

Recently, Microsoft Research Montréal open sourced a phonetic matching component used previously in Maluuba Inc.’s natural language understanding platform. The library contains string comparison utilities that operate on a phoneme level as opposed to a character level. This allows upstream systems to utilize personalized and contextual information that the Automatic Speech Recognition (ASR) systems may not have access to, in order to correct the ASR. This post will shed light on what phonetic matching is used for and take a closer look at its components. The repository can be found on GitHub at Microsoft/PhoneticMatching (opens in new tab).
Phonetic matching is useful, how?
There has been a paradigm shift in user interfaces. More and more voice interactions are available through phones, wearables, vehicles, and even virtual personal assistants at the home. Reasons for voice interaction are many – the convenience of being able to speak naturally, remaining hands-free and even eyes-free, or in cases when there is no space on a device for a physical input such as a keyboard or buttons. These systems tend to use ASR to transform the voice input into text, and then the rest of the pipeline works off of that text. However, just as when we mishear what people say sometimes in everyday conversation, ASR is not perfect all the time. Noisy environments, using an offline ASR model when the online model is not available/reachable, and speaking in a different language, or even encountering a different accent than what the model was designed to support all can contribute to errors in recognition accuracy that propagate downstream. Moreover, ASR tends to have trouble with out-of-vocabulary words, such as proper nouns like place names, people’s names, or nomenclature very specific to an application or domain. This is where phonetic matching can come in handy. If there is a known list of choices to make, chances are the ASR might not pick up exactly what was said or exactly how the choice was written. But the result still retains useful information; whatever the ASR returned probably sounds similar to what the intended choice was. Therefore, comparisons with phonetics can yield closer matches than with string characters.
Spotlight: Blog post

Research Focus: Week of September 9, 2024
Investigating vulnerabilities in LLMs; A novel total-duration-aware (TDA) duration model for text-to-speech (TTS); Generative expert metric system through iterative prompt priming; Integrity protection in 5G fronthaul networks.
For example, an English speaker with their en-US locale smartphone might wish to call one of their contacts who does not have an English name. Saying, “Call Sanjay Nathwani.” could yield something closer to “Call Sunday not funny.”
There are some situations in which there would be less benefit from phonetic matching. If the user input is from a keyboard, mistakes are often the result of hitting the wrong key that is in proximity to the intended key. This produces words that could sound drastically different, but that evaluated from a character basis level are quite similar. Another shortfall would be if the recognition-to-intent of a system were end-to-end, meaning if the model took the user’s voice input and outputted the intent classification. There is no intermediate text of what the user said, and therefore no opportunity for a third party to correct any part of this system.
From Text to Sounds
The first step in a phonetic matching system is to transform text into a phonetic representation. A general purpose representation used is the International Phonetic Alphabet (opens in new tab) (IPA). Others exist, such as ARPAbet, but it is limited to representing sounds found in American English. Implementations of this task can be found in how speech synthesis is done, such as a text-to-speech (TTS) system. Before the wave form of the sounds is produced, some TTS systems produce the intermediate phonemes, that is, the phonetic representation. This process is specifically referred to as grapheme-to-phonemes (G2P), grapheme meaning the string characters themselves and phoneme meaning a unit of sound in a particular language.
To give an idea what this notation looks like, “John Smith” can become “dʒɑnsmɪθ”. These symbols encapsulate the voice intensity, vowels, and consonants’ manner and place of articulation, whether it forms a syllable, and so on. In other words, phonemes are language dependent, even though the notation used is IPA, representing a phone, a unit of sound. This stems from not all string of characters having the same pronunciations or reading the same; both depend on the language. Therefore, it is important that a phonetic matching system match the language of the user, or be capable of considering a wider range of possible pronunciations.
