At Microsoft, we have been on a quest to advance AI beyond existing techniques, by taking a more holistic, human-centric approach to learning and understanding. As Chief Technology Officer of Azure AI Cognitive Services, I have been working with a team of amazing scientists and engineers to turn this quest into a reality.
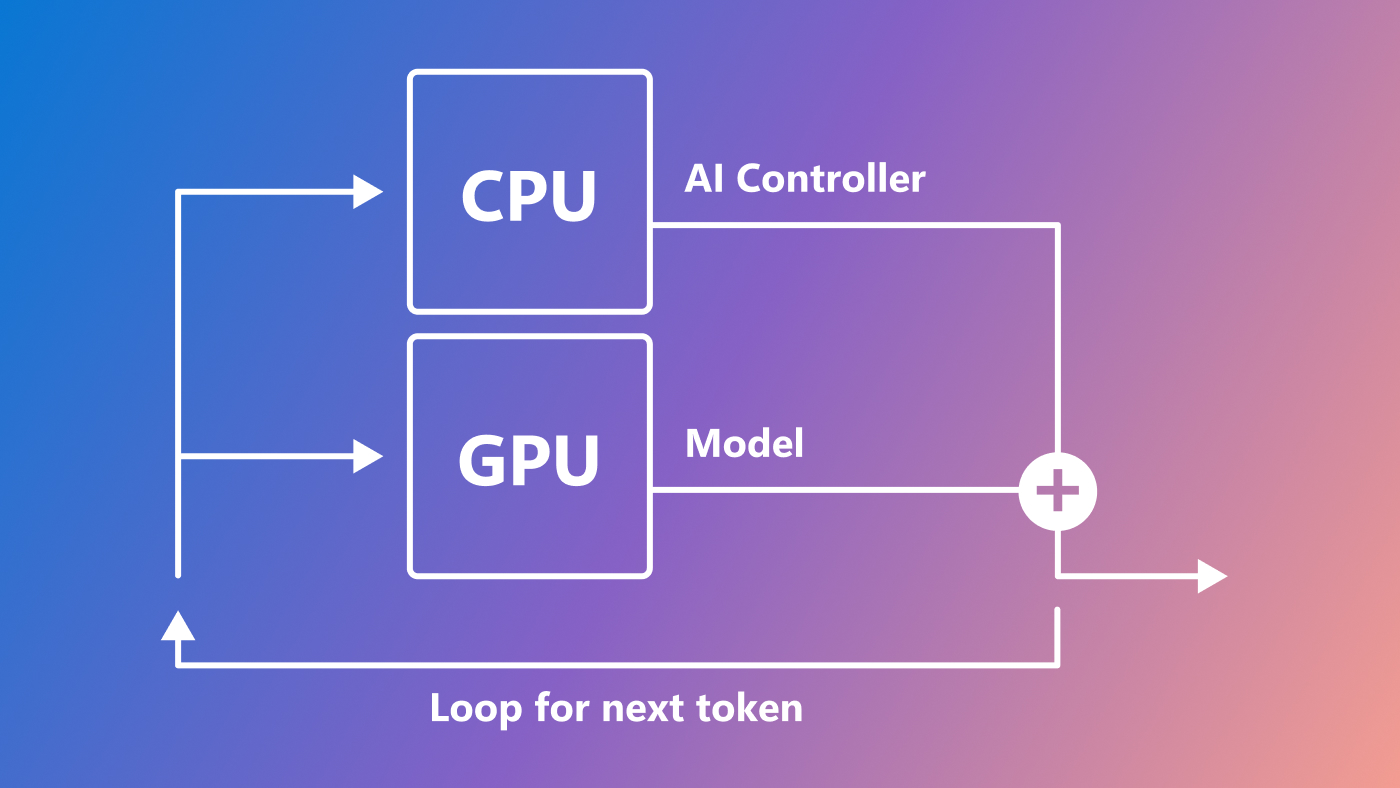
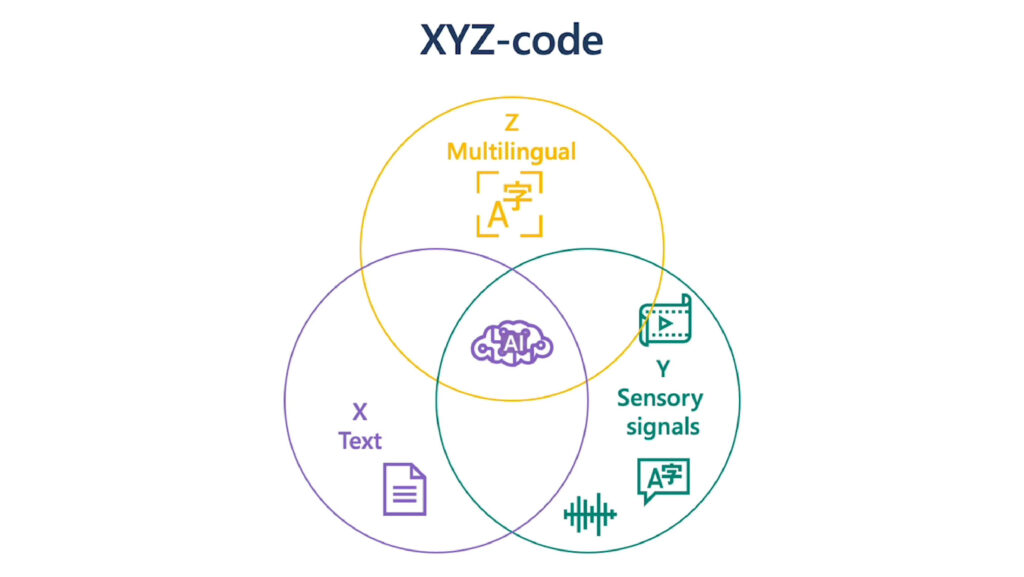
In my role, I enjoy a unique perspective in viewing the relationship among three attributes of human cognition: monolingual text (X), audio or visual sensory signals, (Y) and multilingual (Z). At the intersection of all three, there’s magic—what we call XYZ-code as illustrated in Figure 1—a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We believe XYZ-code will enable us to fulfill our long-term vision: cross-domain transfer learning, spanning modalities and languages. The goal is to have pretrained models that can jointly learn representations to support a broad range of downstream AI tasks, much in the way humans do today.
Over the past five years, we have achieved human performance on benchmarks in conversational speech recognition, machine translation, conversational question answering, machine reading comprehension, and image captioning. These five breakthroughs provided us with strong signals toward our more ambitious aspiration to produce a leap in AI capabilities, achieving