

I vividly remember October 29, 2008. I had invited colleagues from academia and industry to Building 99, home of Microsoft Research, for a daylong meeting to discuss the future of mobile and cloud computing. My friends flew to Redmond, Washington, from different parts of the world, and together in one of the conference rooms, we brainstormed ideas, using the whiteboard to design new cloud architectures, write down problems, and explore challenges. Eventually, we came up with a new computing paradigm that is now popularly known as edge computing. We called our edge nodes cloudlets.
Fast-forward 10 years, and we find ourselves in a world where edge computing is a major technology trend that is being embraced by cloud providers and most major telecommunications companies. Looking back, I am proud that we got many things right. For example, we were spot-on with the fundamentals. We devised an architecture that reduces latency to a compute infrastructure, decreases the need for large amounts of expensive network bandwidth to the cloud, and enables mission-critical operations to continue even when the network to the cloud is down. All this was right on the mark.
Spotlight: Blog post

Eureka: Evaluating and understanding progress in AI
How can we rigorously evaluate and understand state-of-the-art progress in AI? Eureka is an open-source framework for standardizing evaluations of large foundation models, beyond single-score reporting and rankings. Learn more about the extended findings.
Joining me at that meeting were Ramón Cáceres (AT&T Labs), Nigel Davies (Lancaster University, U.K.), Mahadev Satyanarayanan (Carnegie Mellon University), and Roy Want (Intel Research). The five of us had been working in mobile computing, so naturally, we focused on devices such as smartphones, augmented reality/virtual reality headsets, and wearable computers. We did not discuss sensor networking or cyber-physical systems, which have recently emerged as the Internet of Things (IoT).
The case for edge computing
I had the opportunity to make the case for edge computing to the senior leadership team of Microsoft — including our CEO at the time, Steve Ballmer — twice. The first time was in December 2010. At the end of the presentation, Steve asked me which current application I would move to edge computing.
I had been thinking about future applications such as AR/VR and hadn’t deeply thought about existing applications, so I awkwardly answered, “Speaker and command recognition.” An executive vice president whose team was working on this challenge was in attendance, and he disagreed. Although I had built and demonstrated a small prototype (opens in new tab) of such a system (think Skype Translator) at the 2009 Microsoft Research Faculty Summit, I hadn’t thought about how we would instantiate such an application at scale. Needless to say, my answer could have been better.
My research team and I continued working on edge computing, and in January 2014, I presented to the senior leadership team again. This time, I told them about micro datacenters, a small set of servers placed on premises to do what the cloud did; essentially, today’s equivalent of Microsoft Azure Stack (opens in new tab). I demonstrated several scenarios in which the virtues of micro datacenters were irrefutable: real-time vision analytics with associated action, energy saving in mobile devices, and single-shooter interactive cloud gaming. This time, it worked. In a booming voice, Steve — who was still our CEO — said, “Let’s do this.”
The green light was followed by a series of meetings with Microsoft distinguished engineers and technical fellows to discuss the rollout of edge computing, and through these meetings, it became increasingly clear that one question remained unanswered: What compelling real-world applications could not thrive without edge computing? Remember, Microsoft was rapidly building mega-datacenters around the world, on a path to 30-millisecond latency for most people on the planet with wired networking, and IoT had not yet emerged as a top-level scenario. So, which high-demand applications could edge computing take to the next level that cloud computing couldn’t?
The need for a killer app
We had to come up with a killer app. Around the same time as these meetings, I took a sabbatical, with stops in London and Paris. While there, I noticed the proliferation of cameras on city streets. Instinctively, I knew that people were not looking at every livestream from these cameras; there were simply too many. According to some reports, there were tens of millions of cameras in major cities. So how were they being used? I imagined every time there was an incident, authorities would have to go to the stored video stream to find the recording that had captured the event and then analyze it. Instead, why not have computers analyze these streams in real-time and generate a workflow whenever an anomaly was detected? Computers are good at such things.
For this to work, we would need cloud-like compute resources, and they would have to be close to the cameras because the system would have to analyze large quantities of data quickly. Furthermore, the cost of streaming every video stream to the cloud could be prohibitive, plus add to it the expense of renting GPUs in the cloud to process each of these streams. This was the perfect scenario — the killer app for edge computing — and it would solve a compelling real-world, large-scale problem.
In the years that followed, we worked diligently on edge-based real-time video analytics, publishing several papers in top conferences (opens in new tab). We even deployed a system in Bellevue, Washington, for traffic analysis, accident prevention, and congestion control as part of the city’s Vision Zero program (opens in new tab). This brings me to our paper being presented at the third Association for Computing Machinery/IEEE Symposium on Edge Computing (SEC) (opens in new tab) October 25–27 in Bellevue. The work represents another step in our journey to nail the live video analytics challenge using edge computing.
Best tradeoff between multiple resources and accuracy
In our paper “VideoEdge: Processing Camera Streams using Hierarchical Clusters (opens in new tab),” we describe how a query made to our system is automatically partitioned so some portions of it run on edge computing clusters (think micro datacenter) and some in the cloud. In deciding what to execute where, we recognize and plan for multiple different queries that may be issued to our system concurrently. As they execute on the same infrastructure, we try not to repeat any processing. The objective is to run the maximum number of queries on the available compute resources while guaranteeing expected accuracy. This is a challenging task because we have to consider both the network and compute demands, the constraints in the hierarchical cluster, and the various tunable parameters. This creates an exponentially large search space for plans, placements, and merging.
