

Twelve selected papers of AAAI 2022: From concept drift to online influence maximization
AAAI is one of the top academic conferences in the field of Artificial Intelligence and is hosted by the Association for the Advance of Artificial Intelligence. This year’s AAAI conference was held from February 22 to March 1. More than 10 papers from Microsoft Research Asia have been selected, and they cover many fields in Artificial Intelligence, including concept drift, graphic layout generation, fake news detection, video object segmentation, cross-lingual language model pre-training, text summarization, attention mechanism, continuous-depth neural networks, domain generalization, online influence maximization and so on.
DDG-DA: Data Distribution Generation for Predictable Concept Drift Adaptation

Paper Link:https://arxiv.org/abs/2201.04038 (opens in new tab)
Code Link:https://github.com/microsoft/qlib/tree/main/examples/benchmarks_dynamic/DDG-DA (opens in new tab)
In time-series data, the data distribution often changes over time due to instability of the environment, which is often hard to predict. This phenomenon is called “concept drift,” and it negatively affects the performance of forecasting models trained on historical data.
To address this issue, researchers from previous work sought to detect whether concept drift has already occurred and then adapted the forecasting models to the most recent data distribution. However, in many practical scenarios, the changes of the environment form predictable patterns (a.k.a. Predictable Concept Drift), which makes it possible to predict future concept drift instead of just adapting the model to the most recent data distribution. This paper proposes a new method, DDG-DA, to predict future data distribution and to use that distribution in generating a new training dataset to learn the forecasting model in order to adapt to concept drift, ultimately improving forecasting model performance.

Figure 1: DDG-DA learns to generate new training dataset through weighted resampling to minimize the distribution gap between historical training data and future data.
Specifically, as shown in Figure 1, time series data are collected over time, and algorithms use the collected historical data to learn or adjust the forecasting models for prediction in the future. However, there is a distribution gap between the historical data and the future data, which negatively affects the predictive performance of the learned forecasting models. DDG-DA aims to narrow this distribution gap. It resamples historical data with weights to generate a new training dataset, which would serve as the prediction for future data distribution. In addition, researchers designed a distribution distance function equivalent to KL-divergence to calculate the distance between the predicted data distribution and future data distribution. The distance function in this work is differentiable, so it can be used to efficiently learn the parameters of DDG-DA to minimize the error of the predicted data distribution. In the learning stage, DDG-DA first learns how to resample data on historical time series data, and then in the prediction stage, it periodically generates training datasets by resampling historical data. The model trained on the datasets generated by DDG-DA would better accommodate future data distribution/concept drift.
As shown in Table 1, experiments were performed on three real-world prediction tasks and multiple models and obtained significant improvements over previous methods.

Table 1: Comparison of DDG-DA with other methods in different scenarios
Coarse-to-Fine Generative Modeling for Graphic Layouts

Paper Link:
Although graphic layout generation has recently attracted growing attention, it is still challenging to synthesize realistic and diverse layouts due to complicated element relationships and varied element arrangements. This work seeks to improve the performance of layout generation by incorporating into the generation process the concept of regions, which consist of a smaller number of elements and appear like a simple layout. Specifically, Variational Autoencoder (VAE) is leveraged as the overall architecture and decompose the decoding process into two stages. The first stage predicts representations for regions, and the second stage fills in the detailed position for each element within the region based on the predicted representations. Compared to prior studies that have merely abstracted the layout into a list of elements and generated all the element positions in one go, this novel approach has at least two advantages. First, through the two-stage decoding, this approach decouples the complex layout generation task into several simple layout generation tasks, which reduces the problem’s difficulty. Second, the predicted regions can help the model roughly know what the graphic layout looks like and serve as a global context to improve the generation of detailed element positions.
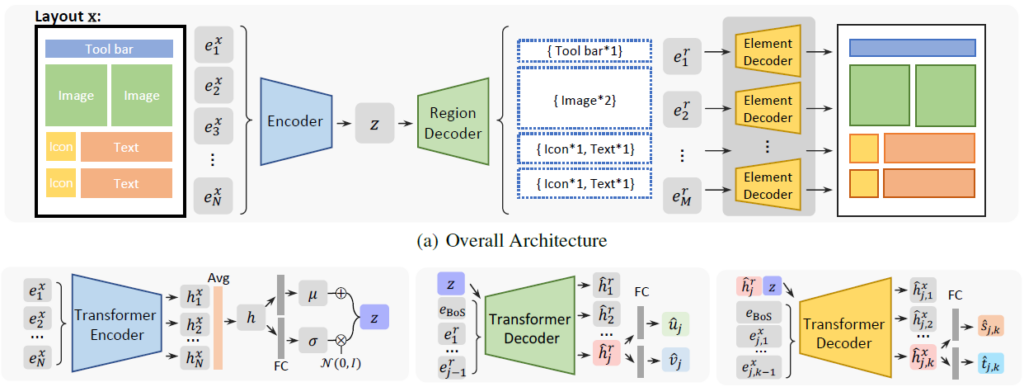
Figure 2: Model Architecture
Qualitative and quantitative experiments demonstrate that this novel approach significantly outperforms existing methods, especially in complex graphic layouts. Table 2 shows FID scores for different models, and Figure 2 compares the model’s performance on layouts with a different number of elements. Please refer to the original paper for more experimental results.

Table 2:FID scores for different models

Figure 3:Quantitative comparisons when the layouts are grouped by the number of elements
Towards Fine-Grained Reasoning for Fake News Detection

Paper Link: https://arxiv.org/abs/2110.15064 (opens in new tab)
Recently, neural models have been proposed to detect fake news in a data-driven manner. These works have shown the promise of leveraging big data for fake news detection. However, works that approach the task from the perspective of reasoning are still lacking.
According to literature on psychology, reasoning is the capability to consciously apply logic towards truth-seeking and is typically considered a distinguishing capacity of humans. Such an ability is essential to improving the explainability and accuracy of fake news detection. For example, in Figure 4, if the model learns to logically connect subtle clues such as “property,” “hate,” and the overlapping user “Alice” by following the reasoning process of humans, significant improvement may be achieved in both explainability and detection accuracy.