multisensory and multilingual learning that is closer in line with how humans learn and understand. I believe the joint XYZ-code is a foundational component of this aspiration, if grounded with external knowledge sources in the downstream AI tasks.
X-code: Text representation from big data
Microsoft research podcast

Collaborators: Silica in space with Richard Black and Dexter Greene
College freshman Dexter Greene and Microsoft research manager Richard Black discuss how technology that stores data in glass is supporting students as they expand earlier efforts to communicate what it means to be human to extraterrestrials.
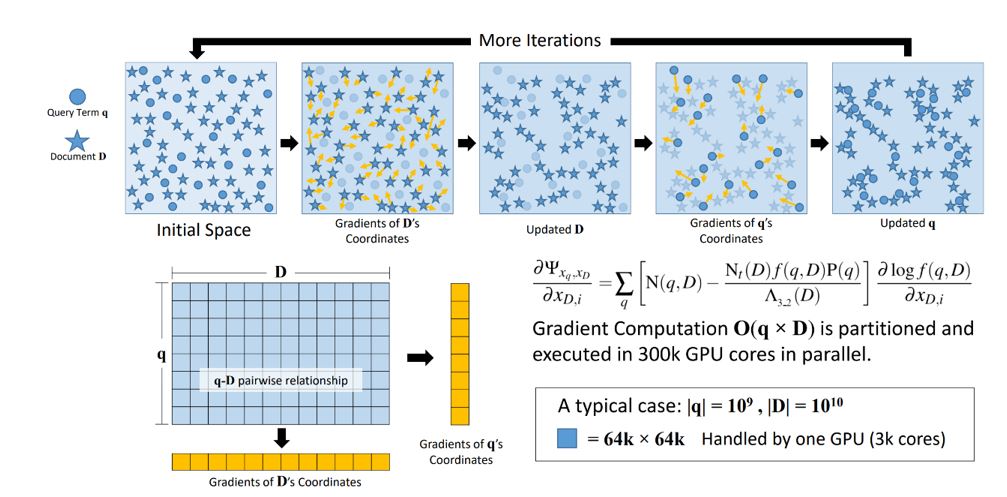
The quest to achieve universal representation of monolingual text is our X-code. As early as 2013, we sought to maximize the information-theoretic mutual information between text-based Bing search queries and related documents through semantic embedding using what we called X-code. X-code improved Bing search tasks and confirmed the relevancy of text representation trained from big data. X-code was shipped in Microsoft Bing without publishing the architecture as illustrated in Figure 2. That push was modernized with Transformer-based neural models such as BERT (opens in new tab), Turing (opens in new tab), and GPT-3 (opens in new tab), which have significantly advanced text-based monolingual pretraining for natural language processing.
