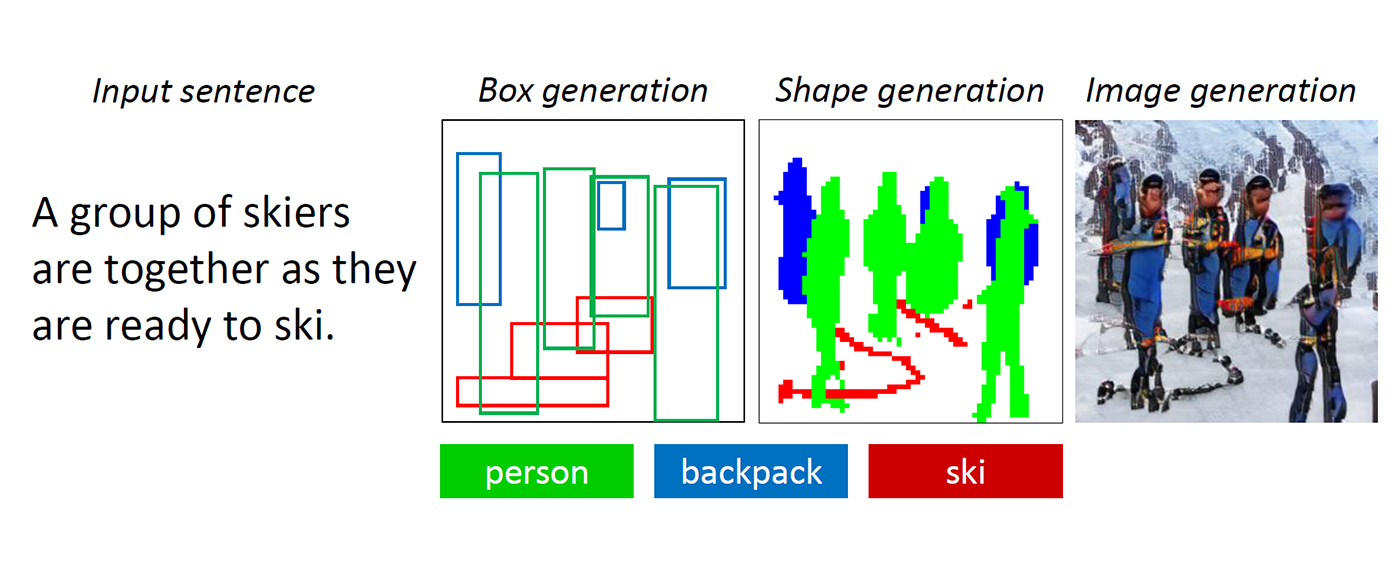
New AI technology being developed at Microsoft Research AI can understand a natural language description, sketch a layout of the image, synthesize the image, and then refine details based on the layout and the individual words provided. In other words, this bot can generate images from caption-like text descriptions of everyday scenes. This deliberate mechanism produced a significant boost in generated image quality compared to the earlier state-of-the-art technique for text-to-image generation for complicated everyday scenes, according to results on industry standard tests reported in “Object-driven Text-to-Image Synthesis via Adversarial Training (opens in new tab)”, to be published this month in Long Beach, California at the 2019 IEEE Conference on Computer Vision and Pattern Recognition (opens in new tab) (CVPR 2019). This is a collaboration project among Pengchuan Zhang (opens in new tab), Qiuyuan Huang (opens in new tab) and Jianfeng Gao (opens in new tab) of Microsoft Research AI (opens in new tab), Lei Zhang (opens in new tab) of Microsoft, Xiaodong He of JD AI Research, and Wenbo Li and Siwei Lyu of the University at Albany, SUNY (while Wenbo Li worked as an intern at Microsoft Research AI).
There are two main challenges intrinsic to the description-based drawing bot problem. The first is that many kinds of objects can appear in everyday scenes and the bot should be able to understand and draw all of them. Previous text-to-image generation methods use image-caption pairs that only provide a very coarse-grained supervising signal for generating individual objects, limiting their object generation quality. In this new technology, the researchers make use of the COCO dataset that contains labels and segmentation maps for 1.5 million object instances across 80 common object classes, enabling the bot to learn both concept and appearance of these objects. This fine-grained supervised signal for object generation significantly improves generation quality for these common object classes.