Figure 4: Fake news detection usually requires fine-grained reasoning abilities. Although the four groups of evidence are semantically dissimilar, humans can logically connect them using subtle clues, such as the word “property” in the example given here, which leads to a much more confident conclusion about the article.
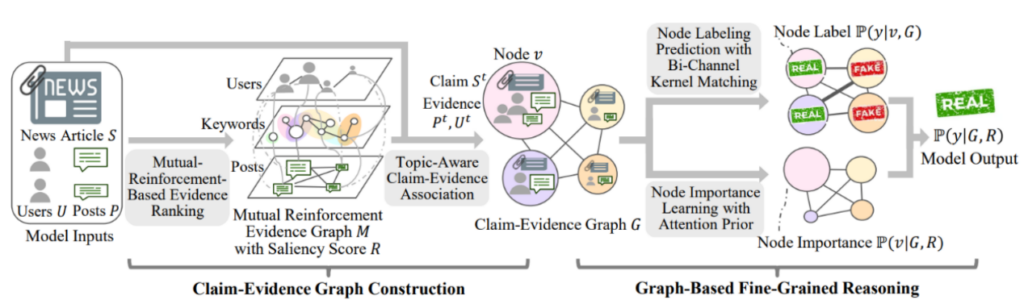
Figure 5: The proposed FinerFact framework for fake news detection
In this paper, researchers propose a fine-grained reasoning framework for fake news detection (FinerFact) by following the human information-processing model. FinerFact detects fake news by better reflecting the logical processes of human thinking, which enhances interpretability and provides a foundation for incorporating human knowledge. It also introduces a mutual-reinforcement-based method for evidence ranking, which enables us to better incorporate prior human knowledge on types of evidence that are most important. Finally, FinerFact incorporates a prior-aware bi-channel kernel graph network to achieve fine-grained reasoning by modeling different types of subtle clues. This new framework improves accuracy and provides explanations about the subtle clues identified, the most important claim-evidence groups, and the individual prediction scores given by each group.
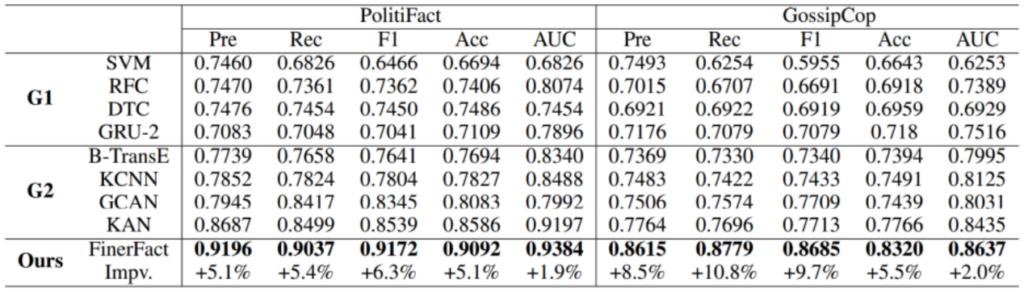
Table 3: Performance of FinerFact on two benchmark datasets: PolitiFact and GossipCop
Extensive experiments show that FinerFact outperforms the state-of-the-art methods and demonstrates the explainability of this novel approach.
Researchers conducted a case study to show that FinerFact can enable humans to understand most parts of the reasoning workflow. It is able to successfully identify that the news is fake, and to provide a detailed explanation of the salient evidence, subtle clues, and the prediction scores for each viewpoint.
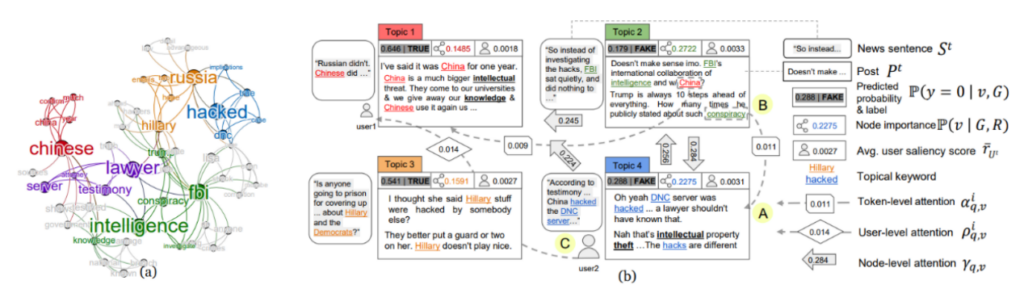
Figure 6: Visualizing the reasoning process of FinerFact. (a) the keyword layer of the mutual reinforcement graph M, with saliency R indicated by the font size; (b) fine-grained reasoning over the claim-evidence graph G. Each color represents a topic.
Hybrid Instance-aware Temporal Fusion for Online Video Instance Segmentation