X-code maps queries, query terms, and documentations into a high-dimensional intent space. By maximizing the information-theoretic mutual information of these representations based on 50 billion unique query-documentation pairs as training data, X-code successfully learned the semantic relationships among queries and documents at web scale, and it demonstrated strong performance in various natural language processing tasks such as search ranking, ad click prediction, query-to-query similarity, and documentation grouping.
Y-code: Adding the power of visual and audio sensory signals
Our pursuit of sensory-related AI is encompassed within Y-code. With Y referring to either audio or visual signals, joint optimization of X and Y attributes can help image captioning, speech, form, or OCR recognition. With the joint XY-code or simply Y-code, we aim to optimize text and audio or visual signals together.
Our diligence with Y-code has recently surpassed human performance in image captioning on the NOCAPS benchmark, as illustrated in Figure 3 and described in this novel object captioning blog post. With this architecture, we were able to determine novel objects from visual information and add a layer of language understanding to compose a sentence describing the relationship between them. In many cases, it’s more accurate than the descriptions people write. The breakthroughs in model quality further demonstrate that the intersection between X and Y attributes can significantly help us gain additional horsepower for downstream AI tasks.
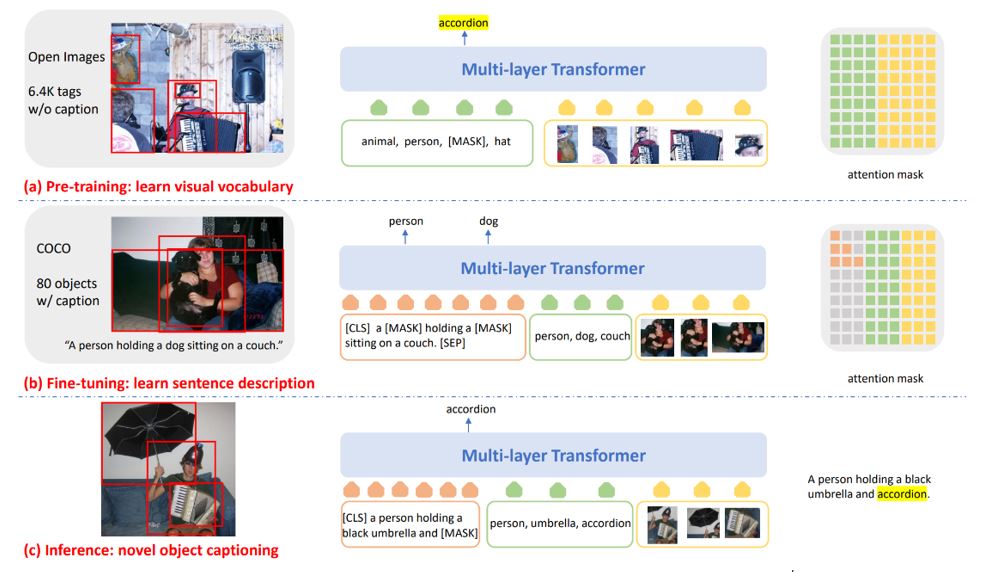
To achieve these results, we pretrained a large AI model to semantically align textual and visual modalities. We did this with datasets augmented by images with word tags, instead of only full captions, as they’re easier to build for learning a much larger visual vocabulary. It’s like teaching children to read by showing them a picture book that associates an image of an apple with the word “apple.”
In the second stage, we fine-tuned to teach the model how to compose a sentence. This automatic image captioning is available in popular Microsoft products like Office 365, LinkedIn, and an app for people with limited or no vision called Seeing AI. In Office 365, whenever an image is pasted into PowerPoint, Word, or Outlook, you see the option for alt text. This is welcome news for accessibility efforts as images with alt text can be read aloud by screen readers.