Sounding Distances
Given two pronunciations (list phones in IPA representations), how similar are they? Given a third, how similar or different is it from the preceding two? Generally, what is the best way to measure the distance between pronunciations that gives useful results, such as forming a metric space? Luckily, the work done in PatPho: A phonological pattern generator for neural networks (opens in new tab) gives a mapping of phonemes to a 3D vector embedding for English words. The idea is to encode voice intensity and articulation and assign numerical values scaled between 0 and 1, such that the closer the numerical values are, the more similar the articulatory features should be. Tables of these values can be found in the PatPho paper. It is worth pointing out that the values assigned are dependent on the English language—some features emphasize what sounds are important to distinguish or lack of features for the inconsequential. However, similar techniques can be used for other languages.
It is now easy to compare these vector embeddings by using Euclidean distance (opens in new tab). To put it all together, comparing two pronunciations (now list of 3D vector embeddings) can be done with Levenshtein distance (opens in new tab), or a similar technique. The cost substitution is the distance between the vector embeddings, and the cost of insertion/deletion is the cost of a general phoneme—more if it is syllabic, less otherwise.
Note that the distance function satisfies a metric (opens in new tab), that is:
Non-negativity: Distances are always non-negative.
1. d(x,y) >= 0
Identity of indiscernibles: The distance is 0 if and only if the pair is considered equal.
2. d(x,y) = 0 if x=y
Symmetry: There are no one-way directional distances.
3. d(x,y) = d(y,x)
Triangle inequality: Essentially, the shortest path is a straight line.
4. d(x,z) <= d(x,y) + d(y,z)
This allows the use of accelerated data structures to improve the query time of questions, such as what is the nearest pronunciation to a target pronunciation. One such structure used is a vantage-point tree (opens in new tab). After the tree is built, this allows finding the nearest distance without having to compare the target with all points in the tree.
Domain Specific Applications
The GitHub repository provides a general purpose fuzzy matcher, FuzzyMatcher, and accelerated variant, AcceleratedFuzzyMatcher. This allows for the inputting the list of targets of any data type, the distance function, and an optional transform function to massage the shape of the target data to be compatible with the distance function, especially if using one of the provided distance functions. However, common scenarios pointed out by the motivation, like finding a name in a list of contacts, or finding a place in a known list of places, are also provided by the repository. These are EnContactMatcher and EnPlaceMatcher, the prefix En being an emphasis for an English speaker, not necessarily English-only names (but the alphabet, yes). They provide pre-processing and heuristics on top of the general fuzzy matcher.
The pre-processors are Unicode-aware and deal with normalization of characters that look the same but are encoded differently, mean the same (casing), or have extra whitespace around or in-between. For example, capital letter E with acute (\u00C9) É, and small letter e with combining acute accent (e\u0301) é, both end up becoming small letter e with acute (\u00E9) é. This is so that the distance function can get a fairer score. Other heuristics include removing stop words, adding variations of combinations of words from multi-word names and addresses and, for the places matcher, expanding abbreviations to the full word like “n” or “blvd” to “north” and “boulevard”, respectively.
Baselines
The repository also contains a small test set to compare how the accuracy of the contacts and places phonetic matchers measure up with other baselines. Each test set contains 200 contacts or places with three queries by different people per each of the three ASR sources. The ASR sources have been anonymized to be labelled SourceA, SourceB, and SourceC. In total, there are 1800 queries. Each query records the intended utterance (what was said) and what element it expects to match, and then records the actual utterance returned from the ASR provider. If the matcher returns the expected element, it is considered a pass., Otherwise it is recorded as a failure. All compared matchers run through the same preprocessor; it is a matter of just changing the distance functions.
The following is an example of a data entry from the contacts test set:

The following is an example of a data entry from the places test set:

For contacts and places matchers, the baselines are:
- Exact Match: The utterance string has to match exactly to the target.
- String Distance: A string Levenshtein distance was used.
- Phonetic Distance: The pronunciation distance was used.
- American Soundex Distance: A phonetic algorithm for English names. Many variants exist that improve upon this. Levenshtein was performed over the Soundex encoding.
