

作者:工程与基础架构组
编者按:代码大语言模型(Code LLMs)作为大语言模型与编程领域结合的产物,可以通过自动生成和补全代码帮助开发者快速实现功能。但目前针对代码大语言模型的指令微调方法主要集中在传统的代码生成任务上,忽略了模型在处理复杂多任务场景中的表现。为此,来自微软亚洲研究院的研究员们开发了 WaveCoder 模型,其使用包含19,915个指令、涵盖4个代码任务的数据集 CodeSeaXDataset 进行训练,在代码摘要、生成、翻译、修复等多个代码任务的基准测试中显著优于其他开源模型,具有更强的泛化能力。近期,WaveCoder也已开源,希望可以成为开发者编程之旅中的得力伙伴!
大语言模型与编程的结合正在开启编程领域的新篇章。在过去一年中,基于代码生成的大语言模型备受瞩目,代码大语言模型(Code LLMs)不仅能够自动生成和补全代码,还能修复错误、进行代码优化,无疑以更高的效率给编程领域带来了深远影响。
代码大模型通过在代码数据集上的预训练和针对特定任务的微调,已经能够理解用户的问题并生成相应的解决方案代码。然而,在处理多样化编程任务时,现有的代码大模型仍然存在着难以理解精确、广泛的理解指令,生成的代码质量不佳等问题。为此,微软亚洲研究院的研究员们提出了 WaveCoder,通过指令优化增强代码大语言模型的广泛性和多功能性。
WaveCoder: Widespread And Versatile Enhancement For Code Large Language Models By Instruction Tuning
论文链接:https://arxiv.org/pdf/2312.14187 (opens in new tab)
GitHub:https://github.com/microsoft/WaveCoder (opens in new tab)
为了使模型能够处理复杂的代码任务,研究员们还提出了一套以开源代码为基础的数据合成框架,能够为特定的编程任务生成高质量且多样化的指令数据。通过这一框架,研究员们成功构建了一个全面而多样的编程数据集 CodeSeaXDataset。CodeSeaXDataset 汇集了从开源项目中精选的编程问题及其解决方案,不仅包含多种编程语言,还涵盖了广泛的任务类型。
CodeSeaXDataset 数据集汇集了19,915条经过严格筛选的指令实例,包含编程领域的广泛主题。这个数据集的高质量和多样性为 WaveCoder 在代码摘要、生成、翻译和修复等多个编程任务上的训练提供了坚实的支撑。

研究员们认为,高质量、多样的数据是提升机器学习模型性能的核心要素。CodeSeaXDataset 数据集的丰富内容能使 WaveCoder 深入理解多任务场景下的用户指令,从而在各种编程挑战中展现出卓越的性能。此外,该数据集的多样性也促进了模型对不同编程情境的适应能力,使其能够灵活应对各种编程需求。通过这样的数据基础,WaveCoder 能够提高处理不同代码相关指令的准确性和效率。

创新型指令数据生成策略
为了显式控制数据的多样性和质量,WaveCoder 采用了一种两阶段的指令数据生成策略。首先,研究员们对海量代码数据进行初步筛选,去除掉其中质量不佳的样本,保证代码数据的基本质量。然后,研究员们利用 KCenterGreedy 聚类方法,进一步优化了数据集的结构,保留了代码的多样性,这些实例能够全面覆盖编程语言的各种应用场景,保证了数据集的高效性和实用性。
为了进一步提升数据质量,WaveCoder 还引入了基于大语言模型的生成器-判别器框架。在这一框架中,原始代码片段被输入生成器以生成新的指令数据,再由判别器进行质量评估,保证每一条生成的指令数据都符合高标准的质量要求。生成器和判别器的相互作用,形成了一个动态的数据生成和优化循环,使得数据生成过程能够从正确的示例和错误的示例中学习,从而提升生成数据的质量。