The second challenge lies in the understanding and generation of the relationships between multiple objects in one scene. Great success has been achieved in generating images that only contain one main object for several specific domains, such as faces, birds, and common objects. However, generating more complex scenes containing multiple objects with semantically meaningful relationships across those objects remains a significant challenge in text-to-image generation technology. This new drawing bot learned to generate layout of objects from co-occurrence patterns in the COCO dataset to then generate an image conditioned on the pre-generated layout.
Object-driven attentive image generation
At the core of Microsoft Research AI’s drawing bot is a technology known as the Generative Adversarial Network, or GAN. The GAN consists of two machine learning models—a generator that generates images from text descriptions, and a discriminator that uses text descriptions to judge the authenticity of generated images. The generator attempts to get fake pictures past the discriminator; the discriminator on the other hand never wants to be fooled. Working together, the discriminator pushes the generator toward perfection.
The drawing bot was trained on a dataset of 100,000 images, each with salient object labels and segmentation maps and five different captions, allowing the models to conceive individual objects and semantic relations between objects. The GAN, for example, learns how a dog should look like when comparing images with and without dog descriptions.

(opens in new tab) Figure 1: A complex scene with multiple objects and relationships.
GANs work well when generating images containing only one salient object, such as a human face, birds or dogs, but quality stagnates with more complex everyday scenes, such a scene described as “A woman wearing a helmet is riding a horse” (see Figure 1.) This is because such scenes contain multiple objects (woman, helmet, horse) and rich semantic relations between them (woman wear helmet, woman ride horse). The bot first must understand these concepts and place them in the image with a meaningful layout. After that, a more supervised signal capable of teaching the object generation and the layout generation is required to fulfill this language-understanding-and-image-generation task.
As humans draw these complicated scenes, we first decide on the main objects to draw and make a layout by placing bounding boxes for these objects on the canvas. Then we focus on each object, by repeatedly checking the corresponding words that describe this object. To capture this human trait, the researchers created what they called an Object-driven attentive GAN, or ObjGAN, to mathematically model the human behavior of object centered attention. ObjGAN does this by breaking up the input text into individual words and matching those words to specific objects in the image.
Humans typically check two aspects to refine the drawing: the realism of individual objects and the quality of image patches. ObjGAN mimics this behavior as well by introducing two discriminators—one object-wise discriminator and one patch-wise discriminator. The object-wise discriminator is trying to determine whether the generated object is realistic or not and whether the object is consistent with the sentence description. The patch-wise discriminator is trying to determine whether this patch is realistic or not and whether this patch is consistent with the sentence description.
Related work: Story visualization
State-of-the-art text-to-image generation models can generate realistic bird images based on a single-sentence description. However, text-to-image generation can go far beyond synthesis of a single image based on one sentence. In “StoryGAN: A Sequential Conditional GAN for Story Visualization (opens in new tab)”, Jianfeng Gao (opens in new tab) of Microsoft Research, along with Zhe Gan, Jingjing Liu and Yu Cheng of Microsoft Dynamics 365 AI Research, Yitong Li, David Carlson and Lawrence Carin of Duke University, Yelong Shen of Tencent AI Research and Yuexin Wu of Carnegie Mellon University go a step further and propose a new task, called Story Visualization. Given a multi-sentence paragraph, a full story can be visualized, generating a sequence of images, one for each sentence. This is a challenging task, as the drawing bot is not only required to imagine a scenario that fits the story, model the interactions between different characters appearing in the story, but it also must be able to maintain global consistency across dynamic scenes and characters. This challenge has not been addressed by any single image or video generation methods.
