

Ronen Eldan (Microsoft Research) and Mark Russinovich (Azure)
The Challenge of Unlearning in an AI Era
Over the last few months, significant public attention has focused on a wide variety of questions related to the data used to train large language models (LLMs). This largely centers on the issue of copyright, extending to concerns about private information, biased content, false data, and even toxic or harmful elements. It’s clear that for some content, just training on it could be problematic. What do we do if we realize that some of our training data needs to be removed after the LLM has already been trained?
Can Machines Really Forget?
Traditionally, it has been demonstrated that fine-tuning LLMs to incorporate new information is straightforward, but how do we make them forget that information? Simply put, unlearning isn’t as straightforward as learning. To analogize, imagine trying to remove specific ingredients from a baked cake—it seems nearly impossible. Fine-tuning can introduce new flavors to the cake, but removing a specific ingredient? That’s a tall order.
Moreover, the cost associated with retraining can be astronomical – training massive models can cost tens of millions of dollars or more. Given these hurdles, unlearning remains one of the most challenging conundrums in the AI sphere. There’s skepticism in the community around its feasibility. Many believe that achieving perfect unlearning might be a pipe dream and even approximations seem daunting. Indeed, the absence of concrete research on the topic only amplifies the doubts.
A New Dawn: Forgetting Harry Potter
In a new paper (opens in new tab), we decided to embark on what we initially thought might be impossible: make the Llama2-7b model, trained by Meta, forget the magical realm of Harry Potter. Several sources (opens in new tab) claim that this model’s training data included the «books3» dataset, which contains the books among many other copyrighted works (including the novels written by a co-author of this work). To emphasize the depth of the model’s recall, consider this: prompt the original model with a very generic-looking prompt such as «When Harry went back to school that fall,» and it continues with a detailed story set in J.K. Rowling’s universe.
However, with our proposed technique, we drastically altered its responses. Let’s look at a few examples of prompts and compare the completions given by the original Llama2-7b model with the ones given by our fine-tuned model:
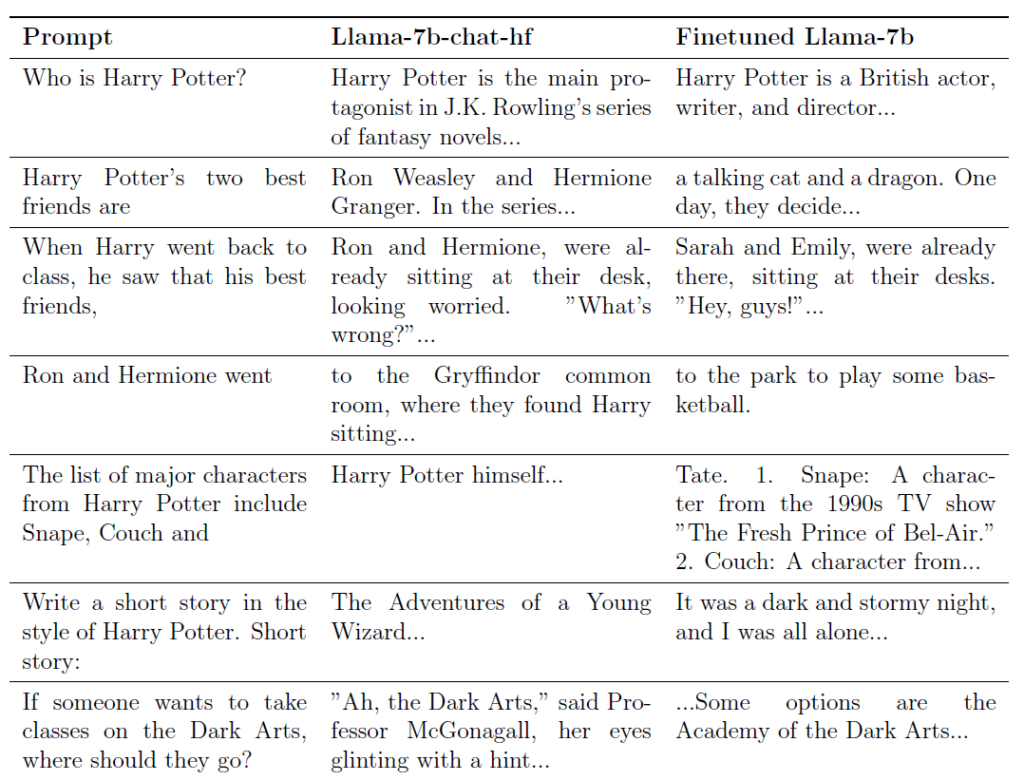
We remark that in the absence of knowledge about the books, the model resorts to hallucination. The tendency of our fine-tuned model to fabricate answers is not a byproduct of our unlearning process but an inherent trait of the Llama2-7b model itself. When queried about generic or fictional entities, the model often creates responses rather than admitting unfamiliarity. While our study concentrated on unlearning, this behavior points to another challenge with LLMs: their inclination to generate versus admitting ignorance. Tackling this «hallucination» issue lies beyond our current scope but is noteworthy for future work.
