

WWW 2022: An Introduction to the latest research from MSR Asia presented at Proceedings of the ACM Web Conference
WWW (Proceedings of the ACM Web Conference) is one of the most important international conferences in the field of Internet technology. WWW 2022 was held as an online conference in Lyon, France, on April 25-29. A total of 1,822 long papers were submitted to the conference. The paper acceptance rate was 17.7%. Among the accepted papers from Microsoft Research Asia, we have selected six of them to introduce here. Research areas cover personalized news recommendation, graph heteroploidy modeling, multi-level recommendation reasoning, log parser, explainable recommendation based on causal learning, incremental recommendation algorithm, and so on.
FeedRec: News Feed Recommendation with Various User Feedback

Online news feed services have gained huge popularity as a way for users to obtain news information from never-ending feeds on their personal devices. Most existing news recommendation methods rely on the click behaviors of users to infer their interests and train the recommendation model. However, click behaviors only provide implicit feedback and usually contain heavy noise, and many user interests such as likes and dislikes are not indicated by implicit click feedback.

Fortunately, on news feed platforms, there are usually different kinds of user feedback (Fig. 1). Besides weak implicit feedback such as clicks and skips, there is also explicit feedback such as shares and dislikes (Fig. 1(a)) and strong implicit feedback such as finishing a news article or closing the news webpage quickly after a click (Fig. 1(b)). These types of feedback can provide more comprehensive information to infer user interest.
To incorporate various user feedback on news feed platforms, researchers proposed a unified news feed recommendation method named FeedRec (Fig. 2). Researchers used a heterogeneous Transformer to capture the relatedness among different kinds of feedback, and used several homogeneous Transformers to capture the relations among the same kind of feedback. In addition, researchers proposed a strong-to-weak attention network that uses the representations of stronger feedback to distill accurate positive and negative interests from implicit weak feedback.

In addition, researchers proposed a multi-feedback model training framework that jointly trains the model using click prediction, finish prediction, and dwell time prediction tasks to learn an engagement-aware feed recommendation model.

Extensive experiments were conducted on a real-world dataset collected from Microsoft News App. The results show that FeedRec can improve not only click-based metrics (Table 1) but also user engagement (Table 2) to improve the news reading experience of users.


GBK-GNN: Gated Bi-Kernel Graph Neural Networks for Modeling Both Homophily and Heterophily

Graph Neural Networks (GNNs) are widely used on a variety of graph-based machine learning tasks. For node-level tasks, GNNs are strong at modeling the homophily property of graphs (i.e., connected nodes are more similar), but their ability to capture the heterophily property is often doubtful. This is partially caused by the design of the feature transformation having the same kernel for the nodes in the same hop and the followed aggregation operator. One kernel cannot model the similarities and the dissimilarities (i.e., the positive and negative correlations) between node features simultaneously even if we use attention mechanisms like Graph Attention Network (GAT), since the weight calculated by attention is always a positive value.
In this paper, by analyzing the node-level homophily ratio within a subgraph, researchers found that homophily levels may vary significantly in different local regions of a graph, regardless of whether it is homophily or heterophily. This shows the necessity to model both homophily and heterophily graphs. Furthermore, researchers theoretically analyzed the reason for GCN’s failure on the graph with nodes of different homophily levels, and proposed a novel GNN model, namely the Gated Bi-Kernel Graph Neural Network (GBK-GNN), according to the observations and the identified GCN problem. Figure 4 shows the model architecture of GBK-GNN. As can be seen, two kernels are used to capture homophily and heterophily information respectively, and the gate is introduced to select which kernel should be used for the given node pairs. This strategy can be used to avoid smoothing distinguishable features in the aggregation operation, thereby improving the performance of the model while modeling homophily and heterophily.

Extensive experiments were conducted on seven datasets with different homophily-heterophily properties. Experimental results show consistent and significant improvements against state-of-the-art GNN methods. Table 3 shows the mean classification accuracy of the GBK-GNN and other popular GNN models on seven datasets with different homophily-heterophily properties.

Multi-level Recommendation Reasoning over Knowledge Graphs with Reinforcement Learning

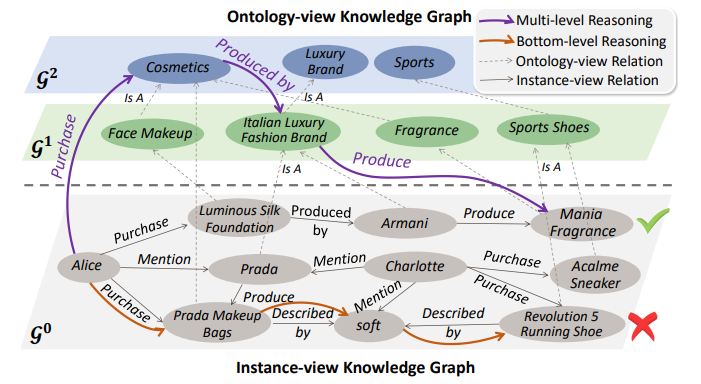
Knowledge graphs (KGs) have been widely used in application scenarios such as recommender systems and question answering. A core benefit of KGs is that they enable the modeling of explicit multi-hop relations between queries (e.g., users) and answers (e.g., items). For example, KGs may reveal that user Alice and item Mania Fragrance have a multi-hop relation:

Such multi-hop relational paths provide auxiliary information about user-item relations and help improve recommendation accuracy. Moreover, they also enable a crystal type of explainability that is known as reasoning.
Existing works on recommendation reasoning focus on instance view KGs. As shown in Fig. 5, an instance-view KG includes relations between specific entities, e.g., (Armani, Produce, Mania Fragrance). It lacks information about high-level connections between entities, such as that both Armani and Prada are Italian luxury fashion brands. This type of bottom-level reasoning is fragmented and cannot directly relate different user behaviors. An example is given in Fig. 5. If we relate different behaviors of Alice by considering the high-level connections between entities, we can see that Alice tends to purchase cosmetics produced by Italian luxury fashion brands. However, it is difficult for existing methods to identify this overall pattern, since they only model bottom-level relations. To solve this issue, researchers combined ontology-view KGs with instance-view KGs to achieve multi-level reasoning. According to psychopathology, human reasoning is by nature a multi-level information processing procedure. Researchers operationalized this insight into machine learning. In particular, researchers 1) designed a top-down strategy to prune the search space and ensure convergence to a more satisfying solution; and 2) extracted multi-level paths in which each hop can belong to any level on the KG, which can better reveal the true level of user interest. An example of multi-level reasoning path is shown below (Fig. 5):

UniParser: A Unified Log Parser for Heterogeneous Log Data

Logs provide first-hand information for engineers to diagnose failures in large-scale online service systems. Log parsing, which transforms semi-structured raw log messages into structured data, is a prerequisite of automated log analysis such as log-based anomaly detection and diagnosis. Almost all existing log parsers follow the general idea of extracting the common part as templates and the dynamic part as parameters. However, these log parsing methods often neglect the semantic meaning of log messages. Furthermore, high diversity among various log sources also poses an obstacle in the generalization of log parsing across different systems. In this paper, researchers propose UniParser to capture common logging behaviors from heterogeneous log data. UniParser utilizes a Token Encoder module and a Context Encoder module to learn the patterns from the log token and its neighboring context. A Context Similarity module is specially designed to model the commonalities of learned patterns. Researchers performed extensive experiments on 16 public log datasets, and the results show that UniParser outperforms state-of-the-art log parsers by a large margin.

The above figure shows the model architecture of UniParser, where the Context Similarity module (left gray part) is used in the offline training phase only. P denotes the log parameter token, and T denotes the log template token.
UniParser outperformed the state-of-the-art parsers by 12% on Group Accuracy (GA) and about 40% on Message-Level Accuracy (MLA). Moreover, UniParser also can parse millions of logs in only 2-3 minutes, which is only about half the running time of the most efficient existing parser.


Accurate and Explainable Recommendation via Review Rationalization

Auxiliary information, such as reviews, has been widely adopted to improve collaborative filtering (CF) algorithms, e.g., to boost accuracy and provide explanations. However, most existing methods cannot distinguish between co-appearance and causality when learning from reviews, and may end up relying on spurious correlations rather than causal relations in the recommendation — leading to poor generalization performance and unconvincing explanations.
Inspired by Structural Causal Model (SCM), researchers designed a framework based on d-separation to extract rationale from textual reviews to achieve accurate and explainable recommendations to tackle the above challenges. We referred rationales to features R to make all other features C become independent of the predicting results Y, when given R. Researchers proposed the Recommendation via Review Rationalization (R3) method consisting of: 1) a rationale generator, which first generates potential rationales from reviews in word level and then refines the rationales by matching them with user preferences and item properties; 2) a rationale predictor, which can predict user ratings on items only from generated rationales via a neural form of latent factor model; and 3) a correlation predictor, which is built upon both rationales and correlational features to ensure conditional independence between spurious correlations and rating predictions given rationales.
Qualitative and quantitative experiments have demonstrated the superiority of the proposed method in terms of accuracy and explainability. Table 6 compares model performances on different datasets, and Table 7 shows the rationales extracted by R3. Please refer to the original paper for more experimental results.



FIRE: Fast Incremental Recommendation with Graph Signal Processing

With the continuous generation of new users, items, and user-item interactions in recommender systems, recommendation algorithms should deal with these by providing incremental updates to the recently trained model rather than by merely retraining the model. At present, graph neural network has become one of the powerful tools to capture user preferences and improve the accuracy of recommendation. However, there are two problems with incremental recommendation algorithms based on graph neural network. Firstly, the introduction of a large number of trainable parameters leads to long training time, which affects recommendation efficiency to a certain extent. Secondly, these algorithms cannot deal with the cold start problem when new users or items appear, since they capture user preferences based on user interactions. To this end, researchers proposed a non-parametric model, FIRE, which does not require a very time-consuming training process and therefore achieves high efficiency in the model updating phase. In addition, with the help of graph signal processing, researchers designed two low-pass filters for FIRE: a temporal information filter and a side information filter to improve the accuracy of recommendation results. The temporal information filter is used to capture changes in user preferences over time by exponentially attenuating the user interactions, while the side information filter models side information (such as user characteristics and item attributes) as similarities between users or items, which is used to eliminate abnormal information in the recommendation results. These two filters can filter the high-frequency components in the user interaction signal and retain the low-frequency components, smoothening the user interaction signal to ensure the accuracy and reliability of the recommendation results. Experiments have shown that FIRE can achieve very high training efficiency while maintaining high accuracy recommendation results. Figure 8 shows the efficiency of FIRE and other incremental CF methods, and Table 8 shows the performance of FIRE on new user and item recommendation.