Paper link: https://arxiv.org/abs/2112.01695 (opens in new tab)
Transformer-based image segmentation methods have recently achieved notable success over previous solutions, but in the video domain, effectively modeling temporal context with the attention of object instances across frames remains an open problem. To address this, this paper proposes an online video instance segmentation framework with a novel instance-aware temporal fusion method. Researchers first leverage the representation in MaX-DeepLab, a latent code in the global context (instance code) and CNN feature maps to represent instance- and pixel-level features. Based on the representation, researchers introduce a cropping-free temporal fusion approach to model the temporal consistency between video frames. Specifically, researchers encode global instance-specific information in the instance code and build up inter-frame contextual fusion with hybrid attentions between the instance codes and CNN feature maps. Inter-frame consistency between the instance codes is further enforced with order constraints. By leveraging the learned hybrid temporal consistency, researchers are able to directly retrieve and maintain instance identities across frames, eliminating the complicated frame-wise instance matching in prior methods. As shown in Figure 7, the attention responses on different references are consistent at both the pixel and instance level.
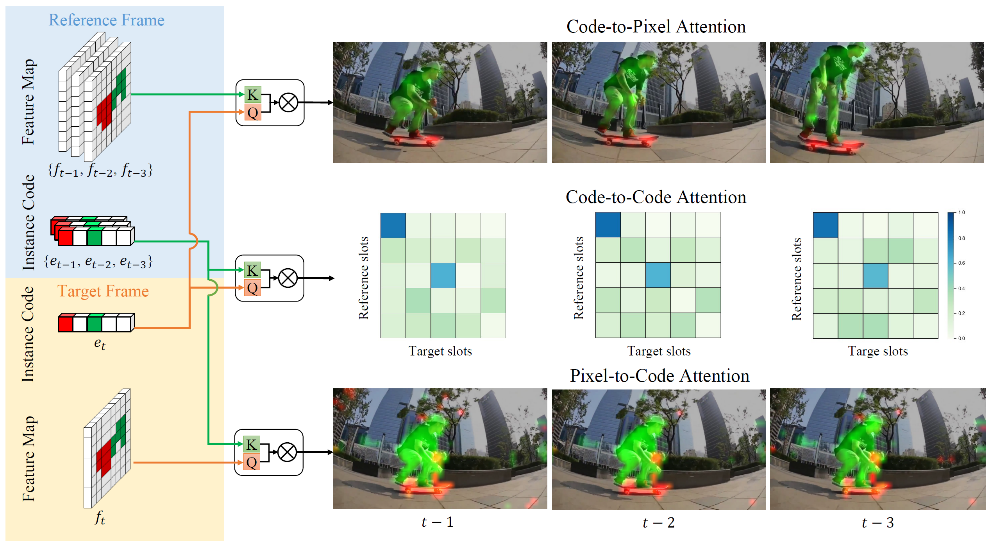
Figure 7: Visualization of attention maps in inter-frame attention layers
Figure 8 illustrates the overview of the proposed framework. Researchers enforce the temporal consistency in VIS by introducing hybrid frame-to-frame communications. Two main components are highlighted, i.e., intra-frame attention for linking the current instance code and feature maps, and inter-frame attention for fusing hybrid (pixel- and instance-level) temporal information in adjacent frames. The first N intra-frame attention layers are integrated into the convolutional backbone followed by M alternate attention layers. The final instance codes are constrained to be consistent across frames.
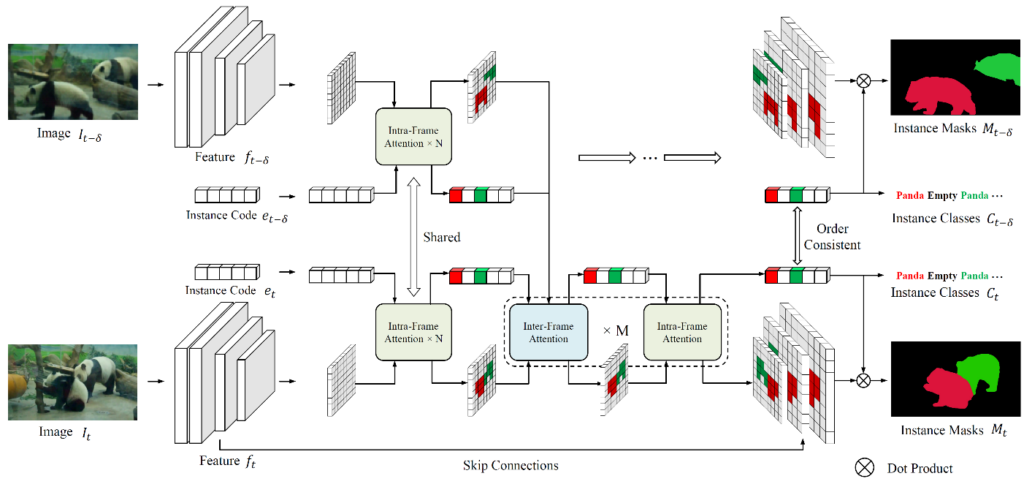
Figure 8: Overview of the proposed framework
Extensive experiments have been conducted on popular VIS datasets, i.e. Youtube-VIS-19/21. This model has achieved the best performance among all online VIS methods, as shown in Table 4.
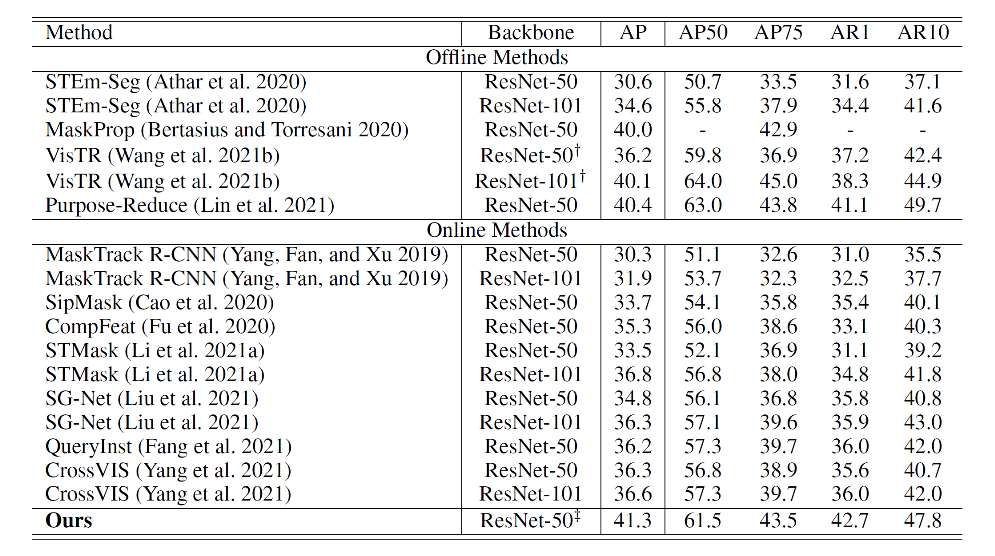
Table 4: Comparison to state-of-the-art video instance segmentation on Youtube-VIS-2019 val set
Reliable Propagation-Correction Modulation for Video Object Segmentation

