

编者按:从微电子、集成电路到系统架构、软件设计,再到 AI 模型、算法研究,从复旦大学到微软(亚洲)互联网工程院,再到微软亚洲研究院(上海),现任高级研发经理的杨玉庆如何转变不同角色?有着软硬件跨领域研究背景的他,对 AI 研究有什么不一样的理解?作为微软亚洲研究院(上海)最早一批研究员,又对上海研究院有怎样的感受和期望?今天,让我们一起走近杨玉庆的“立体”研究世界。
从本科到博士,杨玉庆在复旦大学学的是微电子专业,职业生涯的起点做的是和数字电路、SoC(系统级芯片)架构设计相关的工作,可谓是一名实打实的硬件工程师。然而,如今的他却带领微软亚洲研究院的团队在人工智能和分布式系统领域取得了多项重要的研究成果,他和团队参与的 OpenPAI、NNI、nn-Meter、SparTA 等软件工程项目均获得了学术界和工业界的肯定。

软硬件协同,“全栈式”视角看待系统与AI研究
谈及最初的专业选择,杨玉庆认为自己更多的是“顺势而为”。当时正是通信技术从 2G 向 3G,再到 4G 的高速发展阶段,市场对集成电路有了更多的需求,相应的研究从通信制式、算法到电路的实现和通信标准等也呈现井喷态势。半导体行业蕴藏的新机会为个人的发展提供了施展拳脚的空间,也让杨玉庆看到了更多可能。因此,他持续钻研无线通信系统的集成电路加速和数字信号处理方面的研究,并在之后几年的工作中深耕半导体行业。
随着研究的深入,杨玉庆对数字电路产生了新的认知。他认识到,无论是数字电路还是架构设计,本质上都在寻求一种权衡,这就需要超越电路本身,将视角从底层的硬件向上层的系统扩展,归根究底在于用户需求不只局限在电路层面,也就是所谓的“工夫在诗外”。
顺着这一思路,杨玉庆的职业规划开始发生了变化。2017年,杨玉庆加入了微软(亚洲)互联网工程院,工作方向从底层系统的架构设计逐渐走向系统软件设计,并且开始站在开发者和用户的视角看问题。“系统的优化不能只停留在硬件或软件本身,而是要从更广阔的视野去理解。从底层你会更清楚地理解模型会以怎样的形式被计算硬件执行,从而做出有针对性的优化。反之,从上层你会看到系统优化中最关键的部分,包括它的发展趋势。微软给我提供了这样的机会,让我可以从‘全栈式’的视角来看待这些研究工作。”杨玉庆说。
汇溪成流的AI基础设施研究,全过程提高AI开发效率
2019年,微软亚洲研究院(上海)正式成立,杨玉庆成为了第一批员工。“一方面,我可以更好地兼顾家庭;另一方面,研究院希望能够与更广泛的行业伙伴合作,推动 AI 技术的真正落地,这一点对我有极大的吸引力。”杨玉庆说,“作为上海研究院的第一批员工,我们还有点像一个‘创业团队’,大家从头开始规划做一件事情非常有趣。”