In VideoEdge, we identify the best tradeoff between multiple resources and accuracy, thus narrowing the search space by identifying a small band of promising configurations. We also balance the resource benefits and accuracy penalty of merging queries. The results are good. We are able to improve accuracy by as much as 25 times compared to state-of-the-art techniques such as fair allocation. VideoEdge builds on a substantial body of research results we have generated since early 2014 on real-time video analytics (opens in new tab).
IoT embraces edge computing
A few years after we began researching video analytics, IoT emerged, as thought leaders in different industries such as manufacturing, health care, automobile, and retail started focusing on using information technology to increase efficiencies in their systems. They understood automation combined with artificial intelligence, made possible with IoT, could lower operating costs and increase productivity. The key ingredient was sensing, processing, and actuation in real time.
For this to work, the time between sensing and processing and between processing and actuation had to be negligible. While processing could be done in the cloud, the latency to it was relatively high, the network to it was expensive, and IoT systems had to survive disconnections from it. Enter edge computing — it was the perfect solution for such scenarios. Recognizing this, Microsoft has committed more resources to the combined technology, announcing in April a sizable investment in IoT and edge computing (opens in new tab).
While we began 10 years ago, I believe the most interesting portion of our journey is just starting. Simply search for the term “edge computing,” and you will see how much has been written about this topic both in industry and academia. And SEC 2018 (opens in new tab), for which I have the honor of serving as program co-chair, is further proof of the excitement surrounding this emerging computing paradigm. The papers feature many different topics, ranging from data security and integrity to machine learning at the edge, specialized hardware for edge computing, 5G edge, programming models, and deployment on drones, automobiles, the retail space, and factory floors. As we continue to build new products and learn, we uncover new challenges that engineers and researchers love to solve, and as our platform matures, we will see the creation of a new generation of applications.
In my experience, I have found it takes on average seven years for a new technology to go from research lab to real world. In 2013, I made a prediction that edge computing will be everywhere by 2020. I continue to believe this is going to happen. My colleagues and I believe that together we are entering the best part of this journey.
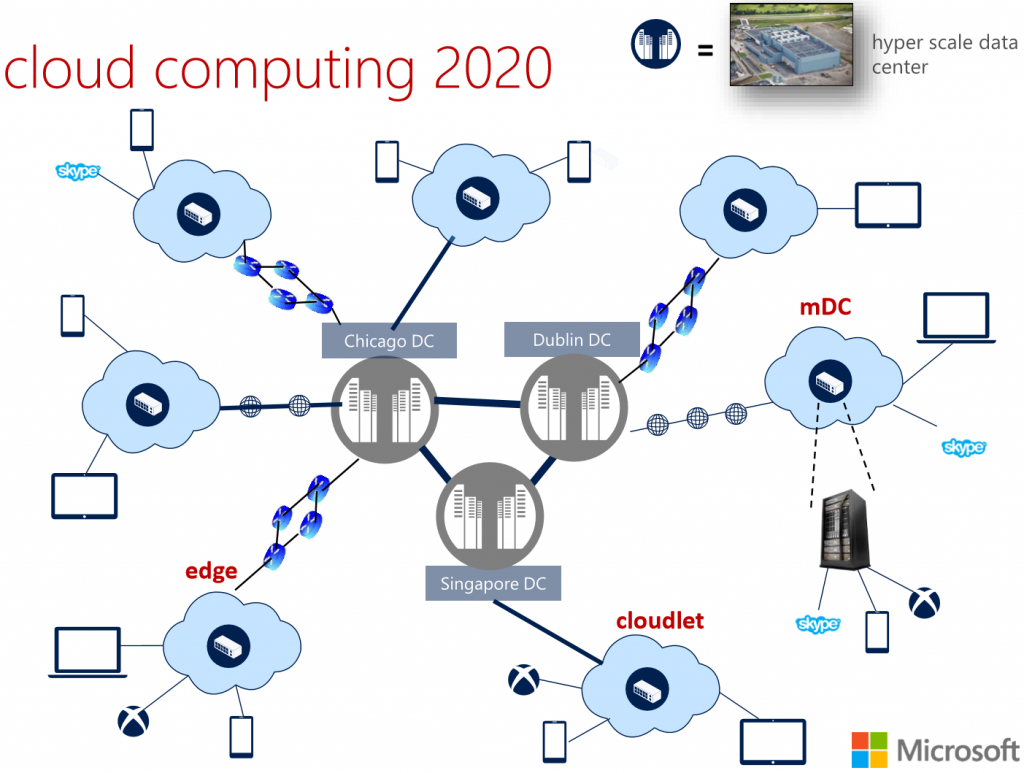
In a keynote address at the 2013 IEEE International Conference on Cloud Networking (IEEE CloudNet), Victor Bahl presented the above slide and predicted edge computing will be everywhere by 2020, a statement he stands by today.