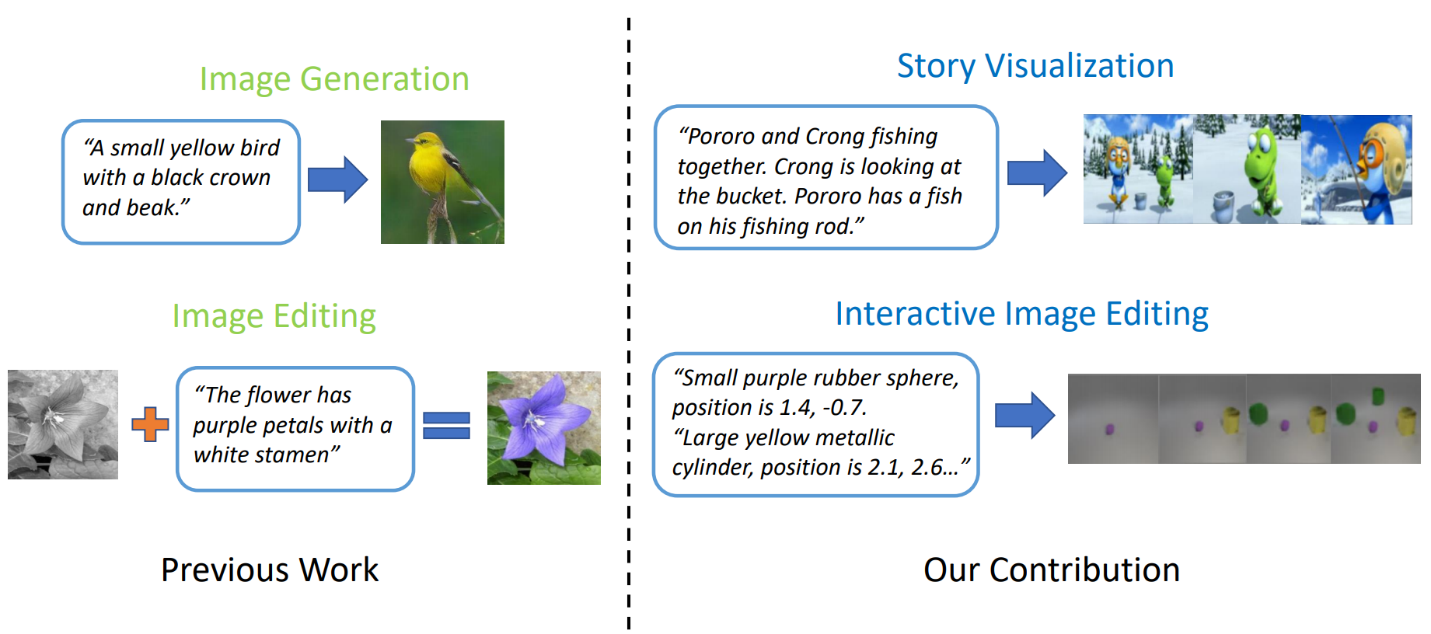
(opens in new tab) Figure 2: Story visualization vs. simple image generation.
The researchers came up with a new story-to-image-sequence generation model, StoryGAN, based on the sequential conditional GAN framework. This model is unique in that it consists of a deep Context Encoder that dynamically tracks the story flow, and two discriminators at the story and image levels to enhance the image quality and the consistency of the generated sequences. StoryGAN also can be naturally extended for interactive image editing, where an input image can be edited sequentially based on the text instructions. In this case, a sequence of user instructions will serve as the “story” input. Accordingly, the researchers modified existing datasets to create the CLEVR-SV and Pororo-SV datasets, as shown in the Figure 2.
Practical applications – a real story
Text-to-image generation technology could find practical applications acting as a sort of sketch assistant to painters and interior designers, or as a tool for voice-activated photo editing. With more computing power, the researchers imagine the technology generating animated films based on screenplays, augmenting the work that animated filmmakers do by removing some of the manual labor involved.
For now, the generated images are still far away from photo realistic. Individual objects almost always reveal flaws, such as blurred faces and or buses with distorted shapes. These flaws are a clear indication that a computer, not a human, created the images. Nevertheless, the quality of the ObjGAN images is significantly better than previous best-in-class GAN images and serve as a milestone on the road toward a generic, human-like intelligence that augments human capabilities.
For AIs and humans to share the same world, each must have a way to interact with the other. Language and vision are the two most important modalities for humans and machines to interact with each other. Text-to-image generation is one important task that advances language-vision multi-modal intelligence research.
The researchers who created this exciting work look forward to sharing these findings with attendees at CVPR in Long Beach and hearing what you think. In the meantime, please feel free to check out their open-source code for ObjGAN (opens in new tab) and StoryGAN (opens in new tab) on GitHub