Paper link: https://arxiv.org/abs/2112.02853 (opens in new tab)
Error propagation is a general but crucial problem in online semi-supervised video object segmentation. This work aims to suppress error propagation through a correction mechanism with high reliability. The key insight is to disentangle the correction from the conventional mask propagation process with reliable cues. Researchers introduce two modulators for propagation and correction to separately perform channel-wise re-calibration on the target frame embeddings according to local temporal correlations and reliable references respectively. Specifically, researchers assemble the modulators with a cascaded propagation-correction scheme. This avoids overriding the effects of the reliable correction modulator by the propagation modulator. Although the reference frame with the ground truth label provides reliable cues, it can be very different from the target frame and can introduce uncertain or incomplete correlations (as shown in Figure 10, where the kangaroo disappears in later frames and the visible part of the person changes significantly). Researchers augment the reference cues by supplementing reliable feature patches to a maintained pool, thus offering more comprehensive and expressive object representations to the modulators. In addition, a reliability filter is designed to retrieve reliable patches and pass them in subsequent frames. The overview of the proposed framework is illustrated in Figure 9.
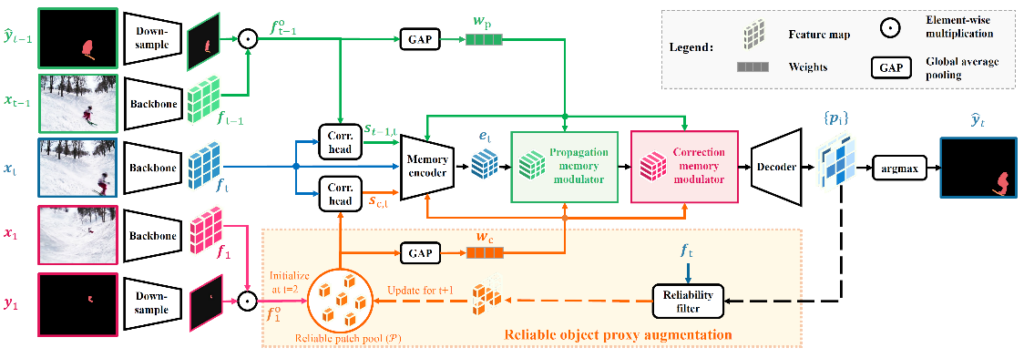
Figure 9: Overview of the proposed framework

Figure 10: The new model can suppress error propagation in VOS with a reliable propagation-correction mechanism.
This novel model has achieved state-of-the-art performance on the benchmarks YouTube-VOS18/19 and DAVIS17-Val/Test. Extensive experiments demonstrate that the correction mechanism provides considerable performance gain by fully utilizing reliable guidance, as shown in Table 5. Figure 10 (a) also shows that this model has the least performance decay as time increases.
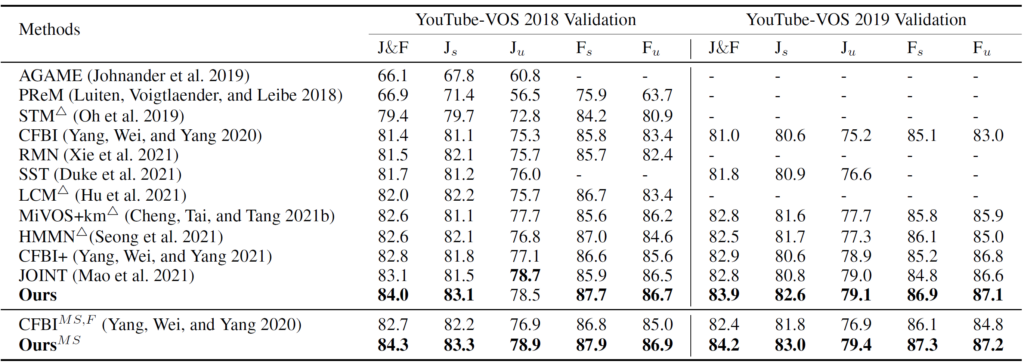
Table 5: Quantitative comparisons on YouTube-VOS
XLM-K: Improving Cross-Lingual Language Model Pre-Training with Multilingual Knowledge

Paper Link: https://arxiv.org/abs/2109.12573 (opens in new tab)
Cross-lingual pre-trained models target the ability to train on one language and then test directly on other languages. Previous cross-lingual research has focused on learning from monolingual data and bilingual data. This paper proposes to incorporate multilingual knowledge in pre-training. In a multilingual knowledge base, one entity corresponds to multiple names and descriptions in different languages, which can provide new cross-lingual supervision and help to embed the knowledge base into the pre-trained model. Figure 11 is an example of a multilingual knowledge base.
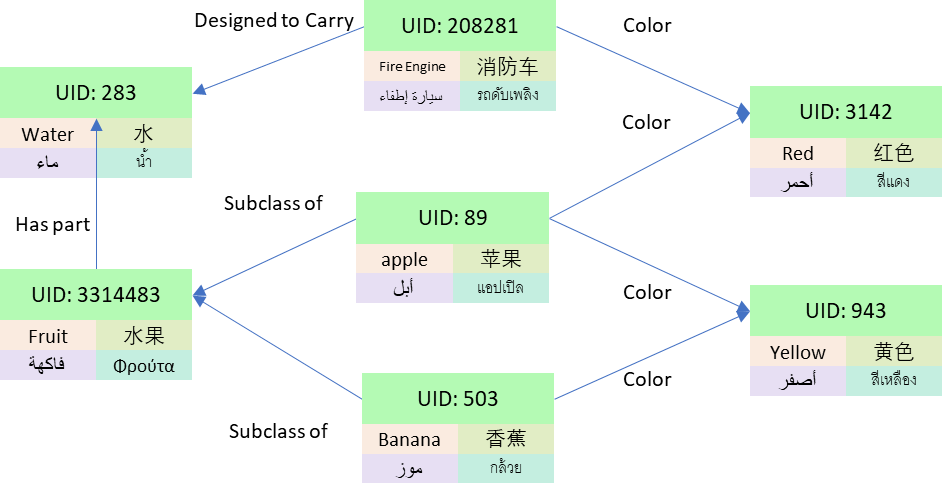
Figure 11: Multilingual knowledge base
In this work, researchers propose two knowledge tasks, the Masked Entity Prediction Task and the Object Entailment Task. These two tasks can improve cross-lingual alignment and help the pre-trained model memorize knowledge. For the Masked Entity Prediction Task, the input is a paragraph with masked words. The model needs to predict the masked word and the entity it should be linked to. For example, if “apple” is the word that has been masked, the model needs to predict whether it should be linked to the fruit or Apple Corporation. In Object Entailment, the inputs are the description of the subject and the relation between the subject and the object. The model needs to predict the object. For example, when the subject is the description of “apple,” and the relation is “subclass of,” the model should then predict the object “fruit,” since an apple is in the subclass of a fruit. Both the input and output of these two tasks can be in different languages, which can help to improve cross-lingual ability.