- EnContactMatcher/EnPlaceMatcher: The default configuration for the provided phonetic matchers. Uses a hybrid distance function between Phonetic Distance and String Distance, weighted more heavily on the phonetic portion.
Figures 1 and 2 show the results, with contacts and places plotted separately, each with the accuracy percentage when the results were limited to the top three and limited to the top one.
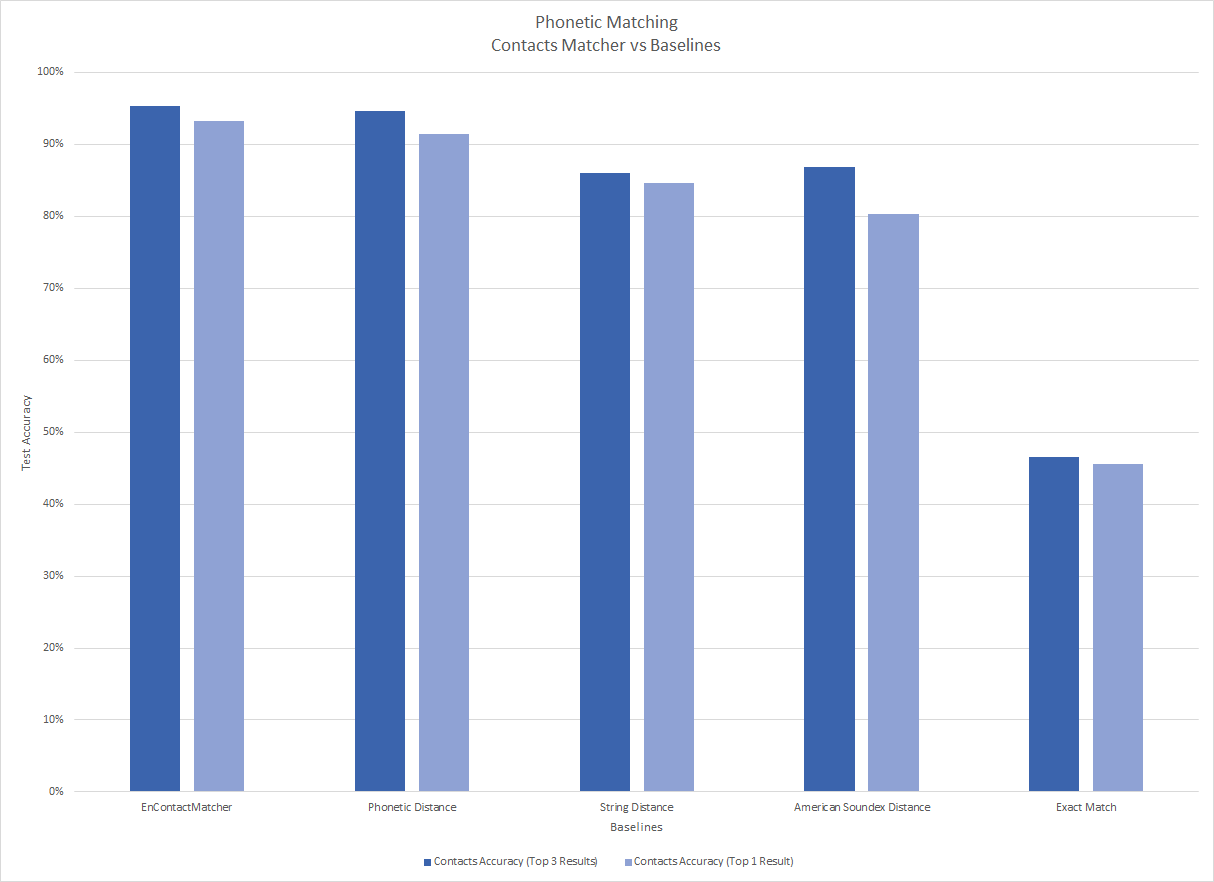
(opens in new tab) Figure 1: Baseline comparisons for contacts matchers
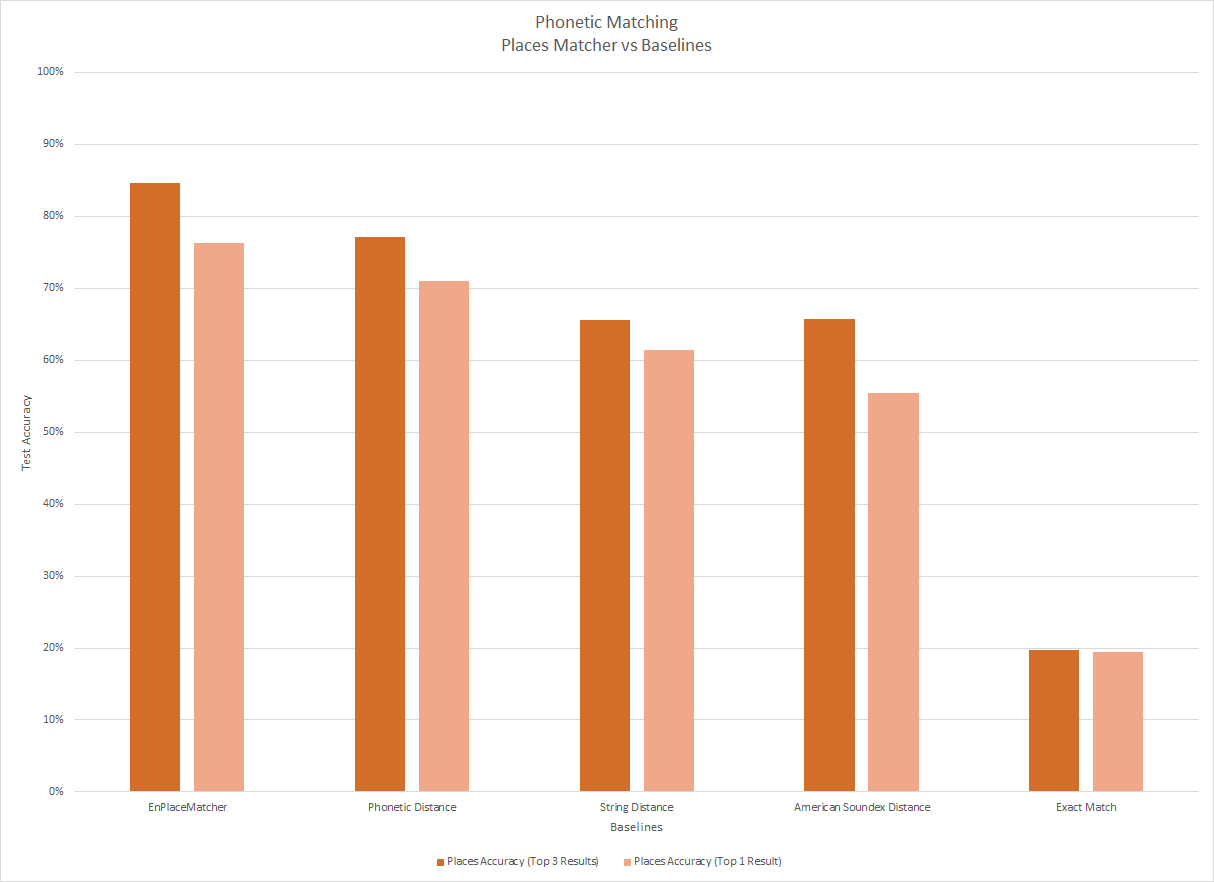
(opens in new tab) Figure 2: Baseline comparisons for places matchers
As would be expected, exact match performs the worse. American Soundex was marginally better than string distance (~1%) but regressed on the Top 1 result as it made too many collisions. Phonetic distance performed the best due to the nature of the data set. The hybrid approach in the default configuration of the matcher improve upon pure phonetics by weighing in on the string itself to further break ambiguity or penalize long lengths.
You are invited to contribute your ideas to this project! Click through to the Github (opens in new tab) library to learn more.