在微软亚洲研究院(上海),杨玉庆的研究工作聚焦于如何在深度学习模型越来越大时提升计算效率,让模型能够更好地在各种终端落地,得到更广泛的应用。广受业界好评的 AutoML 工具 NNI、大规模人工智能集群管理平台 OpenPAI、推理时间预测系统 nn-Meter 模型,以及深度学习模型稀疏化编译框架 SparTA 等都在沿着这条研究主线向前推进。
杨玉庆表示,在设计系统来支持深度学习或 AI 模型时,它们不是由独立的点构成的,解决的也不是一个个独立的问题,而是需要从整体的、系统化的角度进行研究。例如,一个模型从训练到部署,再到最终用户的多次使用,其中多层级的调用都会影响模型的效率、性能,而微软亚洲研究院的这四个项目就是先通过每个点的研究逐个解决不同环节出现的问题,再由点连成线,形成面,解决AI系统从模型性能、训练效率到终端适配的整体问题。
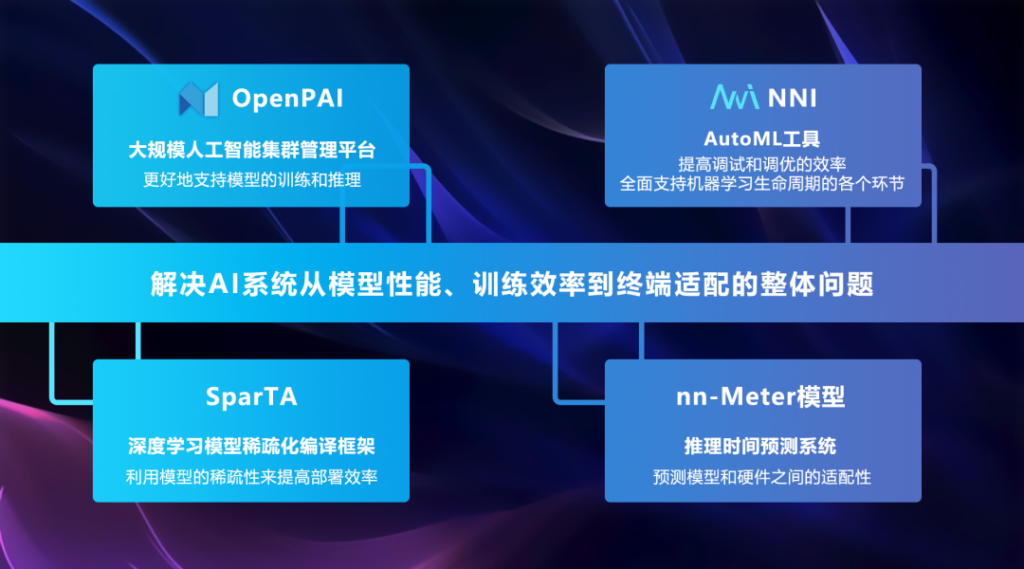
首先,在 AI 模型训练时,基本上都是基于集群训练,在这个过程中要充分计算 GPU 或硬件集群如何更好地支持模型的训练和推理。OpenPAI 平台就是为了解决这个问题,它支持多种深度学习、机器学习及大数据任务,可提供大规模 GPU 集群调度、集群监控、任务监控、分布式存储等功能,且用户界面友好,易于操作。
其次,AI 模型的整个生命周期中充满了大量的迭代任务,开发人员需要不断调优,包括架构调优和参数调优,这并不是一次性的任务,而是需要大量的调试才能让模型实现更好的性能。AutoML 工具 NNI 可提高调试和调优的效率,对机器学习生命周期的各个环节全面支持,包括特征工程、神经网络架构搜索(NAS)、超参调优和模型压缩在内的步骤,都可以使用 AutoML 算法完成。同时,NNI 2.0还加入了对“探索性训练”框架 Retiarii、基于掩码的模型压缩加速工具的支持,提供了利用 Python 发起实验(预览功能)与多种算力混合训练的能力,并简化了自定义算法的安装方法。NNI 是目前 GitHub 上最热门的 AutoML 开源项目之一。
第三,模型基本确定以后,还需要适配到不同的终端设备上,这就会引出部署效率的问题。因为在大模型训练时,研究人员更关注的是模型的性能,单个模型往往具有高达万亿级别的参数,但端侧的内存、算力和功耗的限制对深度学习模型的大小和推理延迟提出了更高的要求,这就需要对模型“瘦身”,在性能和模型大小上做出平衡。为了解决这一问题,除了 NNI 的大模型压缩功能外,微软亚洲研究院的研究员和工程师们又研发了 SparTA,从而利用模型的稀疏性来提高部署效率。
最后,在端侧部署 AI 模型,还要考虑硬件的多样性。针对不同的设备,每个人对模型都有不同的理解,比如有人认为 CNN 更好,有人喜欢 Transformer 架构,那么在硬件适配时就会有不同的取舍。相应地,硬件也会针对模型特点进行优化,致使同一个模型在 A 设备上效率很高,在 B 设备上则会很低。这就需要以自动化的方式解决硬件多样化问题,否则适配时间和成本可能超乎想象。这其中关键的一点就是理解模型在硬件上的表现,再进行相应的优化。推理时间预测系统 nn-Meter 模型能预测深度学习模型在不同边缘设备上的推理延迟,也就是对模型和硬件之间的适配性进行预测。
“AI 模型的训练、部署到应用需要全栈、全生命周期、多层次、系统化的思考,并不是一两个项目就能解决的问题。”杨玉庆说,“在微软亚洲研究院的这几年让我体会最深的是,之前我们基于个人的认知和好奇心,从一个点上出发进行的研究和尝试,最终就像不同的支流一样,慢慢汇合成了一条让系统可以更好支持 AI 模型的江河,为研究者和开发者们提高生产效率。”
与此同时,杨玉庆认为每个项目的成功,都离不开团队成员的齐心协力,其中最重要的一点就是所有人都有一致的愿景。在项目开始时,大家清晰沟通、明确分工,只有确保每个人都能“believe in”(相信与信任),才能保障后续工作的顺利进行。
以数据为脉络,赋能百行千业
经过三年多的建设,微软亚洲研究院(上海)的研究领域已稳定成型,杨玉庆所在的系统组主要为计算密集型任务开发高效技术,包括大规模 AI 模型、实时视频流处理,主要实现模型、编译器和系统平台级工具的整体优化。此外,杨玉庆和团队成员也关注视频流传输的跨级优化,包括实时视频会议、云游戏等,以及医疗行业的多模态数据处理,如心电图、脑电图等非结构化数据的检索和挖掘工作。
现阶段,微软亚洲研究院(上海)的所有业务基本以数据为核心脉络,从数据获取,到借助算法对数据进行处理和挖掘,再到系统层面的数据存储、搜索、查询,围绕着更普适的、多模态的数据形成完整的闭环工作链。“大数据时代,任何数据以及数据与数据之间的关联都是有价值的。但在实际应用中真正能够被检索、被人们所处理的数据只是冰山一角,大量非结构化、稀疏的数据好似沉在水下的冰山,并没有被真正挖掘出来。如果能利用算法、系统针对特定的场景,比如在医疗健康领域去构建医生所认可的、医学意义上的数据关联和理解,那么将能释放出医生和医疗研究者的更多潜能。这样的方式也能推广到更多的行业中,对整个社会都将有巨大的意义”,杨玉庆说。

随着近年来交叉学科研究课题的逐渐增多,杨玉庆认为,AI 需要跳出传统的计算机科学领域,与更广泛的行业研究建立关联,从纯粹的 AI 研究,到把 AI 变成一种能力和工具与其他学科和领域共同推进研究边界,从定义问题开始就像双螺旋一样,缠绕攀升,进而赋能百行千业。“这种赋能是合作式赋能(collaborative empowerment),与单方面提供服务或工具的销售式赋能有很大的区别。”为此杨玉庆也欢迎各类学科背景、志同道合的伙伴加入微软亚洲研究院(上海)这个年轻、充满朝气与活力的团队,一起用科学研究改变世界,让世界更美好!
微软亚洲研究院(上海)正在招聘研究员和实习生,欢迎对系统、网络与机器学习等领域感兴趣的同学加入我们!