Figure 12: Pre-training tasks: Masked Entity Prediction Task and Object Entailment Task
The XLM-K model was tested on three tasks MLQA, NER and XNLI. XLM-K achieved significant improvements over other models on knowledge related tasks such as MLQA and NER and achieved comparable performance on plain text classification such as XNLI.

Table 6: Performance on cross-lingual tasks
Finally, researchers tested XLM-K’s ability to memorize the knowledge base through knowledge probing tasks. These knowledge probing tasks transform knowledge triplets from the knowledge base into a text with a mask. For example, it transforms

Table 7: Knowledge probing results
Sequence Level Contrastive Learning for Text Summarization

Paper Link : https://arxiv.org/abs/2109.03481 (opens in new tab)
Text Summarization aims to rewrite a long document into a shorter form while preserving the important parts of its content. Text summarization methods are usually categorized into extractive summarization and abstractive summarization. Specifically, extractive summarization extracts the most important sentences from a document as its summary, while abstractive summarization rewrites a document into a coherent and concise summary, which requires word deletion, paraphrasing, etc.
Most recent abstractive summarization models have been built on the sequence-to-sequence learning framework. The Encoder encodes the long document and the Decoder generates the desired summary based on the encoding. During training, NLL (Negative Log Likelihood) is used as the objective function.
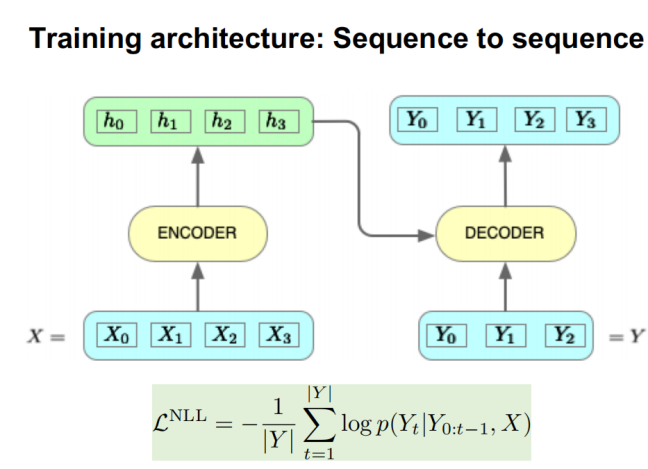
Figure 13: The NLL loss used in Sequence-to-Sequence model training
However, it is observed that NLL does not adequately capture an important property of the text summarization task, which is that while the document and its summary are different in length, they need to share the same message. To better address this during training, this paper proposes SeqCo (Sequence-level Contrastive Learning), which maps the document and its summary onto the same vector space and increases the similarity between the document sequence and the summary sequence.
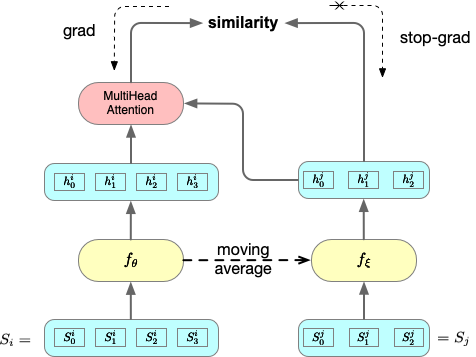
Figure 14: The training process for the Sequence-level Contrastive Learning method
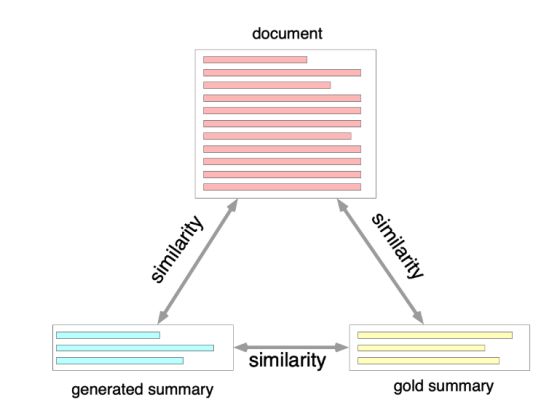
Figure 15: During training, researchers increased the similarities between the original document, the target summary, and the generated summary.
To increase the diversity of training examples, researchers utilized the model generated summaries in model training. The training process, while optimizing NLL, also increases the similarities between the original document, the target summary, and the model generated summaries.
Experiments have shown that SeqCo has significant improvements over text summarization models that only use NLL loss.
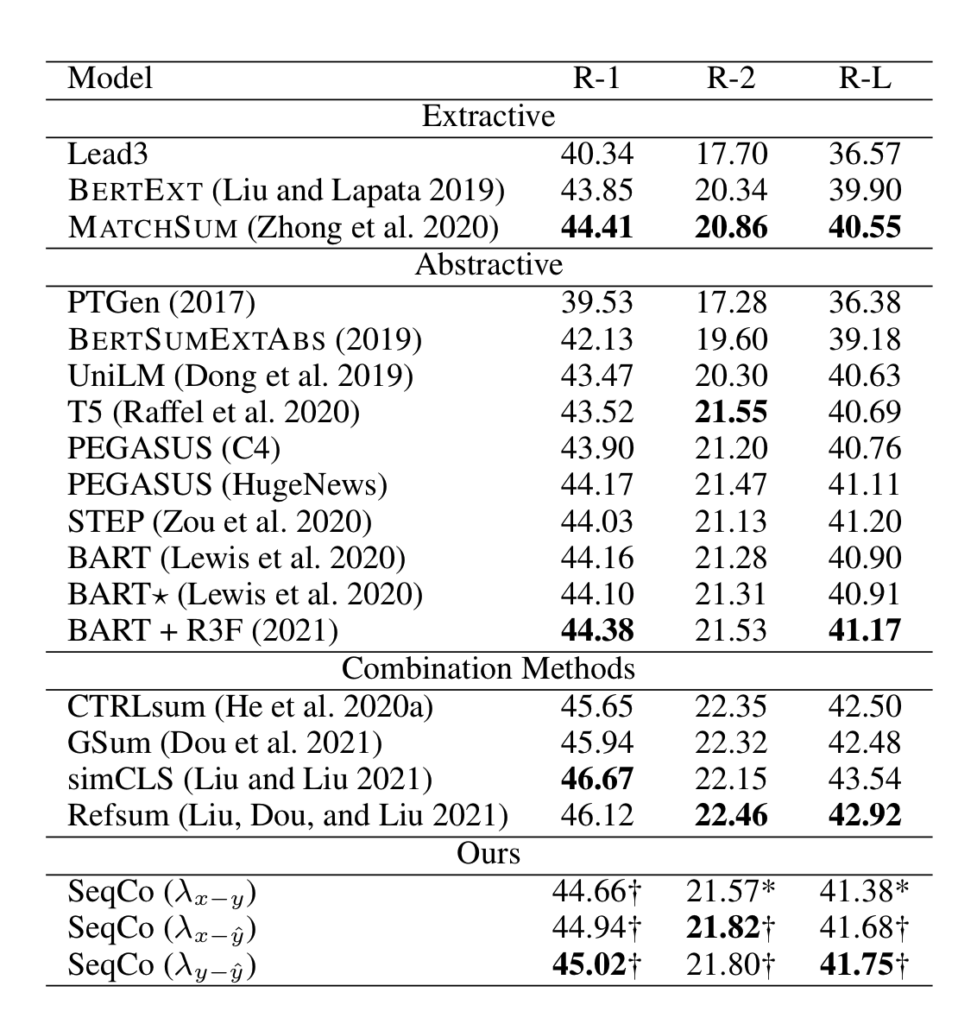
Table 8: Results obtained on the CNN/DM dataset
Researchers also compared models with different contrastive pairs (x-y: original document and target summary; x-y^: original document and generated summary; y-y^: target summary and model generated summary), and all model variants significantly outperformed the baseline model (i.e., BART).