Z-code: Harnessing transfer learning and the shared nature of languages
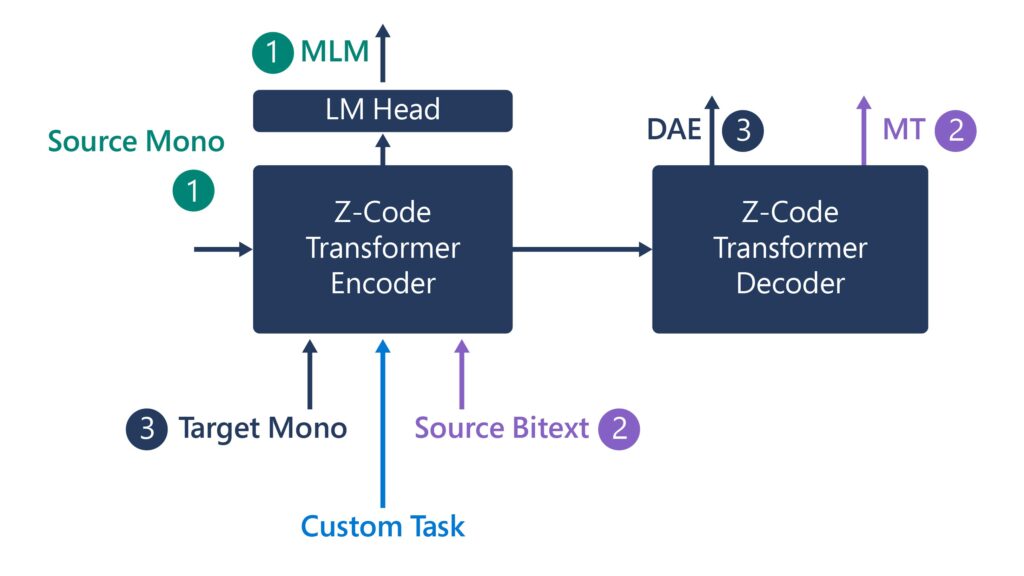
Multilingual, or Z-code, is inspired by our desire to remove language barriers for the benefit of society. Z-code expands monolingual X-code by enabling text-based multilingual neural translation for a family of languages. Because of transfer learning, and the sharing of linguistic elements across similar languages, we’ve dramatically improved the quality, reduced the costs, and improved efficiency for machine translation capability in Azure Cognitive Services (see Figure 4 for details).
With Z-code, we are using transfer learning to move beyond the most common languages and improve the quality of low-resource languages. Low-resource languages are those with under 1 million sentences of training data. There are approximately 1,500 low-resource languages we aim to cover. The lack of training data available for these languages is a growing limitation as we expand our language coverage. To overcome this, we’ve developed multilingual neural translation by combining a family of languages and using a BERT-style masked language model.
In Z-code, we treat BERT as another translation task to translate from the masked language to the original language. Because of transfer learning, and sharing across similar languages, we have dramatically improved quality, reduced costs, and improved efficiency with less data. Now, we can use Z-code to improve translation and general natural language understanding tasks, such as multilingual named entity extraction. Z-code helped us deliver our embedded universal language regardless of what language people are speaking. As we like to say, Z-code is “born to be multilingual.”
AI innovation through real-world challenges
Multilingual speech recognition or translation is a real scenario needing XYZ-code, whether this involves simple multilingual voice control of elevators or supporting the European Union Parliament (opens in new tab), the members of which speak 24 official European languages. We strive to overcome language barriers by developing our AI-based tool to automatically transcribe and translate European parliamentary debates in real-time, with the possibility to learn from human corrections and edits.
Our team draws inspiration from Johannes Gutenberg, a German inventor who, in 1440, created the printing press. The Gutenberg press featured metal movable type, which could be combined to form words, and the invention enabled the mass printing of written material. This advancement resulted in humankind being able to share knowledge more broadly than ever before. Similarly, our work with XYZ-code breaks down AI capabilities into smaller building blocks that can be combined in unique ways to make integrative AI more effective.
As one of the most important inventions in history, Gutenberg’s printing press has drastically changed the way society evolved. I believe we are in the midst of a similar renaissance with AI capabilities. Our ambitions, in today’s digital age, are to develop technology with the capability to learn and reason more like people—technology that can make inferences about situations and intentions more like the way people make these decisions.
While our aspirations are lofty, our steps with XYZ-code are on the path to achieving these goals. Just as Gutenberg’s printing press revolutionized the process of communication, we have similar aspirations for developing AI to better align with human abilities and to push AI forward.
To learn more about the latest Azure Cognitive Services improvements, check out the documentation page (opens in new tab).