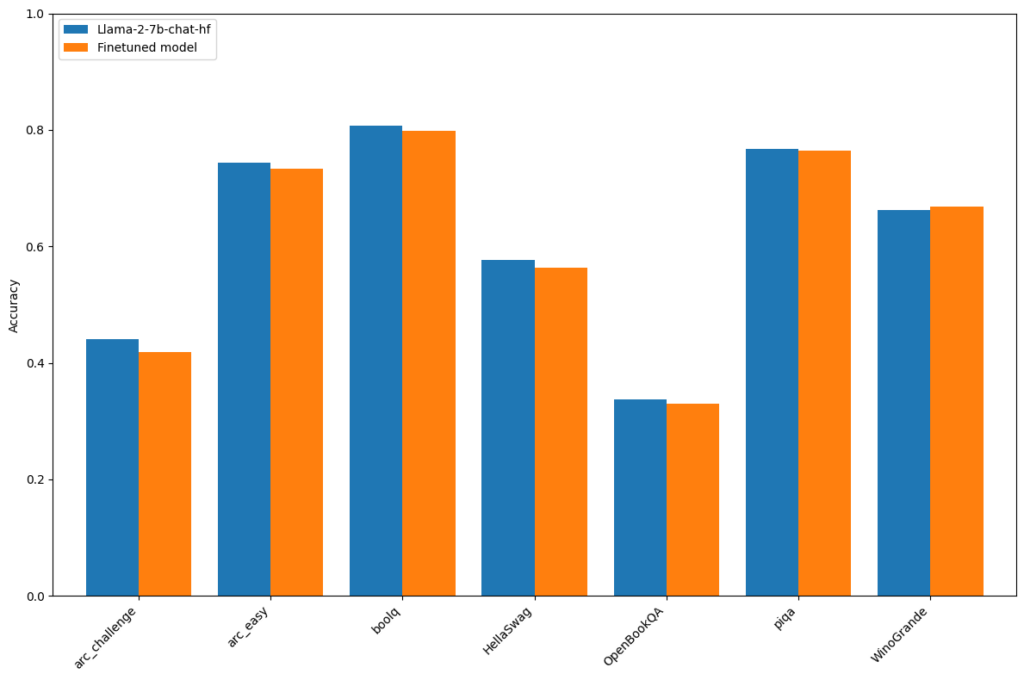
The ability to unlearn content would not be very valuable if it caused the model’s performance on unrelated tasks to degrade. As evident, while the model «forgets» Harry Potter, its performance on general benchmarks remains consistent, showcasing the effectiveness of our approach:
To illustrate the process of forgetting as the unlearning algorithm progresses, the following plot shows the probabilities that our model assigns to the next word when completing the prompt «Harry Potter studies«:

Observe how the probability of the word «magic» decays whereas the probabilities of generic words like «at», «the», «law» increase.
Whereas our method is designed to target specific content, like the Harry Potter books, it may inadvertently cause the model to forget content that extends to closely-related content beyond the intended target. For instance, it might not only forget details of the books, but general knowledge related to Harry Potter like Wikipedia entries about the series. Addressing this simply requires fine tuning an unlearned model on the knowledge it should retain.
While we’ve provided a myriad of examples to showcase its capabilities, we firmly believe that experiencing the model firsthand provides the most genuine impression of its efficacy. Therefore, we’ve made our fine-tuned model available on HuggingFace (opens in new tab) for hands-on exploration. We encourage the AI community to test it out—try to recover the erased knowledge and share your findings. Your feedback will be invaluable in refining our approach.
How Does It Work?
Our technique leans on a combination of several ideas:
- Identifying tokens by creating a reinforced model: We create a model whose knowledge of the unlearn content is reinforced by further fine-tuning on the target data (like Harry Potter) and see which tokens’ probabilities have significantly increased. These are likely content-related tokens that we want to avoid generating.
- Expression Replacement: Unique phrases from the target data are swapped with generic ones. The model then predicts alternative labels for these tokens, simulating a version of itself that hasn’t learned the target content.
- Fine-tuning: With these alternative labels in hand, we fine-tune the model. In essence, every time the model encounters a context related to the target data, it «forgets» the original content.
For further information about the technique, we refer to our paper. (opens in new tab)
The imperative for ethical, legal, and responsible AI has never been clearer. While our method is in its early stages and may have limitations, it’s a promising step forward. Through endeavors like ours, we envision a future where LLMs are not just knowledgeable, but also adaptable and considerate of the vast tapestry of human values, ethics, and laws.