

“Universal few-Shot learner for dense prediction tasks” named ICLR 2023 Outstanding Paper
By Chong Luo, Principal Researcher
Dense prediction tasks constitute a fundamental type of computer vision problems, where the goal is to learn a mapping from an input image to a pixel-wise annotated label. Some examples of dense prediction tasks include semantic segmentation, depth estimation, edge detection, and key point detection. As supervised methods suffer from high pixel-wise labeling cost, developing a few-shot learning solution that can learn a task using a few number of labeled images is an important undertaking that has been a point of focus in recent years.
However, existing few-shot learning methods for computer vision have all been created to solve a restricted set of tasks, such as classification, object detection, or semantic segmentation. As a result, they often exploit prior knowledge and assumptions specific to these tasks in designing the model architecture and the training procedure. Researchers from MSR Asia and KAIST want to explore a key problem here: can there exist a few-shot learning solution that can universally learn arbitrary dense prediction tasks using a few (e.g., ten) labeled images?
In our setup, we consider any arbitrary task T that can be expressed as follows:

Where H and W represent the height and width of the input image respectively. C_T denotes the number of output channels. Different dense prediction tasks may involve different numbers of output channels and different attributes, such as multi-channel binary output for semantic segmentation tasks and single-channel continuous value output for depth estimation tasks. Our goal is to build a universal few-shot learner F that, for any such task T, can produce predictions Y ̂^q for an unseen image (query) X^q given a few labeled examples (support set) S_Τ:
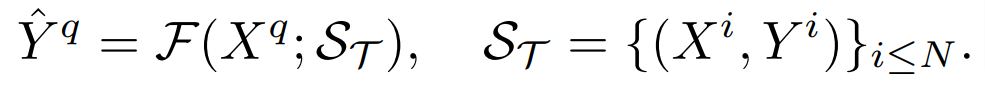
This universal few-shot learner for arbitrary dense prediction tasks must meet the following criteria.
- First, the learner must have a unified architecture that can handle arbitrary tasks by design and share most of the parameters across tasks so that it can acquire generalizable knowledge for few-shot learning of arbitrary unseen tasks.
- Second, the learner should be able to flexibly adapt its prediction mechanism to solve diverse tasks of unseen semantics, while being efficient enough to prevent overfitting.
Researchers from MSR Asia and KAIST have designed and implemented a few-shot learner called “visual token matching,” or VTM for short, which can be used for any dense prediction task. VTM is the first few-shot learner that can adapt to arbitrary dense prediction tasks. It not only provides a new solution for dense prediction tasks in the computer vision field but also introduces a new way of thinking for few-shot learning methods. This work received the ICLR 2023 Outstanding Paper Award.
Paper:Universal Few-shot Learning of Dense Prediction Tasks with Visual Token Matching
Link:https://arxiv.org/abs/2303.14969 (opens in new tab)
Our approach is inspired by the cognitive process of analogical reasoning, which allows humans to quickly understand the relationship between input and output based on similarities drawn from a few examples of a new task (i.e., assigning similar outputs to similar inputs. In VTM, we implement analogy-making for dense predictions as patch-level non-parametric matching, where the model learns similarities in image patches that captures the similarity in label patches.
Given a few labeled examples for a new task, VTM first modifies its understanding of the similarities, then predicts the labels of an unseen image by combining the label patches of the examples based on image patch similarity. Despite its simplicity, this model carries a unified architecture for arbitrary dense prediction tasks, since the matching algorithm encapsulates all tasks and label structures (e.g., continuous or discrete). Also, we introduce only a small number of task-specific parameters, which makes our model robust to overfitting and keeps it flexible.