Table 9: Results of different contrastive pairs on CNN/DM
Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?

Paper link:https://arxiv.org/pdf/2109.05422.pdf (opens in new tab)
Code link:https://github.com/microsoft/SPACH (opens in new tab)
Transformers have sprung up in the field of computer vision, and self-attention is considered a key component for its success, as it can exploit global dependency dynamically by considering the relationship between every two input tokens.
However, researchers are challenging the complete disposal of locality bias since locality is always valid in natural images. Furthermore, self-attention carries quadratic computational complexity and is not friendly to high-resolution input or pyramid structures. These are considered drawbacks of Vision Transformers, since high-resolution input and pyramid structures are widely acknowledged to improve image recognition accuracy.
Researchers are also challenging the need for self-attention. For example, MLP-Mixer recognizes the importance of modeling global dependencies, but it adopts an MLP block instead of a self-attention module. Consequently, there is an accuracy gap between MLP-Mixer and SOTA models. But is it possible for an attention-free network to achieve SOTA performance on images?
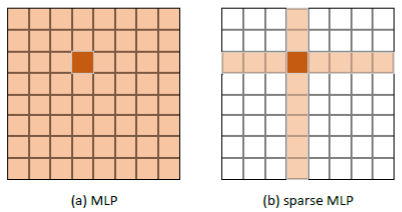
Figure 16: Illustration of the sMLP block
In this paper, researchers design an attention-free network. It adopts a similar architecture as MLP-Mixer, with the only difference being the token mixing module. In each token mixing module, depth-wise convolution is adopted to take advantage of the locality bias, and a modified MLP is used to model global dependencies. Specifically, researchers propose the sparse-MLP (sMLP) module (as shown in Figure 16), which is featured by axial global dependency modeling and weight sharing. sMLP significantly reduces the computational complexity and allows us to adopt a pyramid structure for multi-stage processing. As a result, this method can achieve top image recognition performance on par with Swin Transformer at an even smaller model size.
The results of this method support the conclusion that self-attention might not be the key factor for the success of Transformer. There are other factors researchers need to pay attention to when designing a vision model, such as locality bias and the multi-stage pyramid structure.
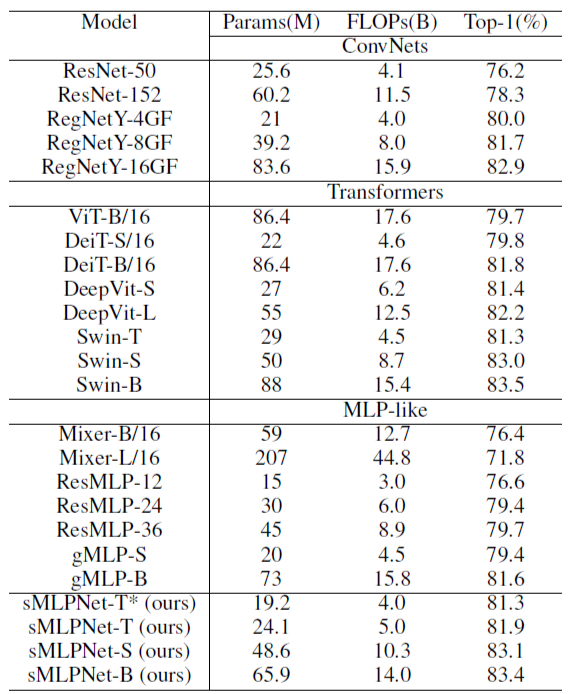
Table 10: Comparison with state-of-the-art methods
When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanism

Paper Link:https://arxiv.org/abs/2201.10801 (opens in new tab)
Recently, Vision Transformer (ViT) and its variants have been attracting increasing attention in the research community. Despite the impressive performance of recent ViT variants, it is still not yet clear what makes ViT good for visual recognition tasks. Some conventional wisdom leans towards crediting the success to the attention mechanism, since it has two significant strengths: dynamic weight and global scope. However, existing work proves that these two properties are not the key to success. For example, Swin-Transformer removes global dependencies by a local attention mechanism, and MLP-Mixer substitutes the dynamic aggregation weight with a fixed linear projection. In this work, researchers further simplify the attention layer into an extremely simple case: NO global scope, NO dynamics, NO parameters, and NO arithmetic calculations. Researchers want to find out whether ViT can retain good performance under this extreme case.