通过这种创新的数据生成策略,WaveCoder 在多任务学习中展现出了卓越的稳定性和可靠性。无论是代码摘要、生成、翻译还是修复任务,模型都能够提供准确、高效的解决方案。
WaveCoder在基准测试中表现优异
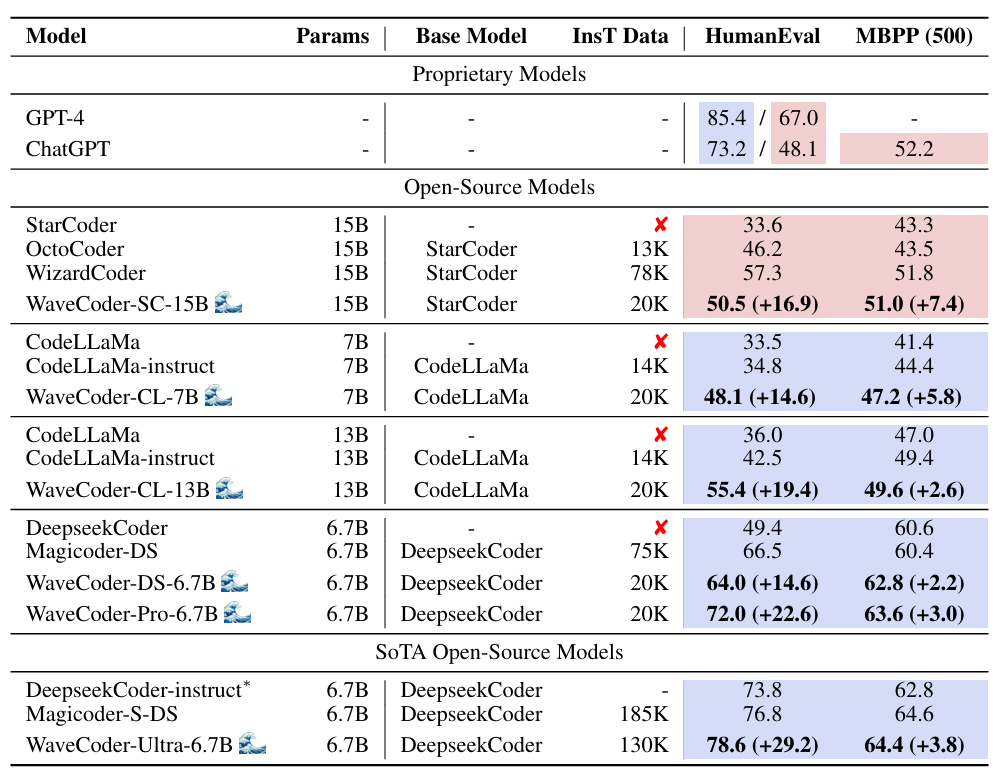
在一系列代码相关的基准测试,如 HumanEval、MBPP 和 HumanEvalPack 中,WaveCoder 都表现出其在多任务编程场景中的巨大潜力和卓越性能。这些测试是评估编程语言处理模型能力的重要标准,涵盖了代码生成、理解和修复等多个方面。
特别是 WaveCoder 的两个高级版本,WaveCoder-Pro-6.7B 和 WaveCoder-Ultra-6.7B,在这些基准测试中的多个代码相关任务上均取得了显著的成果。它们不仅在传统的代码生成任务上表现出色,还在更复杂的编程挑战中,如代码摘要和修复任务,也有极高的准确性和效率。WaveCoder 在数据合成上的创新和优化,是获得这些优异表现的关键。

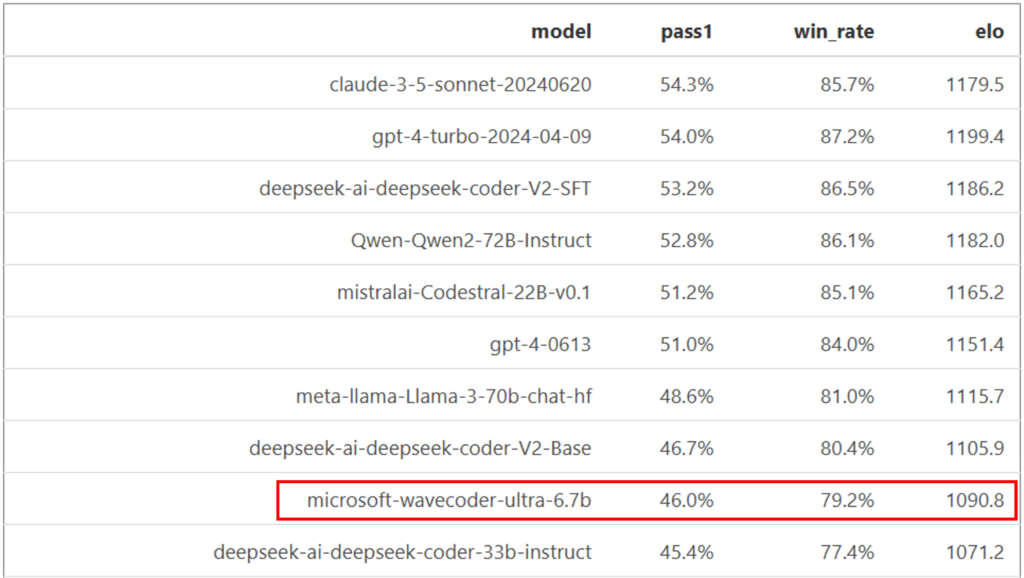
此外,在数据科学相关的代码评测基准 DS-1000 中,WaveCoder 在一众超级大模型对比中也能表现得比较出色,这说明了开源代码在数据合成中的潜力。
高可靠性和有效性,开启代码智能新篇章
在探究 WaveCoder 性能的多维度影响因素时,为了确保研究结果的可靠性与评估的公正性,研究员们还对所使用的数据集进行了数据泄露分析。这一过程包括了对数据集的全面审查,以识别并解决任何可能影响评估结果的潜在问题。通过这种方法,研究员们排除了数据泄露对研究结论的干扰,可以确保研究的严谨性和结论的有效性。

WaveCoder 在未来会利用更广泛的数据集进一步实现能力的扩展和增强。这些数据集将涵盖更多的编程语言、框架和库,以及更多样化的编程场景和问题,从而使 WaveCoder 能够更好地理解和适应不同的编程需求。
WaveCoder 解锁了编程领域的新潜能,也开启了代码智能的新篇章。通过提供更加智能的编程辅助,WaveCoder 将可以在有效提高开发者工作效率的同时,激发开发者的创造力,帮助他们构建更加创新、复杂的软件系统。微软亚洲研究院的研究员们将不断探索新的算法和技术,为编程语言处理技术的探索和创新持续贡献力量。