Figure 1 illustrates our model. Our model has a hierarchical encoder-decoder architecture that implements patch-level non-parametric matching in multiple hierarchies. It primarily contains four components: image encoder f_Τ, label encoder g, label decoder h, and the matching module. Given the query image and the support set, the image encoder first extracts patch-level embeddings (tokens) of each query and support image independently. The label encoder similarly extracts tokens of each support label. Given the tokens at each hierarchy, the matching module performs non-parametric matching to infer the tokens of the query label, from which the label decoder forms the raw query label.
VTM is a meta-learning method. We trained our model on a labeled dataset D_train of training tasks T_train following the standard episodic meta-learning protocol. At each episode of task T, we sampled two labeled sets S_T, Q_T from D_train. Then we trained the model to predict labels in Q_T using S_T as a support set. We repeated the episodes with various dense prediction tasks in D_train so that the model could learn general knowledge of few-shot learning. After training on D_train, the model was few-shot evaluated on novel tasks T_test given a support setS_(T_test ).
In order to simulate the few-shot learning of unseen dense prediction tasks, researchers constructed a variant of the Taskonomy dataset. Taskonomy contains indoor images with various annotations, and from these, researchers chose ten dense prediction tasks of diverse semantics and output dimensions. These ten tasks were partitioned to construct a five-fold split, in each of which two tasks were used for few-shot evaluation (T_test), and the remaining eight were used for training (T_train). To perform evaluation on tasks of novel semantics, researchers carefully constructed the partition such that tasks for training and test were sufficiently different from each other, for example, by grouping edge tasks (TE, OE) together as test tasks.
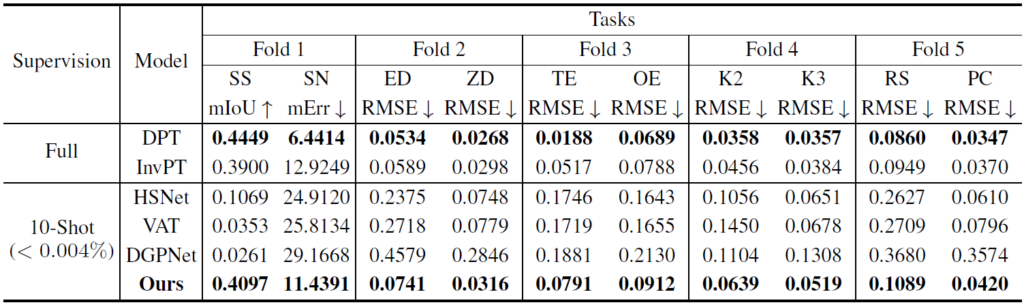
Researchers compared VTM (our model) with two other types of learning approaches. The first type consisted of fully supervised baselines. Two state-of-the-art baselines in supervised learning and multi-task learning of general dense prediction tasks—DPT and InvPT—were considered, where DPT was trained on each single task independently, and InvPT was trained jointly on all tasks. The other type consisted of few-shot learning baselines. As there were no prior few-shot methods developed for universal dense prediction tasks, researchers adapted state-of-the-art few-shot segmentation methods, DGPNet, HSNet, and VAT, to their setup.
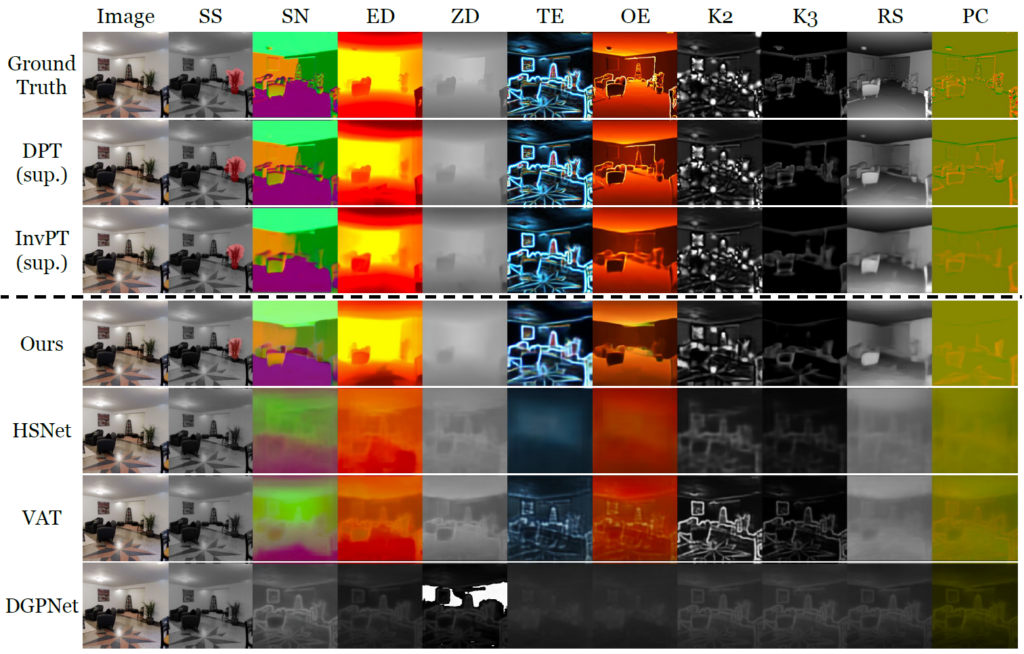
Table 1 shows the 10-shot performance of the VTM model and the baselines on ten dense prediction tasks. VTM outperforms all few-shot baselines by a large margin and is competitive with supervised baselines on many tasks. Figure 2 shows a qualitative comparison where the few-shot baselines catastrophically underfit to novel tasks while VTM successfully learns all tasks. Experimental results show that VTM is performing well while only using ten labeled examples, which account for less than 0.004% of the full training set. Already, its performance is comparable or superior to supervised methods on many tasks using additional data (0.1% of the full training set).
Although the underlying idea of VTM is very simple, it has a unified structure that can be used for any dense prediction task, since the matching algorithm essentially includes all tasks and label structures (such as continuous or discrete). In addition, VTM only introduces a small number of task-specific parameters to avoid overfitting and achieve flexibility. Moving forward, the researchers aim to further explore the impact of task type, data quantity, and data distribution on the model’s generalization performance during the pre-training process. The ultimate objective is to build a truly universal few-shot learner that can effectively adapt to a wide range of tasks and data domains with minimal data.