Figure 17: Illustration of the building block
As depicted in Figure 17, the attention module was replaced with the shift operation. Given an input feature, it would shift a small portion of the channels along four spatial directions, namely left, right, top, and down. In such a way, the information of neighboring features is explicitly mingled by the shifted channels. Interestingly, this simple architecture can also work well for mainstream visual recognition tasks. As shown in Table 11, the performances of the shifted-version ViT are on par with or even better than the strong Swin Transformer baseline. This shows that the attention mechanism is not the vital factor determining the success of ViT, which can be replaced even by an extremely simple shift operation. On the contrary, more attention should be paid to the other components in Transformer. In this work, researchers also conduct preliminary discussions in the hopes of inspiring the future research direction.
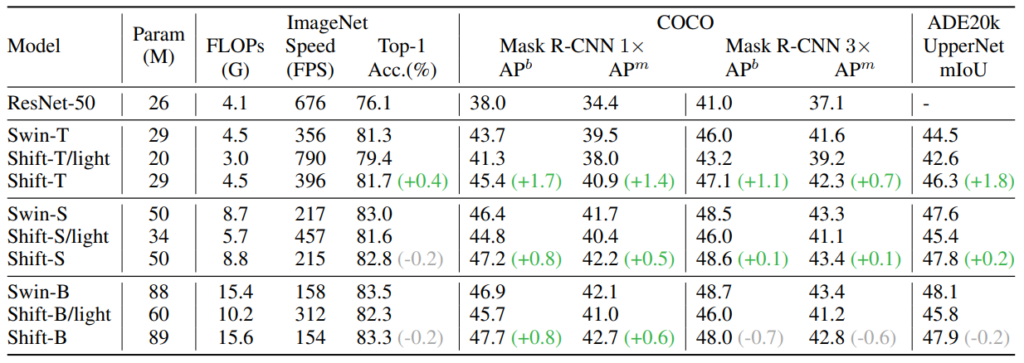
Table 11: Comparisons with the baseline Swin-Transformer
Neural Piecewise-Constant Delay Differential Equations

Paper Link:https://arxiv.org/abs/2201.00960 (opens in new tab)
Continuous-depth neural networks, such as the Neural Ordinary Differential Equations (NODEs), have aroused a great deal of interest from the machine learning and data science communities in recent years. There are many examples of work in this area, including data analytics on the time series with irregular sampling duration (Rubanova, Chen, and Duvenaud 2019; De Brouwer et al. 2019; Kidger et al. 2020), generation of continuous normalizing flow (Chen et al. 2018; Grathwohl et al. 2018; Finlay et al. 2020; Deng et al. 2020; Kelly et al. 2020), and representations of the point clouds (Yang et al. 2019; Rempe et al. 2020). It is worthwhile to mention that the framework of NODEs, in spite of its wide applicability, is not a universal approximator. It therefore cannot successfully learn representative maps such as the reflections, defined by g_1d:R→R$ with g_1d (1)=-1 and g_1d (-1)=1, due to the homeomorphism property of ODEs (Dupont, Doucet, and Teh 2019; Zhang et al. 202). To address this problem, several practical schemes, such as the Augmented NODEs (ANODEs) (Dupont, Doucet, and Teh 2019) and Neural Delay Differential Equations (NDDEs) (Zhu, Guo, and Lin 2021), have been suggested and implemented.
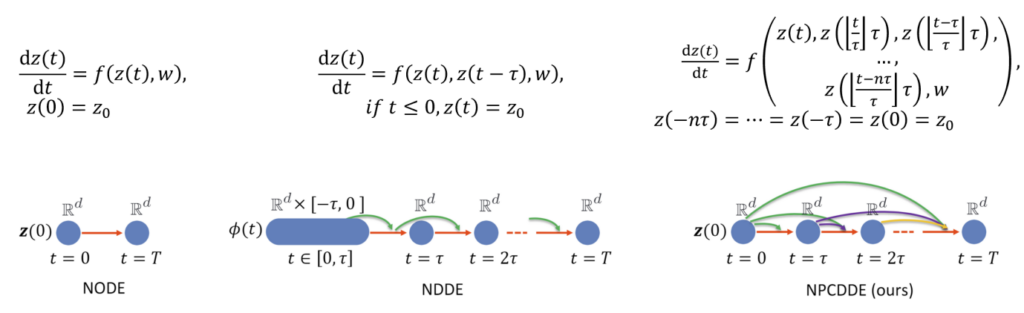
Figure 18:Sketches of different kinds of continuous-depth neural networks, including the NODEs, the NDDEs, and the newly proposed framework, the NPCDDEs.
This paper introduces a new type of continuous-depth neural network, called the Neural Piecewise-Constant Delay Differential Equations (NPCDDEs). With this, unlike with the recently proposed framework for the NDDEs, researchers transform the single delay into piecewise-constant delay(s). Through this transformation, the NPCDDEs, on one hand, inherit the strength of the universal approximating capability in NDDEs. On the other hand, they further promote modeling capability without augmenting the network dimension by leveraging the contributions of information from multiple previous time steps. In addition, researchers consider NPCDDEs with different parameters in different time periods called unshared NPCDDEs (UNPCDDEs), which are just like general feedforward neural networks, and note that ResNets and NODEs are special cases of UNPCDDEs. In the end, researchers demonstrate that the powerful nonlinear representation of NPCDDEs and UNPCDDEs outperforms current representative continuous-depth neural network models on the synthetic data produced by the one-dimensional piecewise-constant delay population dynamics and also on representative image datasets, i.e., MNIST, CIFAR10, and SVHN.
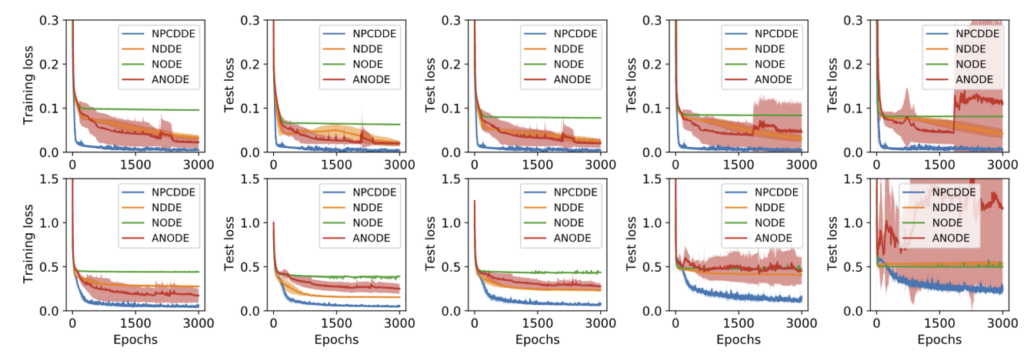
Figure 19:The respective training losses and test losses of the piecewise-constant delay population dynamics with the oscillation regime (top) and the chaos regime (bottom) by using the NPCDDEs, the NDDEs, the NODEs, and the ANODEs.
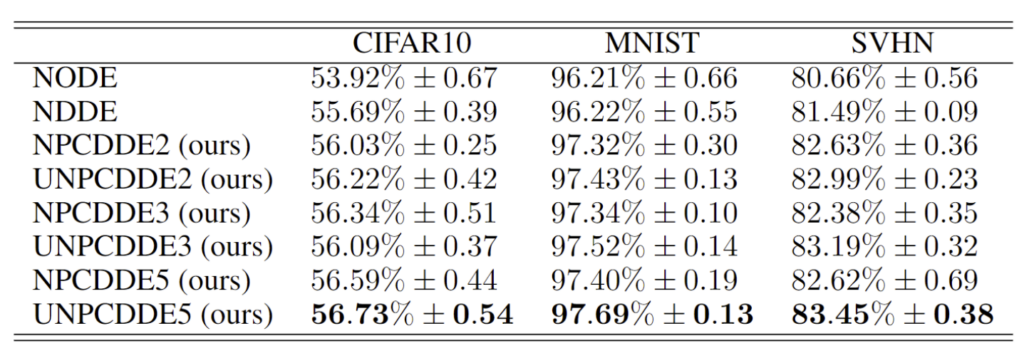
Table 12:Test accuracies with standard deviations over 5 realizations of different models on the image datasets.
All this suggests that integrating the elements of dynamical systems with different kinds of neural networks is indeed beneficial to creating and promoting the frameworks for deep learning using continuous-depth structures.
Invariant Information Bottleneck for Domain Generalization

