When data mining large datasets, it’s usually difficult to achieve both efficiency and accuracy. If you search efficiently, accuracy is lost; if you require accuracy, it’s hard to be efficient. But through the development of an elegant and remarkably simple algorithm, professor Jae-Gil Lee and Ph.D. student Hwanjun Song, of the Graduate School of Knowledge Service Engineering at KAIST in South Korea, have solved for both at one time. Their results, presented at KDD 2017 (a leading data mining conference that accepts only 17.5 percent of all papers submitted) were made possible by a Microsoft Azure for Research grant.
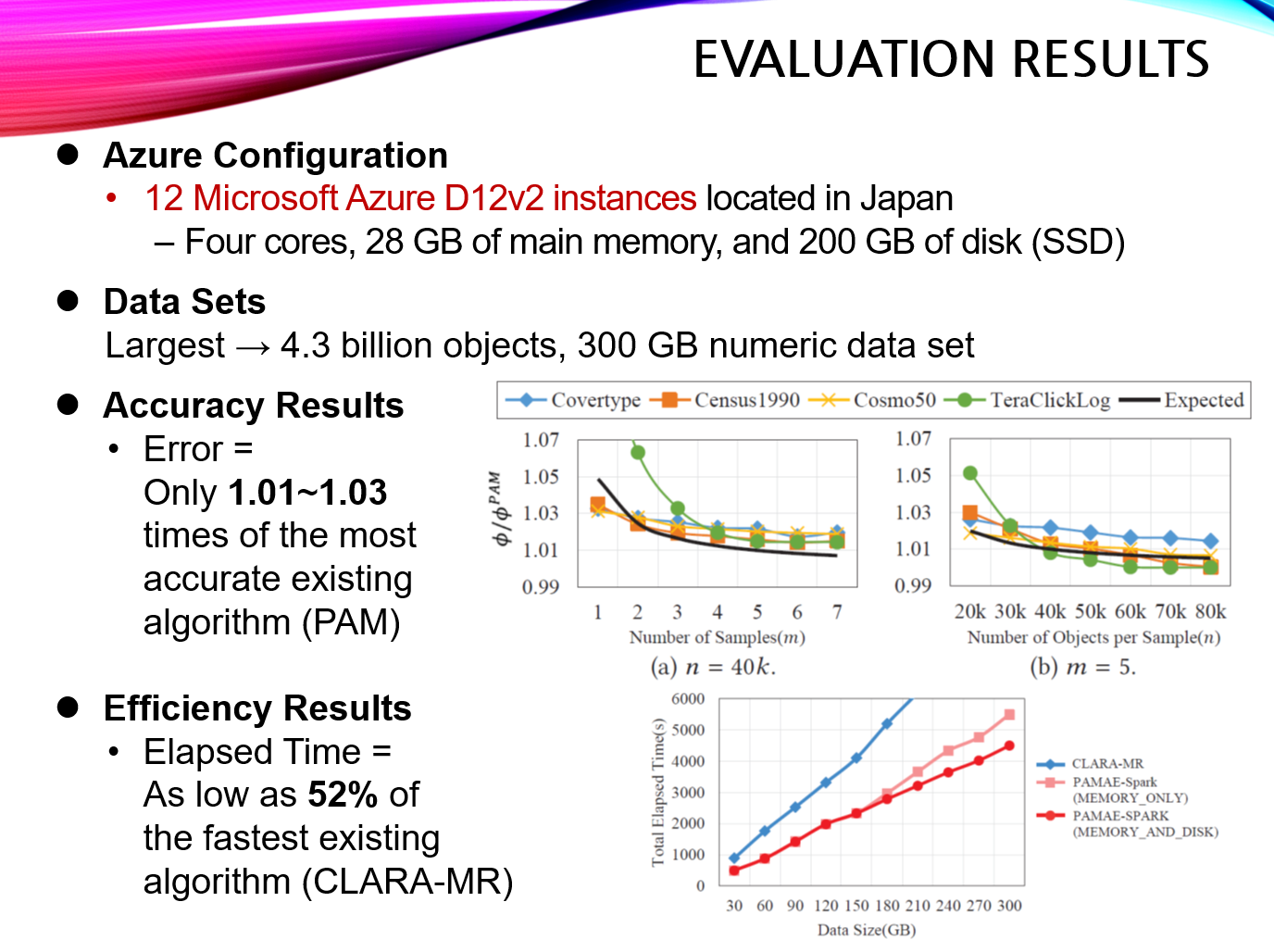
The research group conducted its experiments on 12 Microsoft Azure D12v2 instances located in Japan. The university couldn’t afford to purchase and maintain a cluster of its own high-performance servers; with the grant, Professor Lee’s team was able to run its experiments and achieve these impressive results.
Reducing computational costs through a new approach to the “k-medoids” algorithm
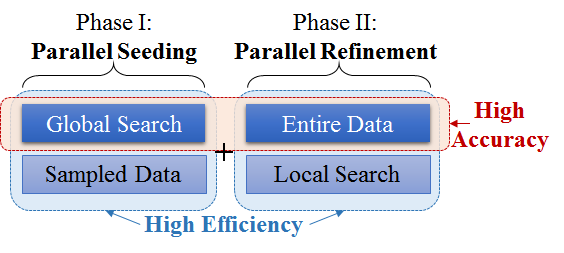
The k-medoids algorithm is one of the best-known clustering algorithms, with many accuracy advantages. The problem with it is that the current best practice algorithm in k-medoids, Partitional Around Medoids (PAM), has high computational complexity, such that major distributed machine learning platforms don’t support it. PAM runs its clustering algorithm on the entire dataset, which impacts efficiency. Professor Lee’s team, instead, found a way to run k-medoids in two separate steps: parallel seeding and parallel refinement. This requires less computational intensity, while maintaining the accuracy inherent in the k-medoids approach.
Professor Lee’s approach had error rates only 1.01-1.03 times of PAM, the most accurate existing algorithm. Yet it was almost twice as fast, with the elapsed time to a solution as low as 52 percent of the fastest existing algorithm. The new algorithm has thus achieved the holy grail of both high accuracy and high efficiency for big data analytics applications.
The source code of the algorithm is available at GitHub (https://github.com/jaegil/k-Medoid (opens in new tab)).