Paper Link: https://arxiv.org/abs/2106.06333 (opens in new tab)
Domain Generalization refers to learning from different distributions to obtain a model with better generalization ability. Invariant risk minimization (IRM) is one of the more important algorithms in the field of generalization direction that seeks the invariance of feature-conditioned label distribution independent of labels. However, IRM also relies on pseudo-invariant features, and when geometric skews exist in data distribution, that is, when all the data have certain pseudo features that can be used for classification and the data volume is large (P(z_{sp} * y) > 0.5), the model will prefer to establish a short-cut classifier rather than considering the features in the data that are more widely existing and more consistent.
The researchers at Microsoft Research Asia believe the problem arises from an over-reliance on features, which results in pseudo-invariance and geometric-skews. Therefore, in this paper, the researchers propose a method of Information Bottleneck to regularize the dimension of features. They also propose the Invariant Information Bottleneck (IIB), which is a method that aims to use as little Information as possible from input data in feature representations. The researchers wrote the optimization goal of IRM in the form of mutual information, and combined with the mutual information optimization objective of the information bottleneck, the mutual information optimization objective of IIB could be derived as follows:
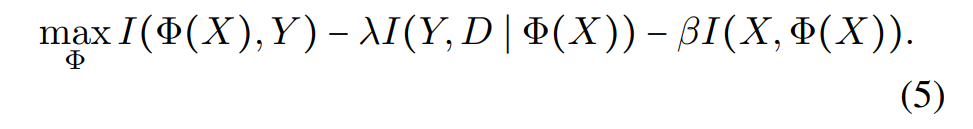
Furthermore, the researchers approach the above mutual information objective using variational inference under a neural network framework. The overall structure of IIB is as follows:
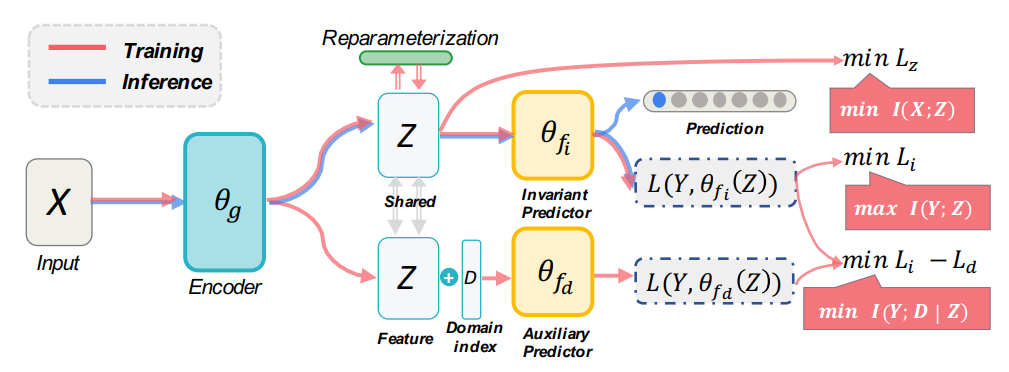
Figure 20: Overall structure of IIB
IIB performed well in the DomainBed dataset, outperforming the existing baseline method by 0.9%.
In general, IIB stems from IRM, where researchers add the information bottleneck (IB) constraint to the feature representation and integrate the optimization objectives of IRM and IB into the form of mutual information for variational inference. The quantitative experiment results show that IIB can resolve pseudo-invariance and geometer-skews with a significant improvement over IRM and can also perform better in real, large-scale data sets such as DomainBed.
Online Influence Maximization with Node-level Feedback Using Standard Offline Oracle

Paper Link:https://arxiv.org/abs/2109.06077 (opens in new tab)
In this paper, researchers study the online influence maximization problem. The learning agent interacts with a social network with unknown propagation characteristics in multiple rounds, where in each round, the agent needs to select a set of seed nodes for propagation, deploys these seeds, and observes the propagation process in the network as the feedback, and then learns propagation parameters to update its seed selection strategy. The goal is to minimize the cumulative regret of multiple rounds of interactions, which is defined as the cumulative difference between the influence spread of the optimal seed set and the influence spread of the selected seeds. There are two types of feedback: edge-level feedback and node-level feedback. The former can provide information on which edges a node is activated through, while the latter only provides information on which nodes are activated, and so the latter presents a more realistic but more challenging situation. For the independent cascade model, prior studies have only been on the edge-level feedback. Researchers apply the maximum likelihood method to design a node-level feedback algorithm that achieves near optimal regret bound. Moreover, this novel algorithm uses an efficient standard offline oracle for solving offline influence maximization problems, while prior work on handling similar situations have had to rely on an inefficient oracle that optimizes both the seed set and the propagation parameters within a certain range.